红帽 OpenShift 虚拟化 4.19 显著提升了数据库等 I/O 密集型工作负载的性能和速度。红帽 OpenShift 虚拟化的多 I/O 线程是一项新功能,允许将虚拟机(VM)磁盘 I/O 分散到主机上的多个工作线程中,然后将这些线程映射到虚拟机内的磁盘队列。这使得虚拟机能够高效地将 vCPU 和主机 CPU 用于多流 I/O,从而提高性能。
本文是我同事 Jenfer Abrams 撰写的功能简介的姊妹篇。在本文中,我将提供性能测试结果,以帮助您调优虚拟机,从而实现更高的 I/O 吞吐量。
为了进行测试,我使用 fio 在 Linux 虚拟机上对合成 I/O 工作负载进行了基准测试。目前正在推进其他测试工作,包括应用测试以及在 Microsoft Windows 平台上的测试。
有关如何在基于内核的虚拟机(KVM)中实施此功能的更多背景信息,请参阅这篇关于 IO 线程虚拟队列映射的文章,以及另一篇姊妹文章,该文章展示了在红帽企业 Linux(RHEL)环境中运行的虚拟机中,数据库工作负载的性能改进。
测试说明
我测试了两种配置下的 I/O 吞吐量:
- 使用本地存储 Operator(LSO)置备的逻辑卷管理器实现本地存储的集群
- 使用 OpenShift 数据基础(ODF)的单独集群
这些配置之间差异非常大,无法进行比较。
我们在 pod(作为基准)和虚拟机上进行了测试。虚拟机配置为 16 个核心和 8GB 内存。测试过程中采用了 512GB 测试文件(一个虚拟机)和 256GB 测试文件(2 个虚拟机)。所有测试均使用直接 I/O。对于虚拟机,使用块模式且格式化为 ext4 的持久卷声明(PVC);对于 pod,使用了同样格式化为 ext4 的文件系统模式 PVC。所有测试均通过 libaio I/O 引擎运行。
我测试了以下参数组合:
参数 | 设置 |
存储卷类型 | 本地(LSO)、ODF |
Pod/虚拟机数量 | 1、2 |
I/O 线程数量(仅虚拟机) | 无(基准)、1、2、3、4、6、8、12、16 |
I/O 操作 | 顺序和随机读取与写入 |
I/O 块大小(字节) | 2K、4K、32K、1M |
并发作业数量 | 1、4、16 |
I/O iodepth(iodepth) | 1、4、16 |
我使用 ClusterBuster 来编排测试。虚拟机使用 CentOS Stream 9,pod 同样使用 CentOS Stream 作为容器镜像基础。
本地存储
本地存储集群是一个 5 节点(3 个主节点 + 2 个工作节点)集群,由包含 2 个 Intel Xeon Gold 6130 CPU 的 Dell R740xd 节点组成,每个节点都有 16 个核心和 2 个线程(32 个 CPU),因此总计 32 个核心和 64 个 CPU。每个节点包含 192GB RAM。I/O 子系统由四个戴尔品牌的 Kioxia CM6 MU 1.6 TB NVMe 驱动器组成,这些驱动器采用默认设置的 RAID0 条带化多设备(MD)配置。持久卷声明是使用 lvmcluster operator 从此 MD 中划分出来的。遗憾的是,我目前仅能使用这种相对保守的配置进行测试,若采用更快的 I/O 系统,多 I/O 线程很可能会带来更显著的性能提升。
OpenShift 数据基础
OpenShift 数据基础(ODF)集群是一个 6 节点(3 个主节点 + 3 个工作节点)集群,由包含 2 个 AMD EPYC 9534 CPU 的 Dell PowerEdge R7625 节点组成,每个节点都有 64 个核心和 2 个线程(128 个 CPU),因此总计 128 个核心和 256 个 CPU。每个节点包含 512GB RAM。I/O 子系统配置为每个节点两个 5.8TB NVMe 驱动器,通过 25 GbE 默认 pod 网络进行三向复制。本次测试未采用较快速的网络,但若采用较新的网络硬件,预计可获得更显著的性能提升。
结果摘要
此测试针对具有特定 I/O 后端的多 I/O 线程进行了评估,结果可能不适用于您的用例。存储特征方面的差异,可能会对 I/O 线程数量的选择产生重大影响。
以下是我获得的测试结果。
- 最大 I/O 吞吐量:对于本地存储,pod 和虚拟机的最大读取和写入吞吐量分别约为每秒 7.3GB 和每秒 6.7GB,无论 iodepth 或本地存储上的作业数量如何。该数值远低于硬件预期性能。这些设备(每个具有 4 条 PCIe gen4 通道)标称读取速度为每秒 6.9GB,写入速度为每秒 4.2MB。虽然未深究具体原因,但测试是在过时的硬件上运行的,这可能会造成一定的影响。当前峰值性能明显优于单个驱动器的性能,证明条带化配置确实发挥了作用。对于 ODF,我们实现的最佳读取速度约为每秒 5GB,最佳写入速度约为每秒 2GB。
- 大块 I/O(1MB)几乎没有提升效果,因为性能已受到系统的限制。
- 最佳的 I/O 线程数量因工作负载和存储特征而异。正如预期的那样,没有大量 I/O 并发的工作负载几乎未见改善。
- 本地存储:对于具有大量 I/O 并发的虚拟机,建议一开始将线程数量设置为 4-8 个。尤其是对于 I/O 块大小较小和存在大量并发的工作负载,增加线程数量往往能带来更显著的性能提升。
- ODF:使用超过 1 个 I/O 线程通常难以带来显著的性能提升,许多情况下甚至完全不需要。这可能是由于 pod 网络相对较慢造成的限制;若采用较快的网络连接,可能会产生不同的结果。
- 与深度异步 I/O 相比,多 I/O 线程在多个并发作业场景下更能有效提升性能,至少在本测试中如此。
- 在达到底层聚合最大 I/O 吞吐量(如上所述)之前,运行 1 个和 2 个并发虚拟机的性能表现几乎没有差异。
- 在作业数量或 I/O iodepth 较低的情况下,多 I/O 线程未能完全缩小与 Pod 的性能差距。当 I/O iodepth 较高且操作规模较小时,虚拟机在写入操作方面的实际表现显著超越了 pod。
数字证明一切
以下是我在本地存储系统上使用多 I/O 线程所获得的整体 I/O 吞吐量。如您所见,当工作负载涉及较小的 I/O 块大小且需要高度并行快速 I/O 系统时,多 I/O 线程可带来显著优势。下面我将详细介绍不同数量的 I/O 线程所带来的效益。我注意到当采用 1MB 块大小时性能提升效果微乎其微,因为此时性能已经非常接近底层系统的限制。若采用更快的硬件,即使块大小较大,增加 I/O 线程仍可能会带来性能提升。
相较于虚拟机基准,增加 I/O 线程所能实现的最佳性能提升效果 | ||||||||||
(本地存储) | 作业 | iodepth | ||||||||
1 | 4 | 16 | ||||||||
大小 | 操作 | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | 随机读取 | 18% | 31% | 30% | 30% | 103% | 192% | 151% | 432% | 494% |
随机写入 | 81% | 59% | 24% | 153% | 199% | 187% | 458% | 433% | 353% | |
读取 | 67% | 58% | 25% | 64% | 71% | 103% | 252% | 241% | 287% | |
写入 | 103% | 64% | 0% | 143% | 99% | 84% | 410% | 250% | 203% | |
2048(总计) | 67% | 53% | 20% | 97% | 118% | 141% | 318% | 339% | 334% | |
4096 | 随机读取 | 18% | 34% | 28% | 33% | 101% | 208% | 156% | 432% | 492% |
随机写入 | 95% | 69% | 20% | 149% | 200% | 187% | 471% | 543% | 481% | |
读取 | 26% | 53% | 27% | 24% | 46% | 66% | 142% | 155% | 165% | |
