
Data management has been the bane of enterprise computing since the days when mainframe computers had to reconcile data from a myriad of sources to do the even simplest month-end reporting. It was painful then. It’s painful now.
Want to get hands-on experience working with a schema registry?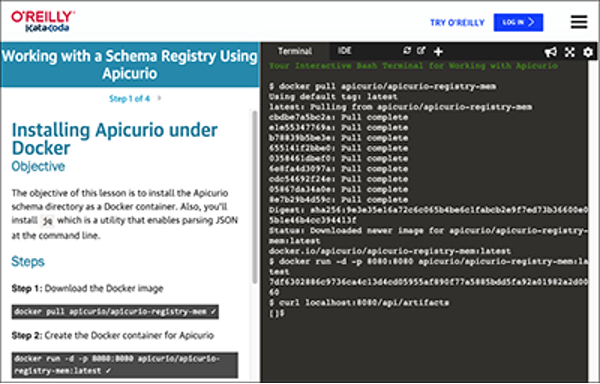
This article ships with a fully interactive set of lessons on Katacoda that demonstrate how to set up and use the Apicurio Registry. Katacoda provides a fully operational virtual machine into which you can execute instructions automatically by clicking on a command in the instructional text. You can find schema registry lessons on Katacoda here. |
Understanding the problem of schema consistency
While it’s true that ETL (extract, transform, load) tools have made life easier within the given business domain, applications that process data between domains, particularly those applications based on microservice-oriented architecture, still have to struggle. Figure 1 below illustrates the problem. The illustration shows two data schemas. One describes an Order in the Orders microservice, and the other describes a Customer in the Sales microservice.

Figure 1: Order.destination and Customer.address have different property names, yet both data structures describe the same thing
Notice in Figure 1 above, an Order shown on the left side of the illustration has a property named destination. Destination has several attributes that look very similar to the attributes associated with the address property of Customer on the right side of the illustration. The attributes in Order.destination and Customer.address are similar, but they are not identical.
Order has the attributes province and postal_code, while Customer has the attributes state and zip_code. While these attributes differ in name, in terms of their semantics, they mean the same thing. Yet, for data to be exchanged between the Orders and Sales microservices, the disparity among property names must be accommodated, particularly when data exchange between microservices is facilitated using automation. While it’s easy for a human to notice similarities in meaning among attributes with different names, it’s a significant task for machine intelligence.
Solving the data schema problem
So then, from an Enterprise Architecture point of view, what measures can we take to make it so services can exchange data without incurring the mishap of schema incongruity?
One way to make it so that one process can understand the data structures used in another process is to use a translation tool such as BizTalk Server. This is a viable solution, but one that has historically required human intelligence to implement. Some engineer somewhere has to take the time to map one attribute to another manually, for example, mapping postal_code to zip_code as shown in Figure 1 above. It’s a time-consuming task.
Another way is to make sure that all services describe data in the same way. This is where a schema registry comes into play. A schema registry is a program or service that describes the data structures used in a given domain. Its purpose is to be the sole source of truth in terms of schema definitions.
The value of using a schema registry
Centralizing all schema definitions at a common point for reference provides a way for services to exchange data reliably. There’s no guessing. For example, if a service, Microservice A, wants to exchange data with another service, Microservice B all that’s required is for Microservice A to get the definition for the particular schema published by Microservice B from the service registry. (See Figure 2 below.)
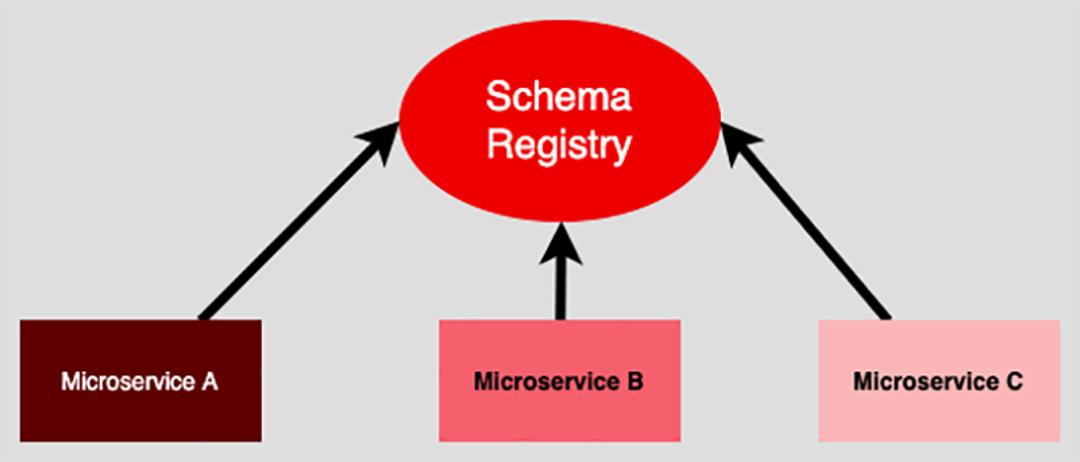
Figure 2: A schema registry serves as the sole source of truth for all data schema using a given domain
Once Microservice B’s schema is known, the developer programming Microservice A can create the data exchange code.
If Microservice A is holding data in a structure that is incongruent with Microservice B’s schema, some mapping will need to be done. There’s no magic. But, at the least, the developer writing the data exchange code will be aware of the conditions to satisfy because Microservice B’s data schema is well known. It’s not a question of reverse engineering some code in play and then having to figure out the mapping. Having the reliability provided by a single source of truth is a definite time-saver.
Another area where a schema registry provides significant value is around validation. In the world of data management, there are few experiences more disappointing than writing a bunch of data validation code based on a given example, only to have the code become worthless because the underlying data schema you used was changed by a Data Architect somewhere upstream in the development process. Using a schema registry minimizes the problem. In some cases, using a schema registry makes the issue go away altogether.
The way it works is that when it comes time to validate some data, the developer will get the schema associated with the submitted data from the domain’s schema registry. As shown in Figure 3 below, the developer will validate the submitted data against the current data schema retrieved from the registry.
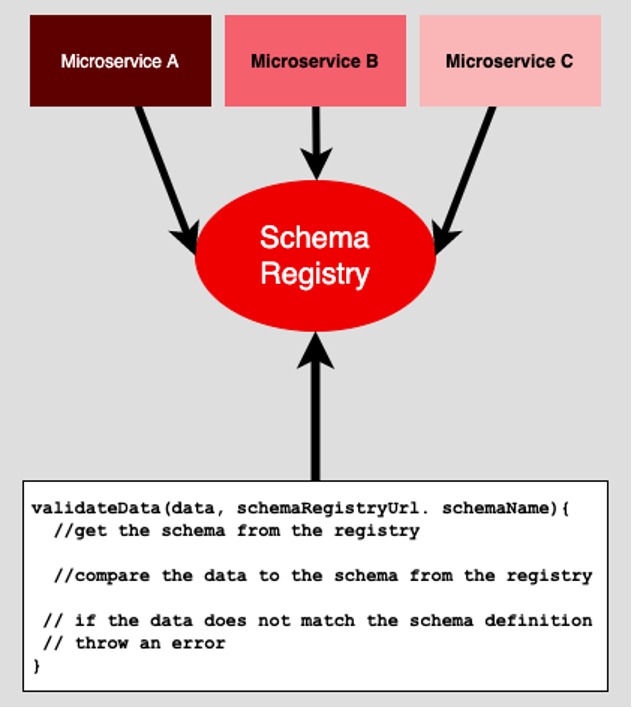
Figure 3: Developers can use a schema registry to create validation code that is always accurate
The implicit contract in play is that all parties active in the given domain are expected to use the schema registry to store schema definitions and that all schema versions are the latest in play. No data schemas should exist outside of the registry. No schemas should be hardcoded into programs. It’s bad business. Instead, as mentioned above, the schema registry is the sole source of truth and needs to be treated as such.
Putting it all together
Schema registries are becoming quite popular. There are a few out there already, such as Red Hat Service Registry and Apicurio Registry (See Figure 4, below).
