
Frustrated by long delays getting new code into production? Worried that developers are adopting unapproved technologies? In an increasingly automated, containerized world it’s time to adapt your processes and policies so that developers can utilize the latest and most appropriate technology -- and operations have full awareness of everything running in their environment.
The Problem and How to Solve It
IT processes, driven by business reliance on Mode 1 applications, have not been designed nor are equipped to handle rapid change. This creates friction between management and operations on one side, and developers on the other. For example, when developer teams want to employ new or different tools than the standards accepted by operations it often creates friction. It doesn’t have to be this way, though.
In this post, we are going to take a deeper look at the collaboration that happens between development and operations when building and working with the “latest and greatest” technology stack.
As developers and operations become more and more familiar with the collaboration inherent to building and deploying containerized applications, we can speed up adoption of new tools.
Getting the Balance Right
Instead of developers taking on the burden of new tooling, they can pass requirements to operations and get the tools they need to build apps on top of baked into base images. The ability to move swiftly in adopting new tools can become a point of strategic differentiation.
Updating both “legacy” and “modern” (most often called Mode 1 and Mode 2) applications to make use of a new (and ever evolving) cloud native software stack can be a little bit of a challenge. The new world of cloud native/containerized applications requires developers and operations to have an understanding for how to keep the base container images up to date by implementing a standard operating environment, and how to update the container platform itself. If new images are published by their vendors, and by the way: not all vendors publish such detailed information about their new releases.
Looking at the diverse and agile behavior/organizational structure of the future, containerized IT, the implementation of clear interfaces between developers and operations will get a stronger focus.
By leveraging each team’s strengths, our customers get a broader and higher quality tool chain. The development team gets rid of monitoring upstream projects for new versions, or at least can move into a position where they notify their Ops team that a new version is available. The operations team knows exactly what software is being run in their containers on the production container platform, ensuring high operational quality.
Nomenclature
Throughout this article I will refer to Red Hat’s distribution of the Kubernetes container platform as OpenShift Enterprise Container Platform. In addition, to familiarize yourself with other (potentially foreign) nomenclature I suggest reading through this post on container terminology.
Finally, for this article I assume that we are looking at a private cloud, running (mostly) workloads and applications developed “in house.” When developers release new versions of their software (a.k.a. “...it’s just a small bug fix!”) OpenShift’s BuildConfig is responsible for compiling the source and assembling all the artifacts to compose a new container image and push it into the registry.
Defining the Roles
Let's have a look at the core user story we are exploring:
As an Application Developer, I want to use a Source-to-Image builder that carries a newer version of NodeJS than that Source-to-Image builder provided by Red Hat, so that I can use the latest and greatest NodeJS.
Let’s agree, that our developers should not - and will not - roll and maintain their own builder images, which they probably did in the past. It’s neither efficient nor conducive to a standard environment to have developers and admins doing the same work.
So here is one promise Ops will give: Ops will always provide an up to date builder. The SLA for this will vary from company to company, but the important thing is that Ops commits to keeping builders up to date. That is the promise that will make Ops cool (again, like back in the 80s when ops people wrote their own hardware driver, but I digress)!
Dev will promise not to roll their own (maybe a little guided by their management). That is the promise that will make Dev cool. Both promises constitute the DevOps contract, but that’s a whole different story to tell.
More importantly, this agreement draws a clear line between Dev and Ops and separates an application's software stack in a set of layers, whereas each layer is owned by a different party.
Stack Layers and Owners
In general operation, maintenance, and support of the whole application software stack has been separated into different layers (shown below). This is true for Mode 1 applications, but also still true for Mode 2 applications.
In a Mode 1 universe operation, maintenance, and support maps directly to ‘virtual machine provisioning’ or ‘release a new version of a package content view.’ For each layer a separate role may be responsible.
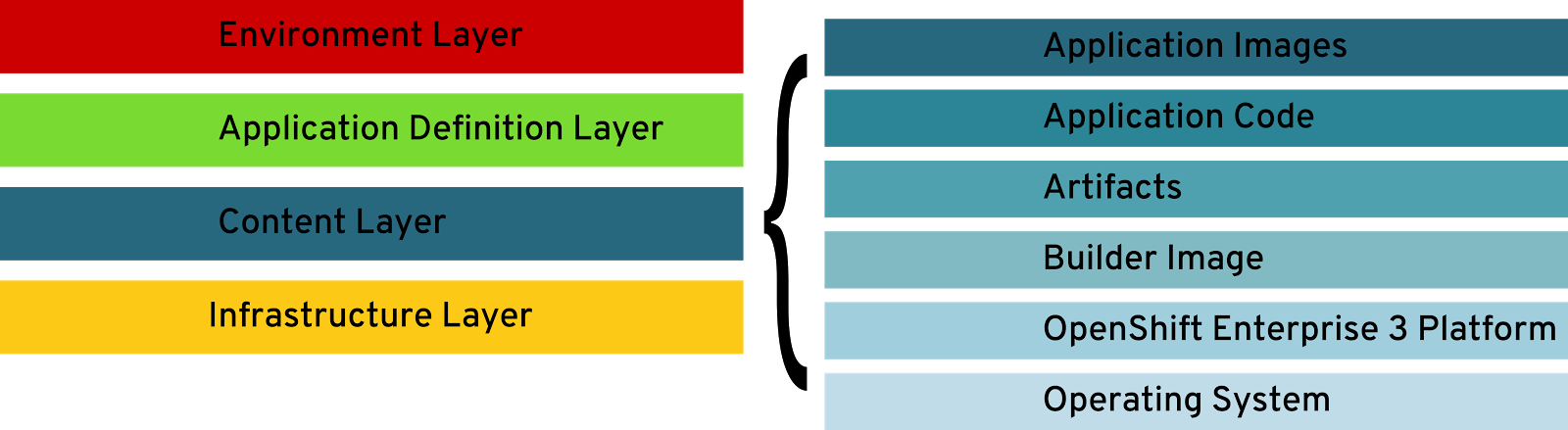 Figure 1: Application Stack and Content Layer
Figure 1: Application Stack and Content Layer
Environment Layer
Built on top the Application Definition Layer this layer includes settings for examples secrets required within different environments (for example the CI environment or production).
Application Definition Layer
This will define the relations between content of the application (eg. databases, infrastructure components, datasets for CI tests) and the Content Layer.
Content Layer
Within the Content Layer the whole software stack constituting the application’s logic lives. This means different versions of components of the standard operating environment, like different versions of RHEL RPMs, versions of OpenShift Container Platform RPMs and container images, up to different versions of the compiled application code within container images.
Ownership (or accountability for managing) of those layers may depend on your organisation, but a common pattern could be observed:
Application Code and Artifacts, Application Container Images
These layers and their artifacts are owned by the development team(s). To generate content for these layers, they utilize the Builder Images layer and their usual tools are git, Eclipse, Atom, gcc, golang, … whatever your development team happens to be working with.
Builder Images layer
The Builder Images layers is one of the most important layers, as within this layer developers and operations collaborate on one of their valuables assets: the build tools chain. The layer is owned by operations but cut to fit the needs of developers, which are dictated by the business’ needs.
OpenShift Container Platform layer
This layer is the base of the Container Platform and is maintained and owned by System Engineering and System Operators. It is closely coupled to the Operating System layer.
Operating System layer
As being the lowest layer and closes to the infrastructure, thus most often containing special hardware drivers or system agents, this layer is managed by System Engineering or the so called System Operators.
Infrastructure Layer
The Infrastructure Layer will be managed by Infrastructure Operator being responsible to provide sufficient resources for the Container Platform on top of the infrastructure. Their responsibilities include (but is not limited to) for example maintain Network, Storage, and Compute resource either being physical or virtual on a private or public cloud.
For a more detailed view on roles and their definition please see page 8 of OpenShift Enterprise 3 Architecture Guide - planning, deployment and operation of an Open Source Platform as a Service.
And for our user story described above, we will zoom into the Content Layer, specifically the Builder Image layer (owned by Ops) and the Application Code layer (owned by Dev).
The criteria for selection of a software stack or framework and the corresponding tool chain might differ quite a bit, depending on if the stack is chosen by the Dev or Ops role.
The tool chain to build the code might be highly specific to the source code that will be used to build from. Building the build tool chain might (at least) be a joint effort between Dev and Ops.
The Dev Perspective
From the point of view of developers, the world is a better place: they are not responsible for the container image build tool chain. Instead, they can simply assume that they can use the most up to date tool chain to build their applications as container images.
But at the same time, they remain dependant on the Ops team! The Ops team is responsible for providing the build tool chain, and developers depend on that team to implement changes and updates. In fact, at 2AM, it makes the developer’s life easier to have this dependency.
In a Red Hat OpenShift Container Platform environment, the meeting point for these two groups is called a builder image, represented by an ImageStream object.
A builder image will pull, assemble, and package all that is required to run an application, (e.g. NodeJS packages will be downloaded, JavaScript will be minified, and any/all the static files will be put in the container image). There might be pre-build steps before an OpenShift build happens. This is probably true even for a build pipeline that is controlled and run outside of OpenShift.
Developers can choose a specific version of the container image provided by the image stream, or they use the latest tag and stay on the latest version of the images. It is important to note that the version management of the container images in the Image Stream is done by the Ops team.
The Ops Perspective
So what is the role of operations in this structure? The Ops team will ingress, remix, and provide builder images. Builder images are provided by Red Hat as part of Red Hat OpenShift Container Platform itself, but the Ops team may choose to create and provide custom images as well. Either way, the Ops team will:
- Provide ImageStream objects in the container platform, corresponding to the builder image versions available.
- Manage the version tags for each ImageStream.
- Keep developers informed of changes, (note that this is more of a business process than technology).
I will not go into great details on why the Ops team should provide a specific version of a builder image, but it is easy to imagine not only technical aspects but also governance and compliance aspects.
Now, imagine that no developer can get away with a “well it ran on my laptop with the stuff I pulled from Docker Hub.” Our work on “10 Steps to Build an SOE: How Red Hat Satellite 6 Supports Setting up a Standard Operating Environment” might give you some more insights.
One ImageStream to rule them all?
Looking at the user story again, we see that developers would like to use the newest stuff available, but what about their existing applications? They won’t be migrated to the newest stuff? How can Ops ensure that these applications also receive critical updates?
The Ops team needs to provide more than one versioned ImageStream - really a set of versioned ImageStreams, so that different versions of tool chains and/or frameworks could be provided to Dev.
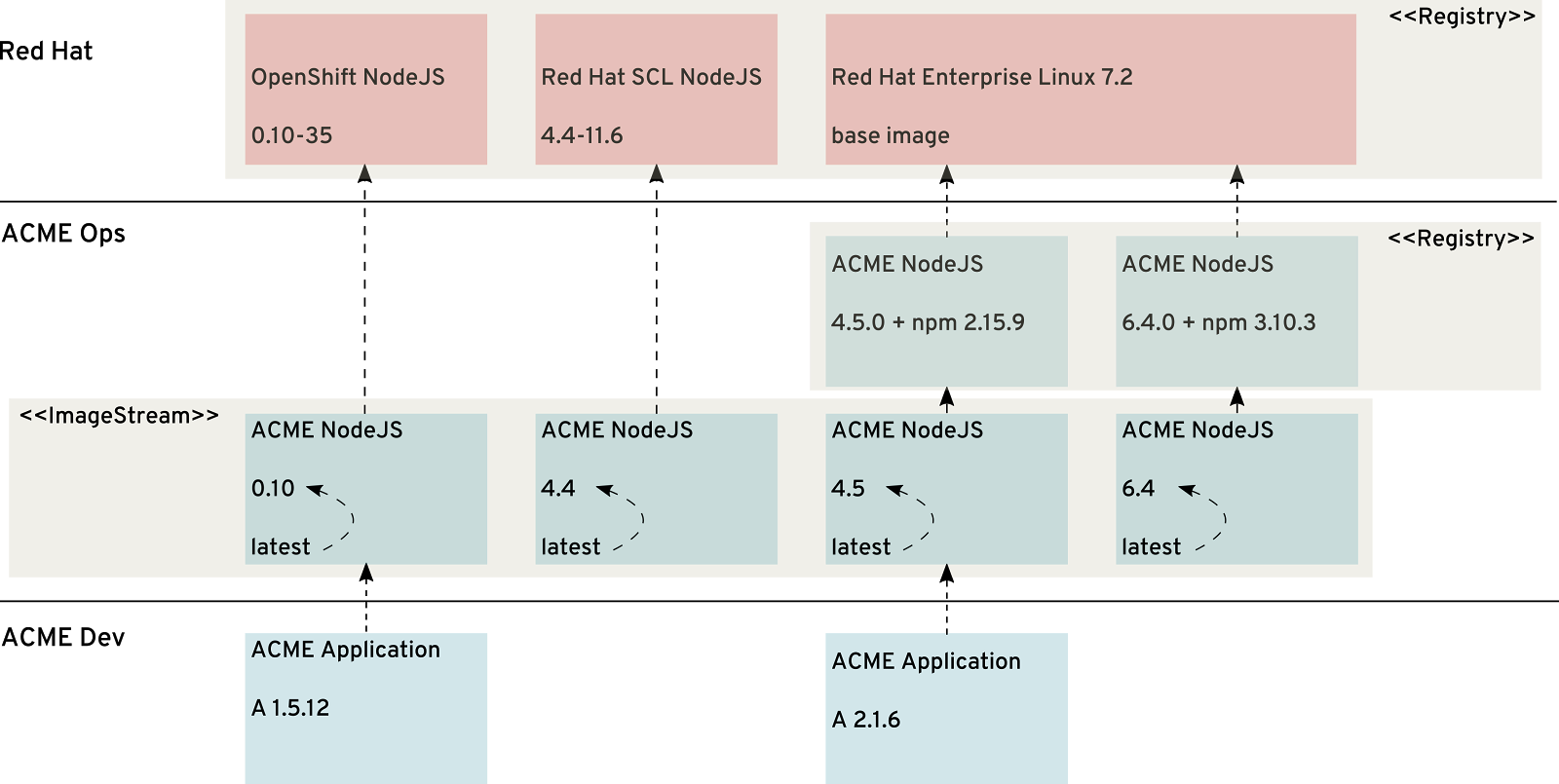 Figure 2: A Set of versioned ImageStreams
Figure 2: A Set of versioned ImageStreams
In Figure 2, Ops provides four versions of NodeJS, each as a separate ImageStream:
- 0.10, directly from Red Hat and unmodified from Red Hat OpenShift Container Platform.
- 4.4, directly from Red Hat and unmodified from the Software Collection Library.
- 4.5, created by the Ops team and based on a standard RHEL 7.2 base image.
- 6.4, created by the Ops team and based on a standard RHEL 7.2 base image.
NOTE: each arrow denotes a dependency, for example ACME Application A 2.1.6 uses ACME NodeJS 4.5:latest, which is indeed NodeJS 4.5.0 created by ACME Ops using a RHEL7.2 base image.
On OpenShift Mechanics
Let us have a look at maintenance tasks like container image updates, especially container images that Red Hat provides.
Within Red Hat OpenShift Container Platform, ImageStreams provide the ability to trigger automatic rebuilds of decedent images when their upstream image is changed.
So any image that changes will result in an update: image tags and metadata will be pulled in and merged with the ImageStream. This inclusion into the ImageStream results in a so-called trigger, which upon other OpenShift objects could listen and act. ImageStream triggers are often used to start new build, ending in pushing a new container image into an ImageStream again.
