
Not that long ago, databases were viewed as the definition of a monolith — never intended to be broken down into microservices and containerized. A lot has changed in a short period of time and while containerizing a database may not be as straightforward as containerizing an application, the benefits greatly outweigh the challenges. Databases need the agility, portability and scalability that containerization can offer and organizations are moving to take advantage of these benefits.
A recent Red Hat-sponsored study conducted by Gartner Peer Insights surveyed 200 tech leaders across the globe to find out how organizations are adopting databases on containers and Kubernetes, what technologies they are considering for deploying these workloads and more. The full report is available here, and we’ve highlighted some of the key findings below.
Adoption is increasing — and for a variety of use cases
The vast majority of respondents are well on their way to operationalizing databases on containers, with 69% stating that they are in the middle or advanced stages of adoption. Of that 69%, 4% believe they are far along in the process and 65% believe they are somewhere in the middle — having started adoption, but not using databases on containers in a full-fledged manner as of yet.
Additionally, given the number of tools now available to help ease adoption, we expect these numbers to continue to grow. Kubernetes Operators and Helm charts help automate day-1 and day-2 operations like installation, configuration and updates and upgrades, as well as help with lifecycle management of applications, greatly simplifying adoption and ongoing maintenance for organizations.
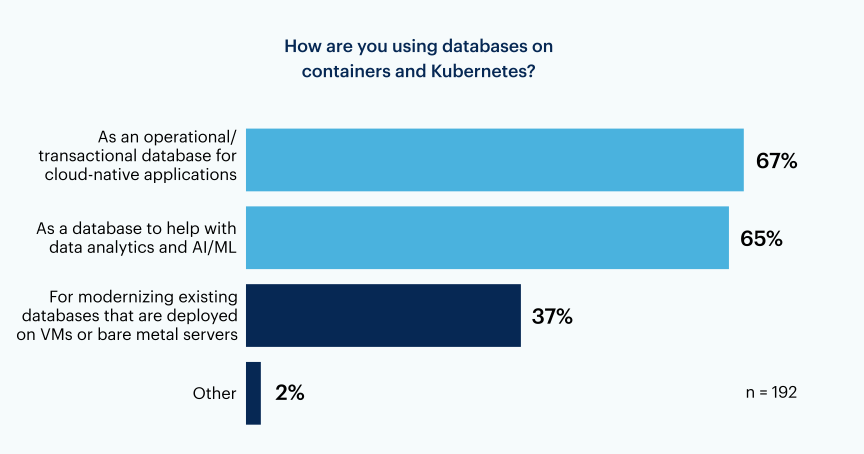
The reason for adoption varies, with operational or transactional use cases being the number one reason, as reported by two-thirds (67%) of the respondents. Nearly even with operational use cases, 65% of respondents are using databases on containers and Kubernetes to help with data analytics and AI/ML. A significant number of respondents (37%) are using containers to modernize their traditional databases that are deployed on virtual machines or bare metal servers.
Mixed methods for deploying
When deploying databases on containers, organizations are taking multiple approaches. The survey found Database-as-a-Service (DBaaS) offerings from cloud vendors is the most popular approach, with 61% of respondents utilizing these offerings. Database-as-a-Service is an API-based cloud service model where the service provider is responsible for the required database physical infrastructure and server-side DBMS resources, including performance configurations — essentially simplifying administration. Following close behind DBaaS offerings is deploying cloud-native databases such as Crunchy Data, Couchbase, MongoDB etc., with 52% of respondents reporting use of these offerings.
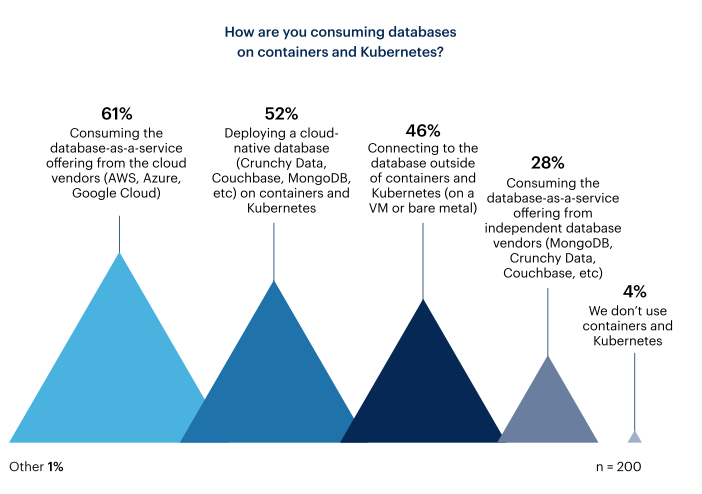
When asked about how their organization plans to consume databases in two years from now, results were similar but show an increase in both the respondents that plan to deploy a cloud-native database and those that plan to consume a DBaaS offering from independent database vendors. Respondents that plan on connecting to databases outside containers and Kubernetes are decreasing — suggesting more organizations want to adopt databases on containers and Kubernetes.
Databases are everywhere - including the edge
Edge computing has been unlocking new opportunities for organizations to deliver new insights and experiences. As important data-related decisions are happening at the edge, organizations are reconsidering where data will be stored, given privacy and security and compliance considerations.
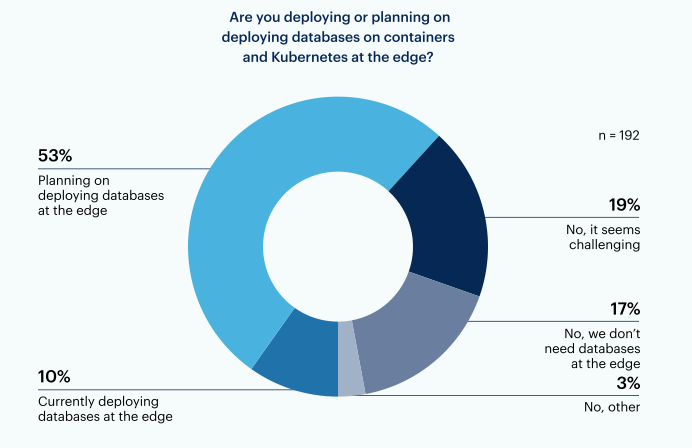
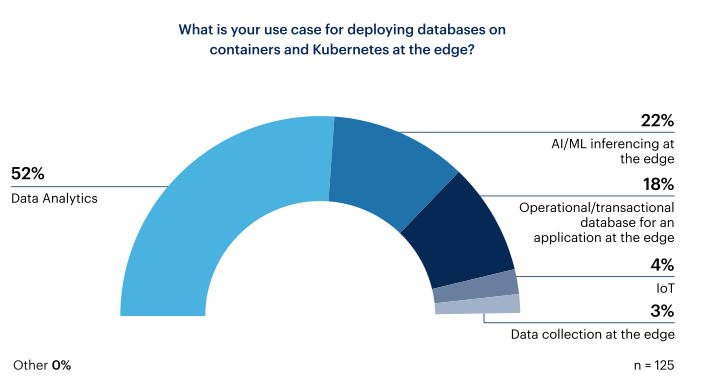
A majority of respondents (63%) are currently deploying or planning on deploying databases on containers and Kubernetes at the edge. Of those who plan to deploy databases on containers and Kubernetes at the edge, almost three-quarters (74%) plan to use it for either data analytics or AI/ML inferencing at the edge. In contrast, only 18% reported they need an operational/transactional database for an application at the edge.
The need for hybrid
Databases and data analytics are integral to cloud-native applications, accelerating data ingestion, storage, processing and analysis. Containerized databases have now become an on-demand utility that is integral to the application itself.
Kubernetes users are frequently mixing multiple methods of integrating data services into their clusters, with a combination of cloud databases, databases deployed directly through Kubernetes and also connecting to VMs running data services outside of the cluster. A platform that enables all three is key to developer agility.
Red Hat OpenShift allows organizations to run databases and data analytics in a consistent way across clouds to accelerate delivery of cloud-native applications. For more information visit the databases and data analytics on Red Hat OpenShift page.
저자 소개

Red Hat is the world’s leading provider of enterprise open source software solutions, using a community-powered approach to deliver reliable and high-performing Linux, hybrid cloud, container, and Kubernetes technologies.
Red Hat helps customers integrate new and existing IT applications, develop cloud-native applications, standardize on our industry-leading operating system, and automate, secure, and manage complex environments. Award-winning support, training, and consulting services make Red Hat a trusted adviser to the Fortune 500. As a strategic partner to cloud providers, system integrators, application vendors, customers, and open source communities, Red Hat can help organizations prepare for the digital future.
채널별 검색

오토메이션
기술, 팀, 환경을 포괄하는 자동화 플랫폼에 대한 최신 정보

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

클라우드 서비스
관리형 클라우드 서비스 포트폴리오에 대해 더 보기

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기

오리지널 쇼
엔터프라이즈 기술 분야의 제작자와 리더가 전하는 흥미로운 스토리
제품
- Red Hat Enterprise Linux
- Red Hat OpenShift Enterprise
- Red Hat Ansible Automation Platform
- 클라우드 서비스
- 모든 제품 보기
툴
체험, 구매 & 영업
커뮤니케이션
Red Hat 소개
Red Hat은 Linux, 클라우드, 컨테이너, 쿠버네티스 등을 포함한 글로벌 엔터프라이즈 오픈소스 솔루션 공급업체입니다. Red Hat은 코어 데이터센터에서 네트워크 엣지에 이르기까지 다양한 플랫폼과 환경에서 기업의 업무 편의성을 높여 주는 강화된 기능의 솔루션을 제공합니다.