写入 | 103% | 69% | 0% | 144% | 86% | 48% | 438% | 256% | 161% | |
4096(总计) | 60% | 56% | 19% | 87% | 108% | 127% | 302% | 346% | 325% | |
32768 | 随机读取 | 16% | 23% | 26% | 23% | 71% | 124% | 99% | 160% | 129% |
随机写入 | 75% | 71% | 28% | 108% | 132% | 116% | 203% | 123% | 115% | |
读取 | 21% | 57% | 25% | 21% | 42% | 32% | 77% | 54% | 32% | |
写入 | 79% | 64% | 26% | 104% | 59% | 24% | 195% | 45% | 27% | |
32768(总计) | 48% | 53% | 26% | 64% | 76% | 74% | 143% | 96% | 76% | |
1048576 | 随机读取 | 5% | 2% | 0% | 9% | 0% | 0% | 17% | 0% | 0% |
随机写入 | 10% | 0% | 1% | 6% | 0% | 2% | 9% | 0% | 2% | |
读取 | 12% | 18% | 0% | 9% | 0% | 0% | 16% | 0% | 0% | |
写入 | 19% | 0% | 0% | 7% | 0% | 0% | 9% | 0% | 0% | |
1048576(总计) | 11% | 5% | 0% | 8% | 0% | 1% | 13% | 0% | 0% | |
以下是为达到最多 16 个 I/O 线程可实现的最佳结果的 90%,所需的 I/O 线程数量。例如,如果我在测试中通过操作、块大小、作业数量和 iodepth 的特定组合所获得的最佳结果是 1GB/秒,那么此处的指标就是达到 900MB/秒所需的最少线程数量。这使得在设定保守的线程数量时,仍能获得良好的性能表现。
实现 90% 的最佳性能所需的最少 iothread 数量 | ||||||||||
(本地存储) | 作业 | iodepth | ||||||||
1 | 4 | 16 | ||||||||
大小 | 操作 | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | 随机读取 | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
随机写入 | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
读取 | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
写入 | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
2048(总计) | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4096 | 随机读取 | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
随机写入 | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
读取 | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
写入 | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
4096(总计) | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32768 | 随机读取 | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
随机写入 | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
读取 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
写入 | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
32768(总计) | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1048576 | 随机读取 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
随机写入 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
读取 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
写入 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
1048576(总计) | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
详细结果
对于衡量的每个测试案例,我计算了以下性能指标:
- I/O 吞吐量衡量
- 最佳虚拟机性能(未直接报告)
- 达到最佳虚拟机性能的 90% 所需的最低 I/O 线程数量
- 最佳虚拟机性能与 pod 性能之间的比率
- 最佳虚拟机性能相对于基准虚拟机性能的提升幅度
我并未报告最佳性能对应的线程数量,因为在多数情况下,差异微乎其微,甚至小于报告 I/O 性能时的正常波动范围。
鉴于本地存储与 ODF 之间的特征差异明显,我分别提供了两者的结果总结。
下面所有性能图表均显示了以下对象的测试结果:容器集(pod)、未使用 I/O 线程(0)的基准虚拟机以及 X 轴上标注的指定数量的 I/O 线程。
本地存储
如果我们注意观察原始性能数据,就会发现至少在某些情况下,使用多 I/O 线程可带来显著效益。例如,在 16 个作业、iodepth 为 1的异步 I/O 场景下,在本地存储中使用额外的 I/O 线程可带来近一个数量级的性能提升:
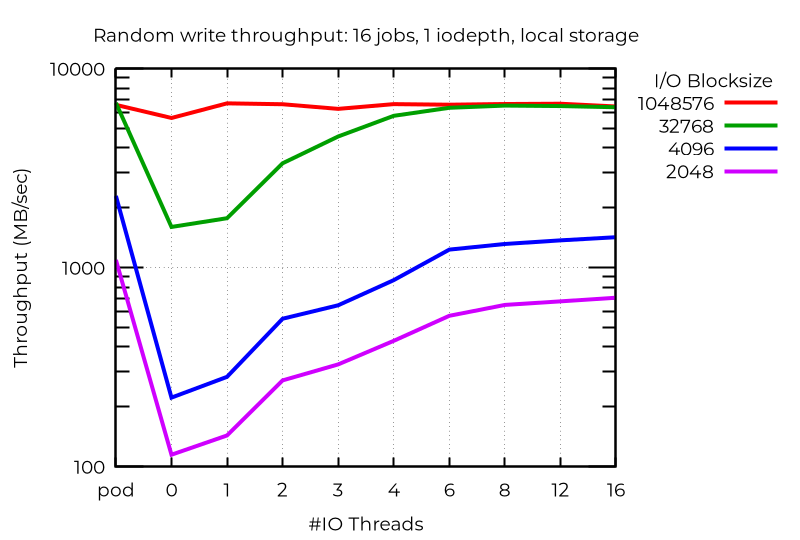
即使仅使用单个流 I/O,使用额外的 I/O 线程也能实现性能提升。不出所料,多个线程并不会带来助益:

在某些异常情况下,额外的 I/O 线程实际上还会损害性能。在这种情况下,使用块大小较小的深度异步 I/O 时,未配置专用 I/O 线程的虚拟机反而能实现最佳性能(甚至优于 pod)。目前尚未查明此现象的具体原因。
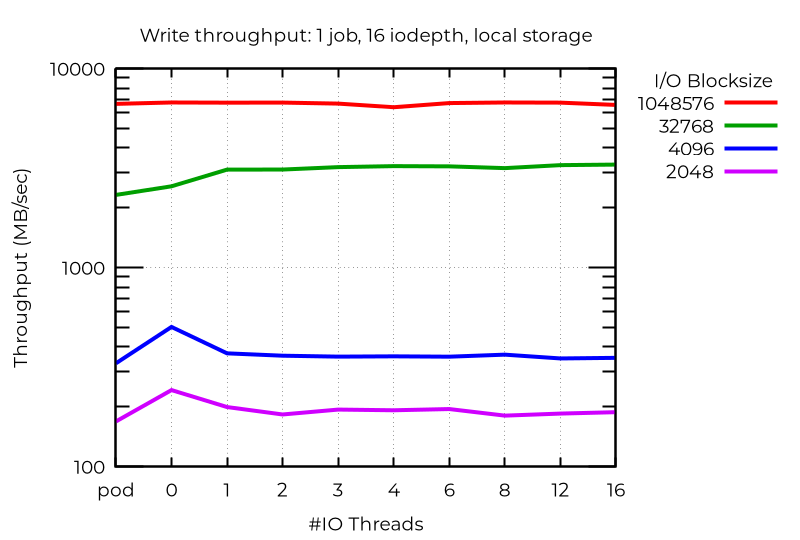
所有这些都表明,要充分发挥多 I/O 线程的最佳性能,您需要针对特定工作负载进行实验。
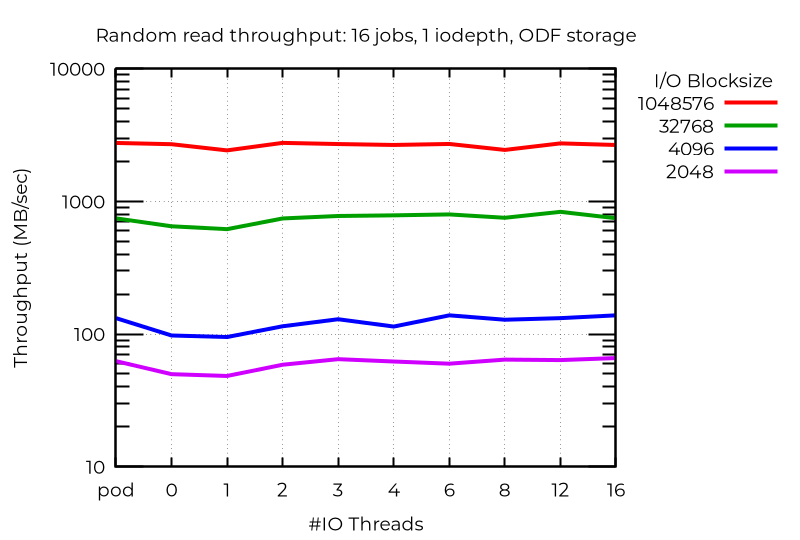
ODF 集群结果
ODF 与本地存储不同,本地存储在使用多 I/O 线程时,小块随机写入性能显著提升;而我观察到即使在作业量较高的情况下,ODF 的性能提升也微乎其微。更快的网络或更低的网络延迟可能会带来更大的效益。读取操作(尤其是随机读取)确实显示出适度性能提升,但写入操作以及低作业量场景几乎未见(如果有的话)性能改善。
结论
OpenShift 虚拟化的多 I/O 线程是 OpenShift 4.19 中一项激动人心的新功能,可为具有并发 I/O 的工作负载带来显著的 I/O 性能提升,尤其是在快速 I/O 系统(如我在测试中使用的本地 NVMe 存储)中。通过采用更快的 I/O 子系统,有望从多 I/O 线程中获得更多效益,因为需要更多 CPU 才能充分驱动底层裸机 I/O。与以往的 I/O 一样,I/O 系统和整体工作负载之间的差异会显著影响性能表现,因此我建议您针对自身工作负载进行测试,以充分利用这项新功能。希望我的测试结果能帮助您针对 I/O 线程做出正确的选择!