The only two triggers which need to be fired manually are updates to container images created by the Ops team itself: ACME NodeJS 4.5 and 6.4. For these two container images the ACME Ops team must watch releases by the upstream projects and incorporate these into a new container image. After these new container images have been pushed to ACME’s registry, the fully automated mechanics kick in.
A more detailed view
Now, let’s walk through a detailed example: Red Hat provides a new RHEL7.2 base image. What happens? First of all, we ignore all other automated actions being kicked off inside of Red Hat OpenShift Container Platform, and focus solely on NodeJS 4.5 and 6.4 created by the Ops team.
After the new RHEL 7.2 base image is pulled in and the ImageStream is updated, a new build is triggered for all BuildConfigs which rely on it. One of the builds will create a new version of the “ACME NodeJS” container image and will push it to the “ACME NodeJS” ImageStream. This new version will be tagged as 4.5.1 and/or latest.
This first step is illustrated in Figure 3.
 Figure 3: ImageStream Work Flow
Figure 3: ImageStream Work Flow
This update to the “ACME NodeJS” ImageStream will result in sending out an additional trigger, and a new build will start. This build will create “ACME Application A 2.1.6.1” using “ACME NodeJS 4.5.1”. The sequence looks quite similar to the sequence shown above.
After the “ACME Application A 2.1.6.1” build (note that I assume that a full CI/CD pipeline was passed successfully) finished and finally pushed and tagged a new container image, this new version of Application A will be deployed to production.
Hopefully this chain of triggers and actions removed the last bug from Application A’s software stack, which was located in the lowest left: the RHEL 7.2 base image. No changes to the NodeJS build tool chain or Application A’s source code itself have been implemented, just an completely up to date RHEL has been deployed to production.
Conclusion
We have shown how an implementation of clear interfaces between Dev and Ops should look like. Each team’s strengths are utilized to get a broader, faster moving, and higher quality tool chain. In addition to that well-defined interface and tool chain, using the same platform and version for integration testing and production reduces a lot of friction between development and operations.
It’s important for Ops to consider providing up-to-date toolchains when designing the container platform: outdated or unavailable tool chains are unattractive to developers!
Using the built in mechanics of Red Hat OpenShift Container Platform speeds up deployment of critical bug fixes, access to the latest tools and security fixes, ensuring high operational quality. More on “OpenShift Enterprise 3 Architecture Guide - planning, deployment and operation of an Open Source Platform as a Service” will show you how to plan a production instance of Red Hat OpenShift Container Platform.
And as a final note: please do have a look at an S2I builder for NodeJS using the latest NodeJS releases over at the OpenShift S2I Community.
If you have questions or feedback - I encourage you to reach out using the comments section (below).
Sobre o autor

Navegue por canal

Automação
Saiba o que há de mais recente nas plataformas de automação incluindo tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Serviços de nuvem
Aprenda mais sobre nosso portfólio de serviços gerenciados em nuvem

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações

Programas originais
Veja as histórias divertidas de criadores e líderes em tecnologia empresarial
Produtos
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Red Hat Cloud Services
- Veja todos os produtos
Ferramentas
- Treinamento e certificação
- Minha conta
- Recursos para desenvolvedores
- Suporte ao cliente
- Calculadora de valor Red Hat
- Red Hat Ecosystem Catalog
- Encontre um parceiro
Experimente, compre, venda
Comunicação
- Contate o setor de vendas
- Fale com o Atendimento ao Cliente
- Contate o setor de treinamento
- Redes sociais
Sobre a Red Hat
A Red Hat é a líder mundial em soluções empresariais open source como Linux, nuvem, containers e Kubernetes. Fornecemos soluções robustas que facilitam o trabalho em diversas plataformas e ambientes, do datacenter principal até a borda da rede.
Selecione um idioma
Red Hat legal and privacy links
- Sobre a Red Hat
- Oportunidades de emprego
- Eventos
- Escritórios
- Fale com a Red Hat
- Blog da Red Hat
- Diversidade, equidade e inclusão
- Cool Stuff Store
- Red Hat Summit