
Admins (or normal users) often need to back up files or keep them in sync between multiple places (including local and remote) without transferring and overwrite all files on the target every time. One of the most useful tools in a sysadmin’s belt for this kind of task is rsync.
The rsync tool can recursively navigate a directory structure and update a second location with any new/changed/removed files. It checks to see if files exist in the destination before sending them, saving bandwidth and time for everything it skips. Also, rsync provides the ability to synchronize a directory structure (or even a single file) with another destination, local or remote. To accomplish this efficiently, by default, it will check the modification times of files. It can also do a quick hash check of files on the source and destination to determine whether or not it needs to transfer a new copy, possibly saving significant time and bandwidth.
[ You might also like: 5 advanced rsync tips for Linux sysadmins ]
Since it comes packaged with most Linux distributions by default, it should be easy to get started. This is also the case with macOS, *BSDs, and other Unix-like operating systems. Working with rsync is easy and can be used on the command line, in scripts, and some tools wrap it in a nice UI for managing tasks.
On the command line, rsync is generally invoked using a handful of parameters to define how it should behave since it’s a flexible tool. In its simplest form, rsync can be told to ensure that a file in one location should be the same in a second location in a filesystem.
Example:
# rsync file1.txt file2.txt
It’s ordinarily desirable to pass rsync a few parameters to ensure things behave the way a human would expect them to. Passing parameters such as -a for “archive” is quite common as it is a “meta-parameter” that automatically invokes a handful of others for you. The -a is equivalent to -rlptgoD, which breaks down to:
-r: Recurse through directories (as opposed to only working on files in the current directory)-l: Copy symlinks as new symlinks-p: Preserve permissions-t: Preserve modification times-g: Preserve group ownership-o: Preserve user ownership (which is restricted to only superusers when dealing with other user’s files)-D: Copy device files
Often this works how the user wants and no significant changes are necessary. But, some of those might be contrary to what a user needs, so breaking it out into the specific functionality might be the right answer.
Other noteworthy options include:
-n: Dry run the command without transferring files--list-only: Only show the list of files thatrsyncwould transfer-P: Show progress per file-v: Show progress overall, outputting information about each file as it completes it-u: Skip updating target files if they are newer than the source-q: Quiet mode. Useful for inclusion in scripting when the terminal output is not required-c: Use a checksum value to determine which files to skip, rather than the modification time and size--existing: Only update files, but don’t create new ones that are missing--files-from=FILE: Read list source files from a text file--exclude=PATTERN: Use PATTERN to exclude files from the sync--exclude-from=FILE: Same as above, but read from a file--include=PATTERN: Also used to negate the exclusion rules--include-from=FILE: Same as above, but read from a file
My personal default set of parameters for rsync end up being -avuP (archive, verbose output, update only new files, and show the progress of the work being done).
Source and targets
The source and target for the sync are files and directories. Also, rsync provides the functionality to interact with remote systems over SSH, which keeps the user from needing to set up network shares to be able to sync files from one place to another. This means you can easily script rsync jobs after configuring SSH keys on both ends, removing the need to manually login in for remote file sync.
Example:
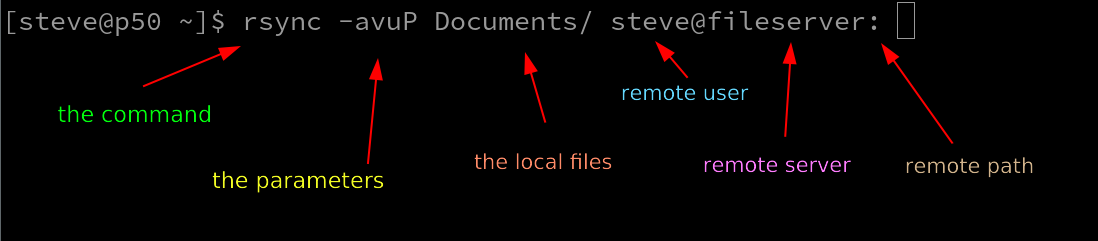
Breaking down the syntax here:
- Running the
rsynccommand - With the
-avuPparameters described above - To copy the local Documents directory
- Using steve as a user on the remote system
- Where the remote system is called fileserver and can be reached by that name
- And the relative path from steve's home is shown after the : - and in this case, it means to put this in steve’s home directory itself
This copies over everything from steve’s Documents folder to the Documents directory on the remote system, only updating files that have changed or are new. Running this once is sufficient (until there are new changes). Running it again immediately afterward should produce relatively the same amount of output but be much faster because it skips all the files.
[ The API owner's manual: 7 best practices of effective API programs ]
Wrap up
There are many useful ways to take advantage of the power of rsync. It's often as simple as running it from the command line on a one-off basis to copy over a set of files without worrying about wasting time copying things that already exist on the destination. Scripting this, adding it to cron jobs, and experimenting with different parameters helps accomplish even more goals for the average sysadmin.
About the author
More like this
Strengthening the open source defense layer: Red Hat joins NVIDIA in the Open Secure AI Alliance
Beyond the blind spots: Defeating frontier AI model threats in your application development process
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds