
Previously in The Quest for Operations Intelligence, the focus was placed on what can be delivered with log aggregation and how to improve it. A conclusion was that to have full situational awareness on IT, you would need logs, metrics, configuration and events information correlated for easy one stop analysis when problems arise.
While we talked about logs, metrics and configuration in depth, we left events at the time without any sort of definition. What are events and what can we use them for in our quest for operations happiness?
Event happiness
Those most effected by this quest are the system administrators, who are the ones on call when things go wrong in your infrastructure. When the call comes in the middle of the night, this is the moment when log aggregation and metrics can save very precious time in finding the cause of failure.
The question is, what's happened to bring the system administrator to his post in the deep dark of night?
System monitoring has discovered a failure in the infrastructure, generated an alert which triggered an action which sent a message to the sysadmin to respond to the issue.
Depending on the organizational structure, teams taking care of monitoring are often spread throughout the organization. It's handled by the IT ops team itself, by a specific monitoring team, by the security team or possibly by a cross-functional group. The core of this activity is to perform checks on as many parts of your infrastructure as possible.
These checks are the unit testing of your IT infrastructure.
They are often pieces of code or scripts that validate the status of a critical part of the infrastructure, that it's working in a general sense (i.e. checking HTTPD service status by creating TCP connections to ports 80 and 443). These checks can also become very specific, such as downloading the main web page of a server and checking that static objects match the previously recorded sha256 hash.
These checks use metrics by reviewing that some parameters do not go beyond safe thresholds (i.e. CPU usage beyond 90% for more than one minute), or detect certain messages in the generated logs such as any critical message or an specific message that is known as the symptom of a coming outage.
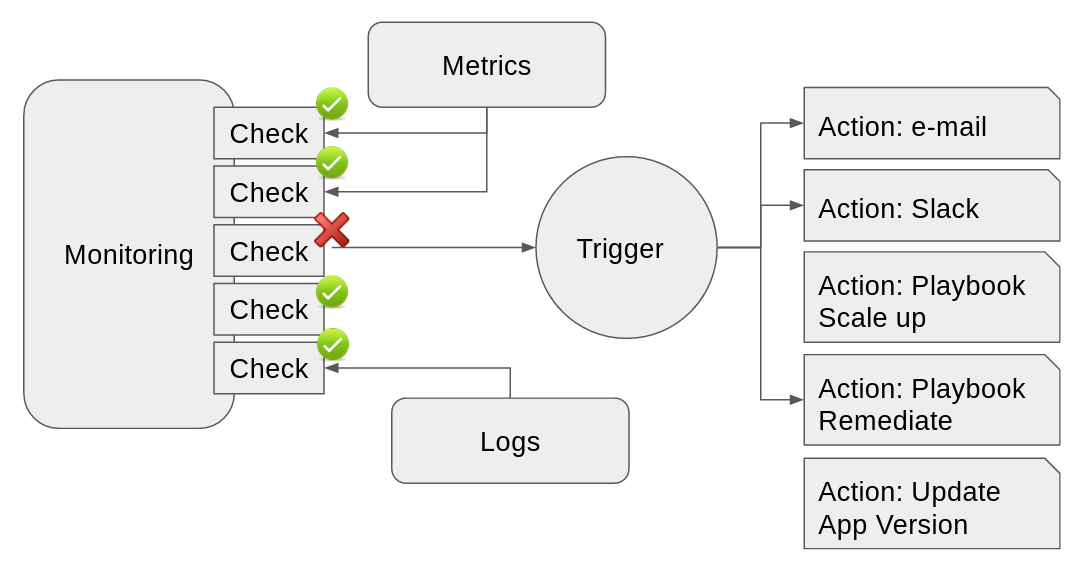
|
| Figure 1. Log aggregation enriching checks and monitoring. |
Beyond monitoring
저자 소개

채널별 검색

오토메이션
기술, 팀, 환경을 포괄하는 자동화 플랫폼에 대한 최신 정보

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

클라우드 서비스
관리형 클라우드 서비스 포트폴리오에 대해 더 보기

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기

오리지널 쇼
엔터프라이즈 기술 분야의 제작자와 리더가 전하는 흥미로운 스토리
제품
- Red Hat Enterprise Linux
- Red Hat OpenShift Enterprise
- Red Hat Ansible Automation Platform
- 클라우드 서비스
- 모든 제품 보기
툴
체험, 구매 & 영업
커뮤니케이션
Red Hat 소개
Red Hat은 Linux, 클라우드, 컨테이너, 쿠버네티스 등을 포함한 글로벌 엔터프라이즈 오픈소스 솔루션 공급업체입니다. Red Hat은 코어 데이터센터에서 네트워크 엣지에 이르기까지 다양한 플랫폼과 환경에서 기업의 업무 편의성을 높여 주는 강화된 기능의 솔루션을 제공합니다.