当今时代的 AI 训练,特别是大型模型的训练,同时面临着计算规模和严格数据隐私的双重需求。 传统的机器学习 (ML) 需要集中化训练数据,导致在数据隐私、安全性以及数据效率和数据量方面存在重大障碍和工作量。
在多云、混合云和边缘环境中的异构全球基础架构中,这一挑战更加严峻。因此,企业组织必须使用现有的分布式数据集来训练模型,同时保护数据隐私。
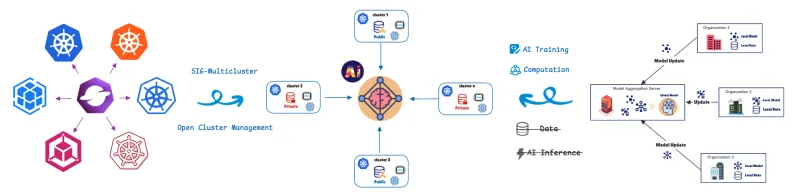
联邦学习 (FL) 通过将模型训练转移到数据中来应对这一挑战。远程集群或设备(协作者/客户端)使用其私有数据在本地训练模型,并且仅将模型更新(而非原始数据)共享回中央服务器(聚合器)。这有助于端到端保护数据隐私。这种方法对于隐私敏感或高数据负载场景至关重要,我们在医疗保健、零售、工业自动化以及具有高级驾驶辅助系统 (ADAS) 和自动驾驶 (AD) 功能的软件定义汽车 (SDV) 中发现了这种情况,例如车道偏离警告、自适应巡航控制和驾驶员疲劳监测。
为了管理和编排这些分布式计算单元,我们利用了开放集群管理 (OCM)的联邦学习自定义资源定义 (CRD)。
OCM:分布式运维的基础
OCM 是一个 Kubernetes 多集群编排平台,也是一个开源的 CNCF 沙箱项目。
OCM 采用中心辐射型架构,并使用基于拉取的模型。
- 中心集群:充当负责编排的中央控制平面(OCM 控制平面)。
- 托管(辐射型)集群:这些是部署工作负载的远程集群。
受管集群从中心拉取其所需状态,并将状态报告回中心。OCM 提供 ManifestWork 和 Placement 等 API 来调度工作负载。我们将在下文中介绍更多联邦学习 API 的详细信息。
现在,我们将了解 OCM 的分布式集群管理设计为何以及如何与部署和管理 FL 贡献者的需求紧密结合。
原生集成:OCM 作为 FL 编排器
1.架构一致性
OCM 和 FL 的结合之所以有效,是因为它们具有根本的结构一致性。OCM 原生支持 FL,因为这两个系统共享相同的基础设计:中心辐射型架构和基于拉取的协议。
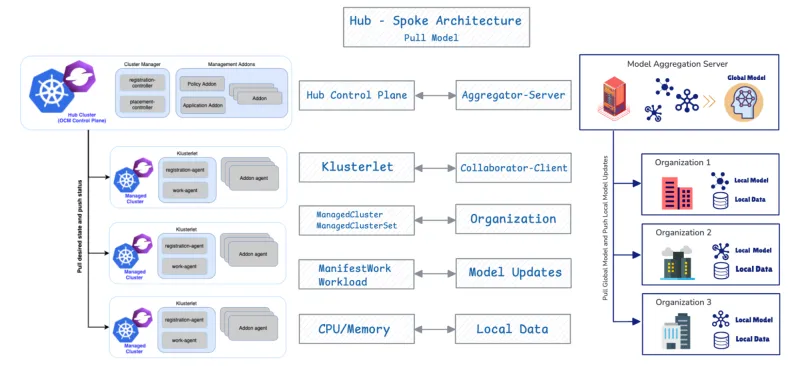
OCM 组件 | FL 组件 | Function |
OCM Hub 控制平面 | 聚合器/服务器 | 编排状态并聚合模型更新。 |
受管集群 | 协作者/客户端 | 拉取所需的状态/全局模型,在本地训练并推送更新。 |
2.灵活放置,方便多角色客户端选择
OCM 的核心运维优势在于,它能够利用其灵活的跨集群调度功能,在 FL 设置中自动选择客户端。此功能使用 OCM Placement API 来实施复杂的多标准策略,同时提供效率和隐私合规性。
放置 API 支持根据以下因素进行集成客户端选择:
- 数据局部性(隐私标准):FL 工作负载仅调度到声明拥有必要私有数据的受管集群。
- 资源优化(效率标准):OCM 调度策略提供灵活的策略,支持对多个因素进行组合评估。它不仅根据数据存在情况来选择集群,还会根据 CPU/内存可用性等公告属性来选择集群。
3.通过 OCM 附加组件注册确保协作者和聚合器之间的安全通信
FL 附加组件协作器部署在托管集群上,并利用 OCM 的附加组件注册机制与中心上的聚合器建立受保护的加密通信。注册后,每个协作者附加组件都会自动从 OCM 中心获取证书。这些证书对 FL 期间交换的所有模型更新进行身份验证和加密,从而跨多个集群实现机密性、完整性和隐私性。
这一过程可以高效地将 AI 训练任务分配到资源充足的集群,从而根据数据位置和资源容量提供集成的客户端选择。
FL 训练生命周期:OCM 驱动的调度
开发了专用的联邦学习控制器,用于跨多个集群管理 FL 的训练生命周期。该控制器利用 CRD 来定义工作流,并支持流行的 FL 运行时(如 Flower 和 OpenFL),并且是可扩展的。
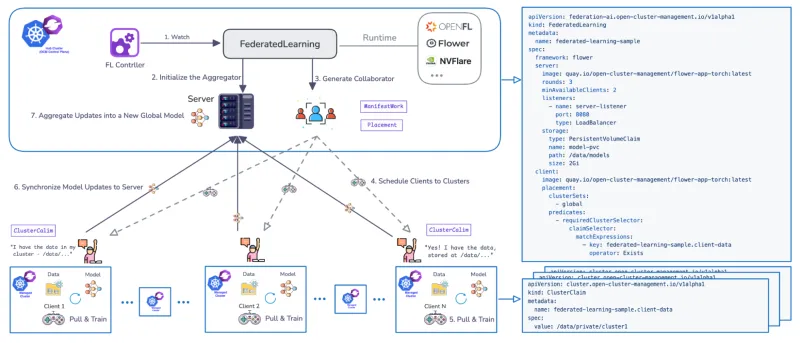

