
Boo! Halloween is finally here. Have you prepared your favorite Halloween costume yet? Or, maybe your kids are preparing to trick-or-treat. It is the year 2020, and this Coronavirus pandemic is probably the scariest thing—even more terrifying than the ghosts and zombies knocking on your door.

When you're a sysadmin, you may encounter some really scary moments that give you goosebumps and sleepless nights, but even the most terrifying ghost, zombie, or monster has a nemesis to run away from, whether it's a Coptic cross, a garlic necklace, a hunk of Kryptonite, or an expert sysadmin. In this article, I will present a few possible scary moments for a sysadmin like you. I'll also tell you how you can handle them. It is Halloween, after all, so think of this list as my Halloween treat for you.
I have also provided this blog on YouTube, you'd like to watch it rather than read more.
Trick #1: Cloud server crash

It is 2 a.m., and your smartphone starts to buzz. Half-awake, you pick up your phone and stare at the screen. Shoot. Your email keeps getting auto-generated notifications from the Slack/Teams message system that your production server has been down for two-to-three hours. The next thing you know, your boss wants you and the rest of the operations team to be there ASAP. This is definitely a situation that you don't want to be in, so how can you prevent it from happening?
[ You might also like: Bash bang commands: A must-know trick for the Linux command line ]
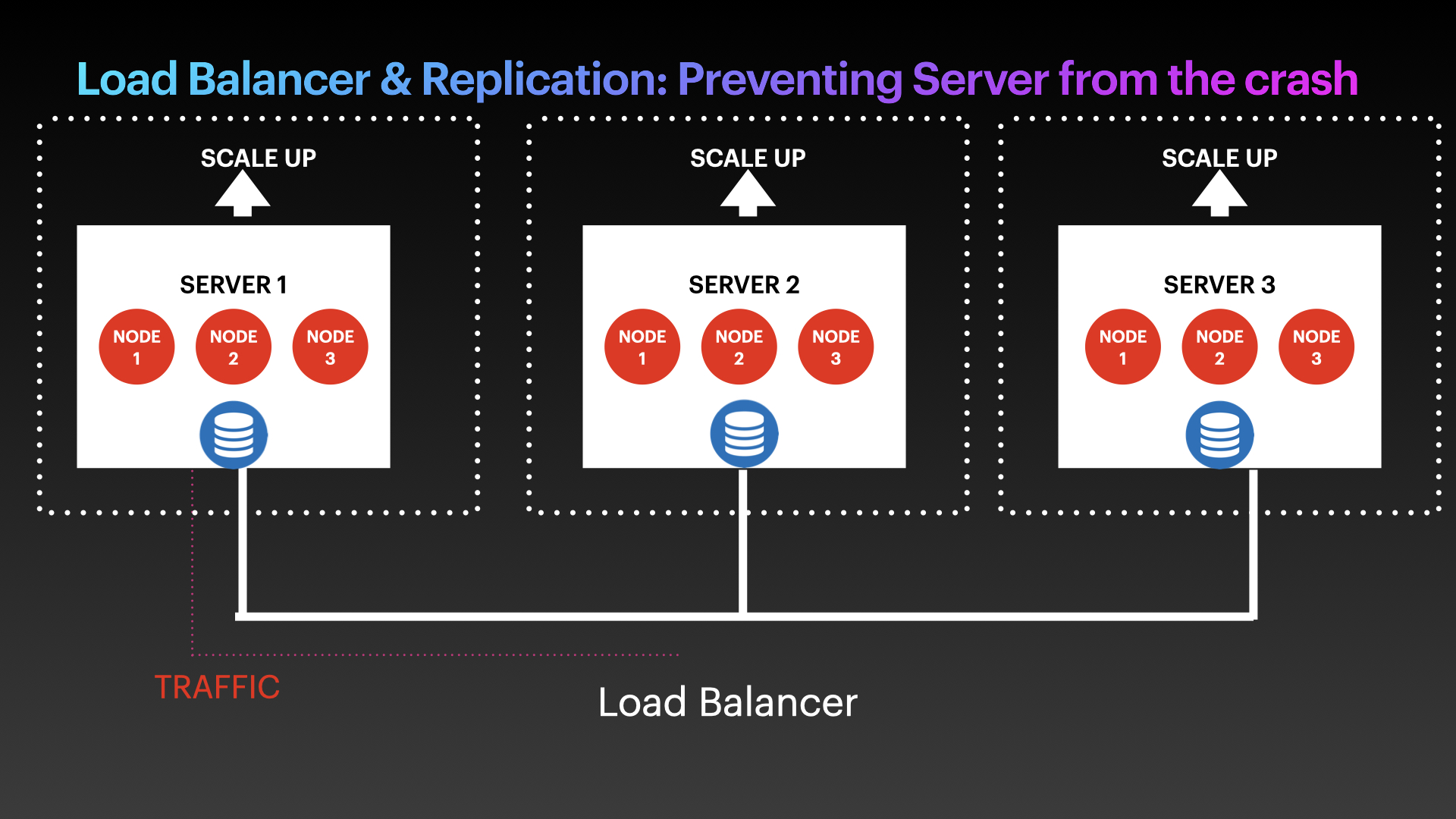
Treat #1: Load balancer and replication: Preventing the server crash
While it is impossible to completely prevent running servers from crashing, it is possible to create a nearly fault-tolerant system if you architect it the right way. One solution is to set up replication across multiple environments with multi-clusters and multi-nodes. You can add a load balancer to ensure that other clusters continue to operate even if one cluster shuts down. If there is too much traffic or other performance problems, you can configure the auto-scale feature to scale up or scale across.
Trick #2: Data corruption or loss

A new intern named Mike joined your engineering team. Excited that he got the tools that he needs, he runs a SQL query with no intention of harming anything. But uh-oh. This little change causes your database table to be deleted, and all the critical customer data is now gone. What can you do to prevent a problem like this from happening?
Treat #2: Data backup and restore: Fix data loss and corruption
Data loss is a serious problem for any live service or application. Thus, the backup and restore strategy always needs to be available, at least for the production environment. Ideally, the backup and restore procedure should be available in all environments. Also, create a mechanism to automate this process. The simplest way you can start is to create some bash scripts to run a series of backup and restore commands.

Trick #3: Application crash

Hooray! Your server and database are now fault-tolerant and rock-solid, but one Java application exposing important business-facing endpoints suddenly blows up. When a customer visits the website, they see only a 404 page, which costs your company a million dollars per minute.
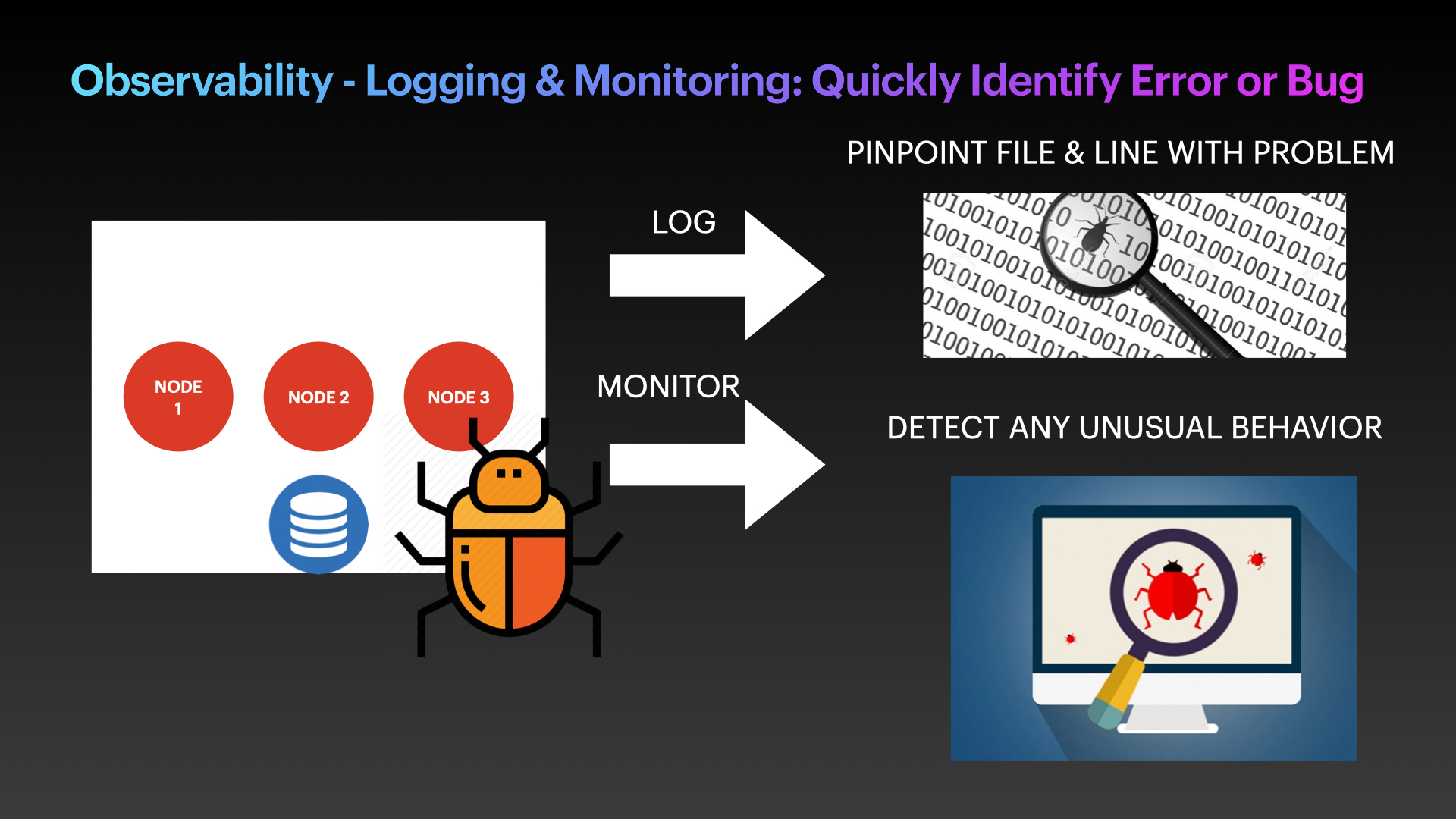
Treat #3: Observability - logging and monitoring: Quickly identify error or bug
Application errors happen all the time, and there are many techniques and programming Design Patterns, like the Circuit Breaker pattern, to handle problems. However, any error running inside the app must be quickly identified before it can be fixed. Thus, logging and monitoring are absolute necessities for all applications. Make sure that your application has debugging points enabled throughout the code blocks and lines. These errors or outputs should be sent to the monitoring dashboards so that developers can quickly pinpoint the problem.
Trick #4: A slow application

You added logging and monitoring for all of the applications. You can finally sleep happy, dreaming about how to win this year's virtual Halloween costume competition. However, a few minutes later, you read an email from a customer stating that the application service really feels slow.
Treat #4: Bottleneck identification dev tools: Discover where the slowdown occurs
Just as a developer can pinpoint the bottleneck quickly with monitoring and logging enabled throughout the applications, you can use developer tools like traceroute/tracert, Chrome browser Developer Tools, and Wireshark to troubleshoot applications and easily identify where performance problems occur. Knowing tools like this can help a developer navigate the challenging problems involved with cloud-based applications.

Trick #5: Slow latency reported in only one location

As you are a master sysadmin, you finally found the cause of the overall application slowness. You fixed the problem, and the customer later sends you a thank you letter stating that everything is good. However, a day later, you get an email from another customer, located in Sydney, Australia, complaining that your company's application feels slow when he visits the site. What is going on?
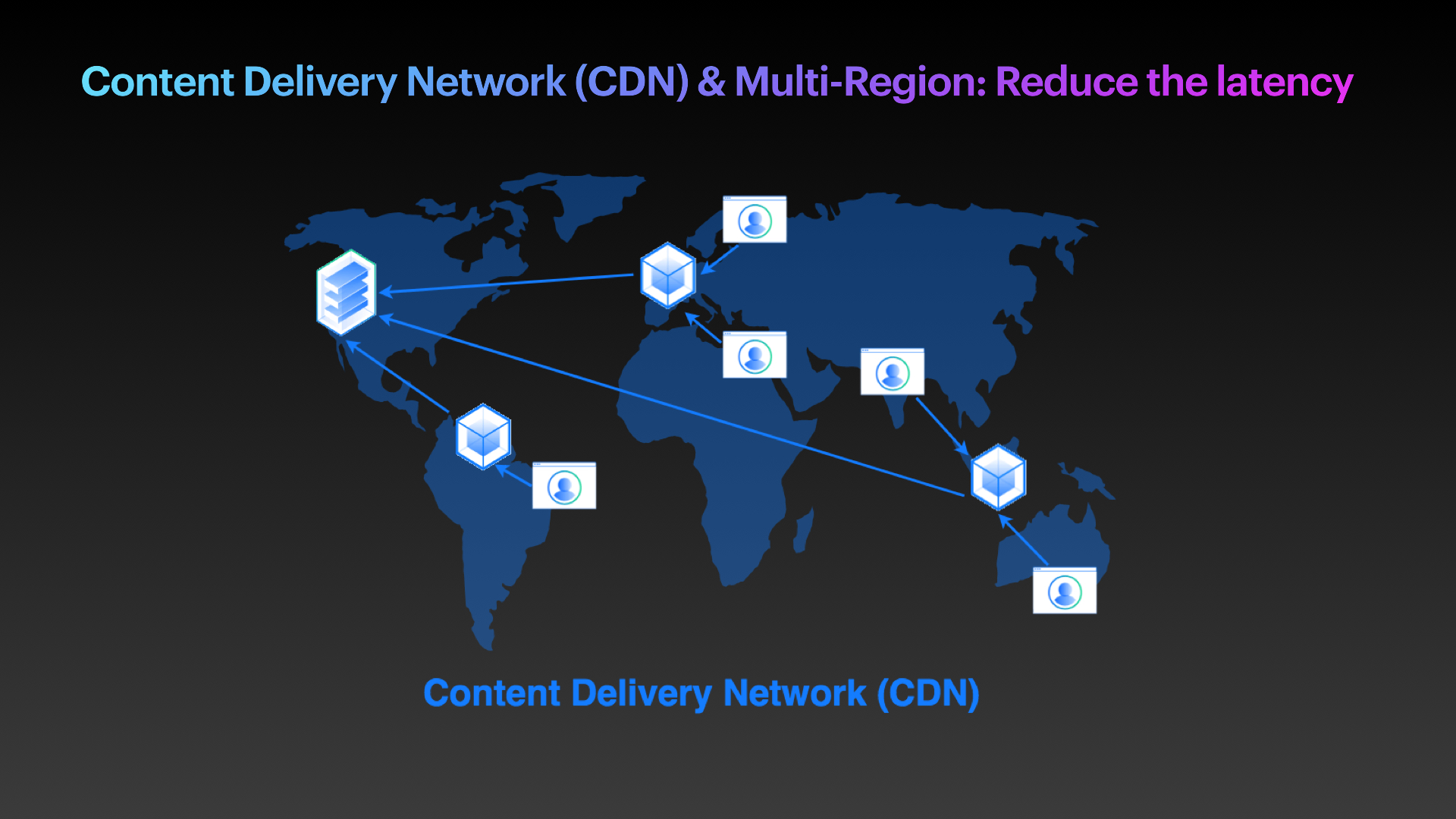
Treat #5: Content Delivery Network (CDN) and multi-region access: Reduce the latency
Although the problem can still be a latency issue due to an application's design, the issue might be with a lack of server availability for the customer in that city or region. One way to solve the problem is to add an additional location for your running services so that the nearest server can be automatically selected to deliver the necessary content to the customer. In other words, a multi-region cluster and Content Delivery Network (CDN) can help to mitigate the problem.
[ Download now: A sysadmin's guide to Bash scripting. ]
Wrap up
That's all folks! You learned how to solve the five most common pain points that you might encounter as a sysadmin when you have applications running in a server or a cloud environment. Problems like these happen all the time, but there are ways to prevent or mitigate the issues appropriately with the right architecture and a good sysadmin approach. I hope this article helped you to become a better sysadmin. Happy Halloween!
About the author
Bryant Jimin Son is a Consultant at Red Hat, a technology company known for its Linux server and opensource contributions. At work, he is working on building the technology for clients leveraging the Red Hat technology stacks like BPM, PAM, Openshift, Ansible, and full stack development using Java, Spring Framework, AngularJS, Material design. Prior to joining Red Hat, Bryant was at Citi Group's Citi Cloud team, building the private Infrastructure as a Service (IaaS) cloud platform serving 8,000+ teams across Citi departments. He also worked at American Airlines, IBM, and Home Depot Austin Technology Center. Bryant graduated with Bachelor of Sciences in Computer Science and Aerospace Engineering with minor concentration in Business at University of Texas at Austin.
He is also the President and Founder of Korean American IT Association group, known as KAITA (www.kaita.org). He is an avid coder spending extra time on building side projects at cafes, and he travels every week on business. He also loves to work out daily and to grow KAITA.
More like this
Planning your path forward from Amazon Linux 2: Why consistency is the ultimate upgrade
Advancing post-quantum capabilities of SSH in Red Hat Enterprise Linux
Operating System Management | Compiler
How Should We Handle Failure? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds