
Red Hat Blog
Der erste Schritt zum lösen von Performanceproblemen ist die Untersuchung des Problems. Ohne genaue Daten und die Fähigkeit diese zu Analysieren kann man sich nur auf Annahmen verlassen. Ein bekanntes Tool dafür ist Performance Co-Pilot (PCP). Dieser Artikel bietet eine Einführung in das Sammeln und Analysieren von Daten mit PCP auf Red Hat Enterprise Linux.
Was ist Performance Monitoring?
Es gibt mindestens zwei Arten von Monitoring:
-
Verfügbarkeits-Monitoring: sind das System oder der Service verfügbar?
-
Performance-Monitoring: was sind die aktuellen Daten des Systems, z.B. Load oder Netzwerkdurchsatz?
In diesem Artikel wird darauf eingegangen, wie einfach Performance Co-Pilot (PCP) benutzt werden kann, um alltägliche Probleme zu lösen. In einem späteren Artikel wird auf das Anpassen von Metriken für eigene Anwendungen eingegangen.
Warum PCP und nicht Tool XYZ?
Wie sich PCP im Vergleich zu verschiedenen anderen Tools verhält ist hier beschrieben. Ein Vergleich mit ein paar aktuellen Frameworks:
-
sar ist schon seit langer Zeit Teil von Red Hat Enterprise Linux (RHEL) zum Aufzeichnen von Performancedaten. Es ist einfach zu benutzen, hat aber seine Eigenheiten. Zum Beispiel sind sar Archivdateien an sar versionen gebunden, so dass teilweise erst eine bestimmte sar Version installiert werden muss, um eine Archivdatei anzuschauen.
-
collectl ist ein schlankes Perl Script, das sich für einige Szenarien eignet, aber nicht die Flexibilität von fortgeschrittenen Tools mitbringt.
-
Performance Co-Pilot (PCP) ist die Empfehlung von Red Hat zum Sammeln von Performancedaten unter RHEL. In den 20 Jahren, seit PCP existiert, wurden viele Performance Metrics Domain Agents (PMDAs) geschrieben - PMDAs sind Programme, die für Datensammlung von den verschiedenen Quellen eines Systems zuständig sind.
PCP ist in den normalen RHEL 6 und 7 Repositories enthalten. Es bringt viele Tools zum analysieren (z.B. pmdiff) und veranschaulichen (pmchart, pmrep und so weiter) von aufgezeichneten Daten mit. Unter RHEL 6 und 7 sind die PCP Performancedaten auch Bestandteil von sosreports. -
prometheus ist ein recht neues Backend zum Aufzeichnen von Performancedaten. Durch die gute Integration mit Kubernetes gehört es als TechPreview zu OpenShift 3.10. Prometheus bringt auch Alerts (z.B. “Warne wenn die Load zu hoch ist”) und Trendanalysen mit.
-
netdata ist ebenfalls ein relativ neues Tool; es ist auf die direkte Visualisierung von Performancedaten ausgerichtet.
Daten aus PCP, visualisiert mittels graphite/grafana, können so aussehen:
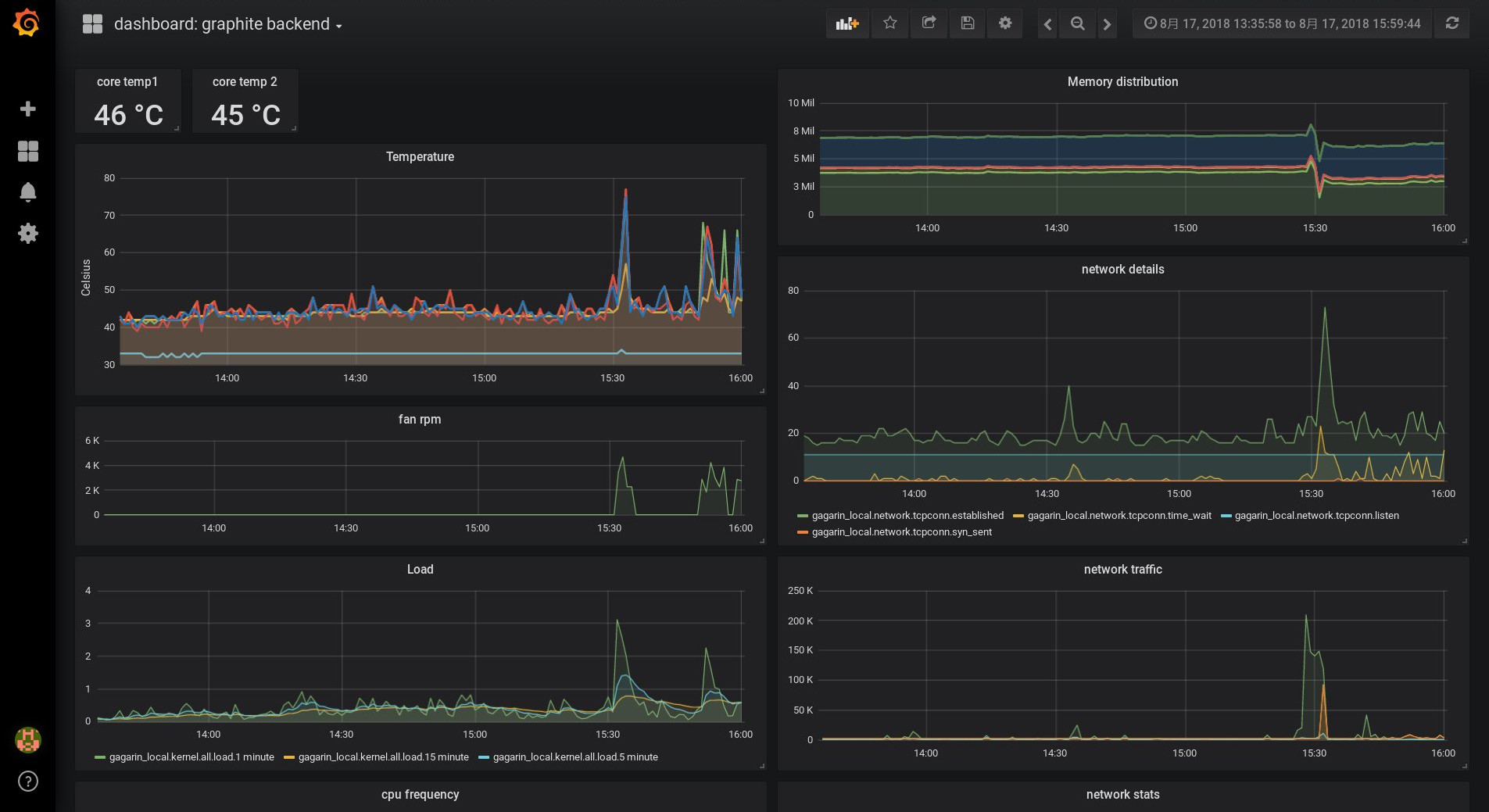
Die PCP Basis-installation
Während die eigentlichen PCP Pakete in den normalen RHEL Repositories enthalten sind, sollte zusätzlich ‘pcp-zeroconf’ aus dem ‘optional’ Repository installiert werden. Dieses Paket konfiguriert eine Grundauswahl von Metriken. Deshalb muss zuerst das optional-Repository aktiviert werden:
# subscription-manager repos --enable=rhel-7-server-optional-rpmsPCP besteht aus vielen einzelnen Paketen. Dadurch kann gezielt nur das installiert werden, was wirklich benötigt wird.
Mit ‘'yum search pcp' erhält man eine Liste der PCP Pakete. Das 'pcp-zeroconf' Paket wird einige dieser Pakete als Abhängigkeiten mit installieren.
# yum install pcp-zeroconf pcp-system-toolsEinige Komponenten wurden als Teil der Paketinstallation bereits konfiguriert und gestartet, dies kann durch Ausführung von ‘ps axf’ überprüft werden:
-
Der pmcd Daemon agiert als Kommunikationszentrale
-
PMDAs werden von pmcd benutzt um Performancedaten, auch als Metriken (‘metrics’) bezeichnet, zu sammeln
-
pmlogger ist für das Aufzeichnen der Daten zuständig
Mit dem obigen Kommando wurde ebenfalls das Paket ‘pcp-system-tools’ installiert, welches praktische Tools zum Zugriff auf die gesammelten Daten enthält. Damit ist die Grundinstallation abgeschlossen. An dieser Stelle schreibt das System schon Performancedaten ins Verzeichnis /var/log/pcp/pmlogger!
Zugriff auf die Performancedaten
Welche Daten werden nun gesammelt, und wie kann man sie auswerten? Mit folgendem Kommando
# pminfoerfahren wir, welche Metriken im Moment von PMDAs bereitgestellt werden. Dieses Kommando kommuniziert ausschließlich mit dem PMCD Daemon und greift nicht auf aufgezeichnete Daten zu. Mit den Parametern ‘-fT’ kann zusätzlich eine Beschreibung der Metric, sowie, falls verfügbar, deren aktueller Wert angezeigt werden.
Pcp-zeroconf hat pmlogger so konfiguriert, das Performancedaten unter /var/log/pcp/pmlogger/<hostname> gespeichert werden. Dateien dieses Verzeichnisses die auf ‘0’ enden sind Archivdateien. Mit dem folgenden Kommando kann geprüft werden, welche Metriken dort abgespeichert werden:
# pminfo -a <archivefile> | lessDer Schalter ‘-a’ weist pminfo an das Archivfile zu benutzen. Mittels
# pmrep kernel.cpuwird auf die aktuell verfügbaren kernel.cpu.* Metriken des Systems zugegriffen.
Durch die Angabe der Archivdatei mittels des ‘-a’-Parameters, werden die Daten aus dem angegebenen Archiv angezeigt. Dies gilt jedoch nur, falls pmlogger konfiguriert wurde um diese Metriken aufzuzeichnen.
# pmrep -a <archivefile> kernel.cpuBenutzer können sich Darstellungen aus den PCP-Metriken, an denen sie interessiert sind, selbst zusammenbauen.
Zum Beispiel wurde ‘atop’ mit PCP Metriken nachgebaut. Per ‘pcp atop’ erhält man eine ‘atop’-kompatible Ansicht, die jedoch die Metriken von PCP benutzt. Auf die gleiche Art und Weise bietet ‘pcp iostat’ I/O Daten an.
Durch die Archive von PCP eröffnen sich neue Möglichkeiten, z.B. kann ‘pcp atop’ auf archivierte Daten zugreifen. Fallbeispiel: man erhält einen Anruf nach dem Muster “Wir hatten Performanceprobleme auf System XYZ gegen 10:40”. Der Administrator kann sich jetzt entweder auf dem betroffenen System anmelden oder die PCP-Dateien auf seinen Arbeitsplatz kopieren. Anschließend ruft er mit
# pcp atop -r <archivefile> -b 10:40eine atop-Ansicht auf, welche den Zustand des Systems um 10:40 zeigt, so als wäre zu dieser Zeit atop live auf dem System ausgeführt worden.
Welche Metriken sind wichtig?
Bleiben wir bei dem Beispiel des gemeldeten “Performanceproblems gegen 10:40”. Nachdem die PCP Dateien zur Analyse kopiert wurden, kann geprüft werden, wie viele unterschiedliche Metriken dort gesammelt werden:
[chris@rhel7u5a ~]# pminfo -a 20180815.09.28.0|wc -l
606
[chris@rhel7u5a ~]#
606 Metriken bei der obigen RHEL 7.5 Installation! Bei RHEL 7.6 sind es bereits über tausend verschiedene Metriken.
Wie kann herausgefunden werden, welche dieser Metriken für die weitere Untersuchung interessant sind. Mit anderen Worten, welche Metriken waren ungewöhnlich um 10:40? ‘pmdiff’ kann hierbei eine Hilfe sein. Mittels der Parameter -S und -T wird ein Zeitraum angegeben, zu dem alles normal war; mit -B und -E der Zeitraum mit dem Problem.
[chris@rhel7u5a ~]# pmdiff -S 09:30 -T 10:30 -B 10:39 -E 10:42 20180815.09.28.0
20180815.09.28.0 20180815.09.28.0 Ratio Metric-Instance
09:30-10:30 10:39-10:42
0.000 0.055 |+| kernel.percpu.cpu.user ["cpu2"]
0.001 0.203 >100 kernel.percpu.cpu.sys ["cpu2"]
0.005 0.251 50.20 kernel.all.cpu.sys
0.002 0.068 34.00 kernel.all.cpu.user
0.002 0.068 34.00 kernel.all.cpu.vuser
0.001 0.034 34.00 kernel.percpu.cpu.sys ["cpu1"]
0.004 0.099 24.75 kernel.all.load ["1 minute"]
0.810 18.75 23.15 xfs.perdev.allocs.free_block ["/dev/mapper/root"]
11906 197904 16.62 xfs.perdev.xstrat.bytes ["/dev/mapper/root"]
2.919 48.32 16.55 xfs.perdev.allocs.alloc_block ["/dev/mapper/root"]
26.88 270.0 10.04 kernel.percpu.intr ["cpu2"]
0.001 0.009 9.00 kernel.percpu.cpu.user ["cpu1"]
0.002 0.014 7.00 kernel.percpu.cpu.sys ["cpu3"]
[..]