OCM 管理的工作流通过定义的阶段进行:
步骤 | OCM/FL 阶段 | 描述 |
0 | 前提条件 | 联邦学习附加组件已安装。FL 应用作为可部署于 Kubernetes 的容器提供。 |
1 | 联邦学习 CR | 在中心创建自定义资源,定义框架(如 flower)、训练轮数(每一轮是一个完整周期,其中客户端在本地训练并返回更新以进行聚合)、所需的可用训练贡献者数量,以及模型存储配置(例如,指定 PersistentVolumeClaim (PVC) 路径)。 |
2、3、4 | 等待和调度 | 资源状态为“Waiting”。服务器(聚合器)在中心初始化,OCM 控制器使用放置来调度客户端(协作者)。 |
5、6 | 运行中 | 状态更改为“Running”。客户端拉取全局模型,在本地使用私有数据训练模型,并将模型更新同步回模型聚合器。训练轮次参数决定了此阶段的重复频率。 |
7 | 已完成 | 状态变为“Completed”。 可以通过部署 Jupyter Notebook 来执行验证,以对照整个聚合数据集验证模型的性能(例如,确认它预测了所有修改后的美国国家标准与技术研究院 (MNIST) 数字)。 |
红帽高级集群管理:FL 环境的企业控制和运维价值
OCM 提供的核心 API 和架构是红帽 Kubernetes 高级集群管理的基础。红帽高级集群管理可为异构基础架构中的同构 FL 平台(红帽 OpenShift)提供生命周期管理。 在红帽高级集群管理上运行 FL 控制器可提供 OCM 本身无法提供的其他优势。红帽高级集群管理可跨多集群资产提供集中式可见性、策略驱动型治理和生命周期管理,显著增强分布式和 FL 环境的可管理性。
1.可观测性
红帽高级集群管理在分布式 FL 工作流中提供统一的可观测性,使运维人员能够从统一的单一界面监控训练进度、集群状态和跨集群协调。
2.增强连接性和安全性
FL CRD 支持聚合器和客户端之间通过启用了 TLS 的通道进行受保护的通信。它还提供 NodePort 之外的灵活网络选项,包括负载平衡器、路由和其他入口类型,从而在异构环境中提供受保护且适应性强的连接。
3.与红帽高级集群管理和红帽 OpenShift AI 的端到端 ML 生命周期集成
通过利用搭载 OpenShift AI 的红帽高级集群管理,企业可以在统一的平台内构建完整的 FL 工作流,从模型原型设计和分布式训练到验证和生产部署。
总结
FL 正在通过将模型训练直接转移到数据来改变 AI,有效解决计算规模、数据传输和严格隐私要求之间的摩擦。在这里,我们重点介绍了红帽高级集群管理如何提供管理复杂分布式 Kubernetes 环境所需的编排、保护和可观测性。
立即联系红帽,了解如何通过联邦学习为企业赋能。
关于作者

Andreas Spanner leads Red Hat’s Cloud Strategy & Digital Transformation efforts across Australia and New Zealand. Spanner has worked on a wide range of initiatives across different industries in Europe, North America and APAC including full-scale ERP migrations, HR, finance and accounting, manufacturing, supply chain logistics transformations and scalable core banking strategies to support regional business growth strategies. He has an engineering degree from the University of Ravensburg, Germany.

Meng Yan is a Senior Software Engineer at Red Hat, specializing in event-driven architectures for multi-cluster management at scale. His research interests focus on agentic AI systems and intelligent automation for software engineering, as well as AI/ML applications in distributed environments such as federated learning and multi-cluster inference.






