
Blog da Red Hat
Previously in The Quest for Operations Intelligence, the focus was placed on what can be delivered with log aggregation and how to improve it. A conclusion was that to have full situational awareness on IT, you would need logs, metrics, configuration and events information correlated for easy one stop analysis when problems arise.
While we talked about logs, metrics and configuration in depth, we left events at the time without any sort of definition. What are events and what can we use them for in our quest for operations happiness?
Event happiness
Those most effected by this quest are the system administrators, who are the ones on call when things go wrong in your infrastructure. When the call comes in the middle of the night, this is the moment when log aggregation and metrics can save very precious time in finding the cause of failure.
The question is, what's happened to bring the system administrator to his post in the deep dark of night?
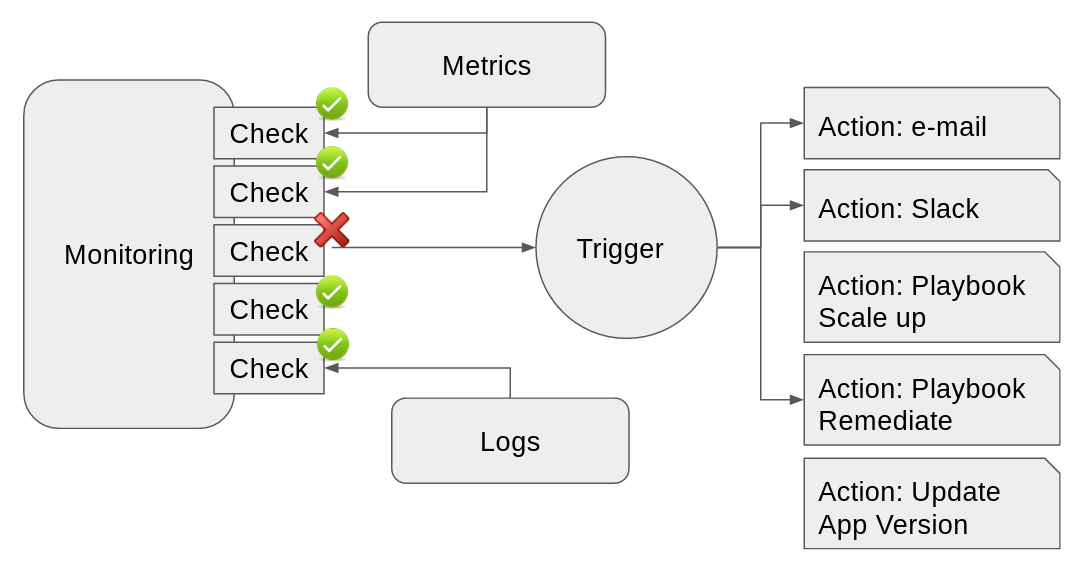
System monitoring has discovered a failure in the infrastructure, generated an alert which triggered an action which sent a message to the sysadmin to respond to the issue.
Depending on the organizational structure, teams taking care of monitoring are often spread throughout the organization. It's handled by the IT ops team itself, by a specific monitoring team, by the security team or possibly by a cross-functional group. The core of this activity is to perform checks on as many parts of your infrastructure as possible.
These checks are the unit testing of your IT infrastructure.
They are often pieces of code or scripts that validate the status of a critical part of the infrastructure, that it's working in a general sense (i.e. checking HTTPD service status by creating TCP connections to ports 80 and 443). These checks can also become very specific, such as downloading the main web page of a server and checking that static objects match the previously recorded sha256 hash.
These checks use metrics by reviewing that some parameters do not go beyond safe thresholds (i.e. CPU usage beyond 90% for more than one minute), or detect certain messages in the generated logs such as any critical message or an specific message that is known as the symptom of a coming outage.
|
| Figure 1. Log aggregation enriching checks and monitoring. |