
Red Hat Blog
In our first post defending the pet container, we looked at the challenge of complexity facing modern software stacks and one way that containers address this challenge through aggregation. In essence, the Docker “wrapper” consolidates the next level of the stack, much like RPM did at the component level, but aggregation is just the beginning of what the project provides.
If we take a step back and look at the Docker project in context, there are four aspects that contribute to its exceptional popularity:
- it simplifies the way users interact with the kernel, for features we have come to call Linux containers;
- it's a tool and format for aggregate packaging of software stacks to be deployed into containers;
- it is a model for layering generations of changes on top of each other in a single inheritance model;
- it adds a transport for these aggregate packages.
These aspects of containers have triggered triggered a full paradigm shift in how we look at the operating system (OS), one driven by Red Hat and many other IT leaders contributing to the Docker project. The usual squabbles over positioning and control that come with such a shift notwithstanding, the future of the OS is defined by containerization.
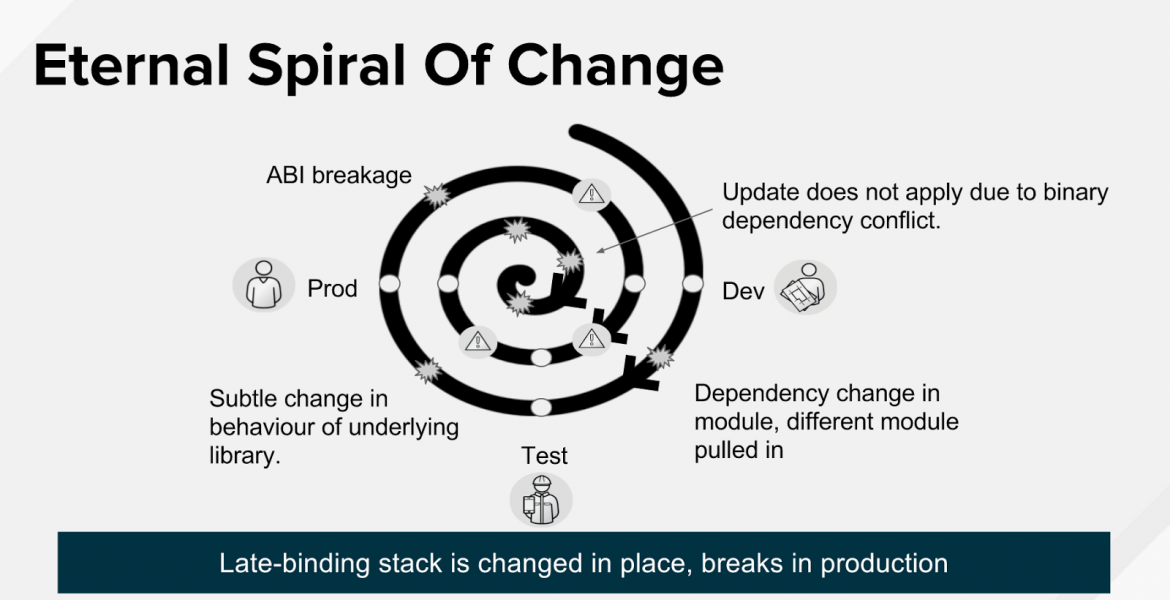
The Docker project’s model has advantages over the previous approaches to Linux containers, as we outlined previously, for several reasons. The combination of aggregate packaging, runtime isolation of containers, and a layering model is extremely powerful. This enables us to solve a number of the core issues of the the existing component level approach, particularly those that have been hurting the IT departments seeking to implement DevOps around more traditional application stacks. It helps break the eternal spiral of change that is the model of updating components in production.
From Red Hat’s perspective, we are building an entire strategy around this layered inheritance model, with products like OpenShift, Red Hat CloudForms, and the Container Development Kit (CDK) for the delivery of a full application lifecycle workflow encompassing everything from development and build scenarios to testing and production.
With all of this in mind, a best practice around Linux containers is clearly to *always* build your container using a build service, and to *never* run yum inside the instantiated production container, right?
That is, unless it isn't.
Even with the advantages that aggregate packaging offers, we should not forget the original use case: to build containers in a build service and use them as aggregate binary packaging to enable repeatable builds and predictable behavior - just like RPM on the individual component base.
But the dirty secret of containers is that it's not always the right way to approach your delivery process.
What if I am looking to simply have a traditional Linux host with multiple runtimes in parallel, without fundamentally changing my operational model? Containers in the Docker format do *not* imply automatically moving to immutable infrastructure and building everything into a container image through a build service.
So how does this impact the use cases for Linux containers? And how, exactly, does everything that we’ve talked about lead-in to a use case for pet containers? Stay tuned for the next post, we we’ll dig into where (and how) pet containers should play into the enterprise IT landscape.
About the author

Daniel Riek is responsible for driving the technology strategy and facilitating the adoption of Analytics, Machine Learning, and Artificial Intelligence across Red Hat. Focus areas are OpenShift / Kubernetes as a platform for AI, application of AI development and quality process, AI enhanced Operations, enablement for Intelligent Apps.