Sieht aus als ob CPU sowie Dateisystem beschäftigt waren. Als nächstes sollte mehr über die Prozesse herausgefunden werden, die zum Zeitpunkt des Problems ausgeführt wurden. Der folgende Befehl zeigt uns Metriken des Archivfiles die mit Prozessen zu tun haben:
[chris@rhel7u5a ~]# pminfo -T -a 20180815.09.28.0 proc|lessVon dieser Ausgabe könnten die Metriken proc.runq.runnable und proc.runq.blocked interessant sein. Wie waren diese Werte zum Zeitpunkt des Problems?
@rhel7u5a ~]# pmrep -a 20180815.09.28.0 -S @10:41:15 -T @10:43:18 \
-p proc.runq.runnable proc.runq.blocked | less
p.r.runnable p.r.blocked
count count
10:41:15 2 0
10:41:16 2 0
10:41:17 3 0
10:41:18 3 0
10:41:19 3 0
[..]
10:43:15 3 0
10:43:16 3 0
10:43:17 2 0
10:43:18 2 0
Offenbar wurden durchgehend 2 Prozesse des Systems als ‘runnable’ ausgezeichnet. Zum Zeitpunkt des Problems waren es 3, und kurze Zeit später wieder 2. Die aktuelle pmlogger Konfiguration zeichnet auch Prozesslisten auf. Die Metrik proc.psinfo.psname enthält auch den runstate aller Prozesse.
Welche Prozesse waren vor, während und nach dem Problemzeitpunkt im Status “R” (runnable)?
[chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:40:15 \
proc.psinfo.sname | grep R
inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R"
[chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:41:19 \
proc.psinfo.sname | grep R
inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R"
inst [18345 or "018345 md5sum"] value "R"
[chris@rhel7u5a ~]# pminfo -f -a 20180815.09.28.0 -O @10:43:18 \
proc.psinfo.sname | grep R
inst [7115 or "007115 /var/lib/pcp/pmdas/proc/pmdaproc"] value "R"
[chris@rhel7u5a ~]#
Mit dieser Information ist zu erkennen, dass zu allen 3 Zeitpunkten der PMDA lief; zum Zeitpunkt des Problems zusätzlich ein Prozess ‘md5sum’. Leider zeichnet die Default-config die Metrik proc.schedstat.cpu_time nicht auf. Sie hätte gezeigt, dass der Prozess md5sum um 10:41 die meiste CPU-Zeit beanspruchte.
Pmlogger kann so konfiguriert werden, dass diese Metrik auch aufgezeichnet wird.
Mit den vorhandenen PCP-Daten können weitere Details über den Prozess eingesehen werden, so auch der ausführende User; dieser kann nach dem Hintergrund seiner Aktivitäten befragt werden.
Danke für die Hilfe beim Auflösen dieses Performanceproblems, PCP!
Zusammenfassung
Wir haben gesehen wie einfach es ist, PCP auf RHEL zu installieren, sowie auf Daten Live und aus Aufzeichnungen zuzugreifen. Wie wäre es mit Monitoring von Daten eurer eigenen Applikationen, den Daten von Temperatursensoren oder den SMART-Daten von Festplatten? Wir werden uns das Monitoring von eigenen Applikationen in einem weiteren Artikel anschauen, auch die Erstellung von Grafiken auf Basis dieser Daten.
-
Introduction to storage performance analysis with PCP bietet einen Überblick über PCP
-
Empfohlene manpages: PCPIntro(1), pminfo(1), pmrep(1), pmdiff(1)
Dieser Artikel ist in 3 lokalisierten Versionen verfügbar:
-
Please Click here to read this article in English.
-
この記事の日本語版があります。
Über den Autor

Christian Horn is a Senior Technical Account Manager at Red Hat. After working with customers and partners since 2011 at Red Hat Germany, he moved to Japan, focusing on mission critical environments. Virtualization, debugging, performance monitoring and tuning are among the returning topics of his
daily work. He also enjoys diving into new technical topics, and sharing the findings via documentation, presentations or articles.