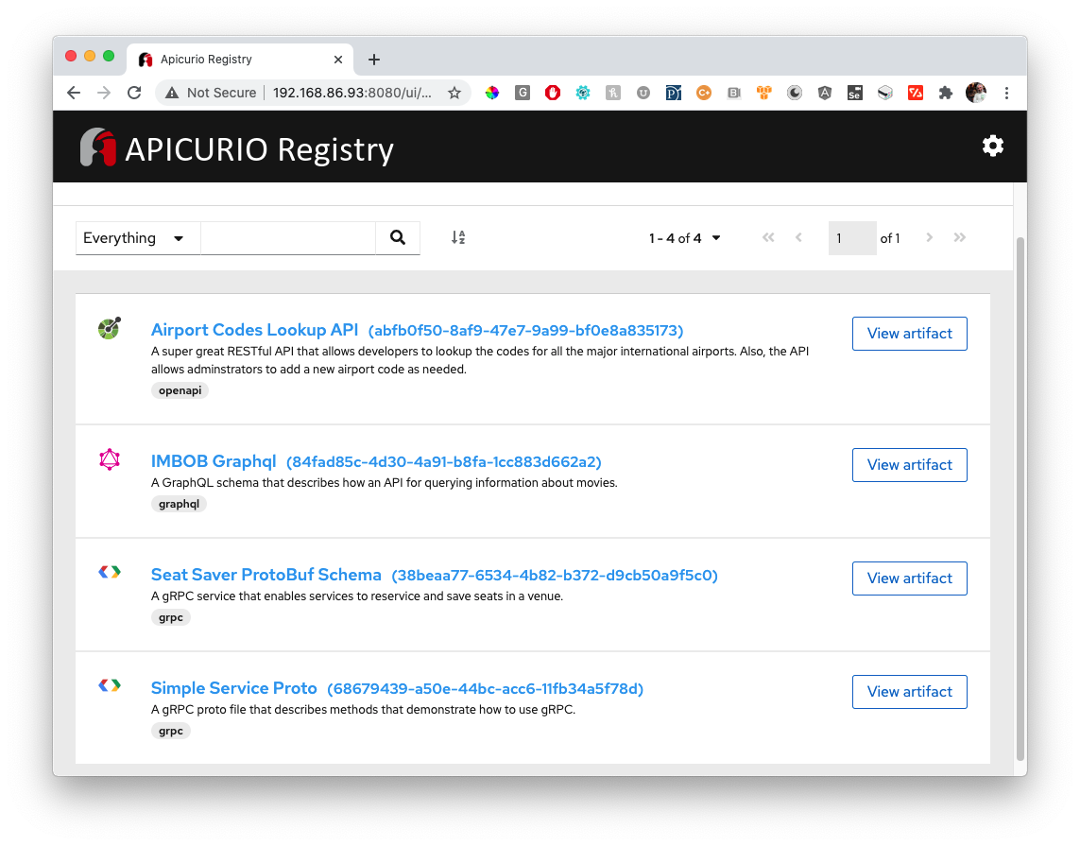
Figure 4: Apicurio is an open source schema registry that supports a wide variety of formats
Granted, things can get tricky when committing yourself to a particular provider’s schema registry service, particularly when working in a multi-provider architecture. You will have to declare one provider the authority. But having the benefit of a single source for defining data structures and creating solid, verifiable boundaries based on those structures outweighs the risk of dedicating yourself to a single provider. Should you need to make a change and move to another provider, it’s a controllable event.
Regardless of which approach you take, whether to use a particular provider’s schema registry or roll your own, the important thing to understand is that a schema registry provides significant benefits for ensuring the easier exchange of data between services while reducing the work that goes with validating data coming into a service.
If you’re not using a schema registry as a resource for your activities as an enterprise architect, now is a good time to look at the technology. Schema registries are here to stay. The benefits they provide are hard to ignore.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Why platform engineering fails to scale: Product and adoption design in practice
The new reality of supply chain trust: Why platform-native security is non-negotiable
Untangling Networks | Compiler
Command Line Heroes: Season 2: Bonus_Developer Advocacy Roundtable
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds