红帽 OpenShift 虚拟化可帮助消除工作负载障碍,以云原生方式统一虚拟机(VM)部署和管理及容器化应用。我们作为性能和规模团队的一员,自 KubeVirt 开源项目初期起,就深入参与了对 OpenShift 上运行的虚拟机的测量和分析,并帮助推动了产品的日益成熟,包括新功能评估、工作负载调优和规模测试。本文将深入探讨我们的几个重点领域,并分享有关在 OpenShift 上运行和调优虚拟机工作负载的其他见解。
调优和扩展指南
我们的团队撰写调优和扩展文档,帮助客户充分利用虚拟机部署。首先,我们编写了一份全面的调优指南,详见这篇知识库文章。这份指南介绍了优化虚拟化控制平面以实现高 VM“突发”创建率的建议,并讲解了主机和 VM 级别上的各种调优选项,以提高工作负载性能。
再者,我们发布了深度参考架构 ,其中包括示例 OpenShift 集群、红帽 Ceph 存储(RHCS)集群和网络调优详细信息。其中还涉及了示例虚拟机部署和启动风暴计时、I/O 延迟扩展性能、虚拟机迁移和并行性,以及大规模执行集群升级。
团队重点关注领域
以下几节概述了我们的一些主要关注领域,并详细介绍了我们为表征和改进 OpenShift 上运行的虚拟机的性能而进行的测试。下面的图 1 说明了我们的重点关注领域。
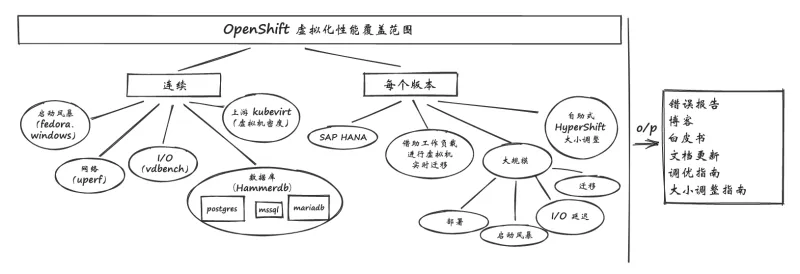
图 1:OpenShift 虚拟化性能重点关注领域
工作负载性能
我们投入了很多时间专注于关键工作负载,包括计算、网络和存储组件,以确保我们的覆盖面足够广。其中包括收集不同硬件模型的连续基线,在新版本发布时更新结果,并深入研究各种调优选项以实现最佳性能。
工作负载的一个重点关注领域是数据库性能。我们通常使用 HammerDB 作为工作负载驱动程序,并专注于多种数据库类型,包括 MariaDB、PostgreSQL 和 MSSQL,因此我们可以了解具有不同特征的数据库的表现。此模板 提供了一个示例 HammerDB 虚拟机定义。
工作负载的另一个主要关注领域是高吞吐量内存数据库 SAP HANA,目标是将与裸机性能的差距控制在 10% 以内。为此,我们在主机和虚拟机层应用了一些隔离式调优,包括使用 CPUManager、调整由 systemd 控制的进程关联、使用大页支持虚拟机,以及使用 SRIOV 网络附加。
为了进一步提升存储性能,我们使用 Vdbench 工作负载运行了一组不同的 I/O 应用模式,重点关注 IOPs(每秒输入/输出操作数)和延迟。应用模式会改变块大小、I/O 操作类型、文件和目录的大小和数量,并调整读取和写入的混合。这使我们能够涵盖各种 I/O 行为,以了解不同的性能特征。我们还运行另一个常见的存储微基准测试 Fio,以测量各种存储配置文件。我们测试了多个持久存储提供程序,但我们的主要关注点是OpenShift Data Foundation ,在虚拟机中使用块 模式 RADOS 块设备(RBD)卷。
我们还专注于不同类型的微基准测试,以评估其他组件的性能,从而完善其中一些更复杂的工作负载。对于联网,我们通常使用 uperf 工作负载来测量各种消息大小和线程数的 Stream 和 RequestResponse 测试配置,重点关注默认的 podnetwork 和其他容器网络接口(CNI)类型,如 Linux 网桥和 OVN-Kubernetes 附加网络。对于计算测试,我们会根据重点领域,使用各种基准测试,如 stress-ng、blackscholes、SPECjbb2005 等。
回归测试
借助一个名为 benchmark-runner 的自动化框架,我们持续运行工作负载配置,并将结果与已知基线进行比较,以捕获和修复 OpenShift 虚拟化预发行版本中的任何回归问题。由于我们关注虚拟化性能,因此我们在裸机系统上运行这个持续测试框架。我们将工作负载与各种容器集、虚拟机和沙盒容器上的类似配置进行比较,以帮助我们了解相对性能。这种自动化框架使我们能够快速安装新的 OpenShift 预发行版本和所关注的 Operator,包括 OpenShift 虚拟化、OpenShift Data Foundation、本地存储 Operator 和 OpenShift 沙盒容器。每周多次对预发行版本的性能进行表征,使我们能够在向客户发布版本之前尽早发现任何回归问题,并在我们更新到具有改进功能的新版本时比较性能随时间的改进。
我们一直在扩大持续自动化工作负载的覆盖范围,而我们目前定期运行的工作负载集合包括数据库基准测试、计算微基准测试、uperf、Vdbench、Fio 以及虚拟机“启动风暴”和容器集启动延迟测试,涉及集群的多个方面,以衡量一次性启动大批量容器集或虚拟机的速度。
迁移性能
通过使用支持 RWX 访问模式的共享存储提供程序,虚拟机工作负载可以在集群升级期间更加无缝地实时迁移 。我们一直致力于提高虚拟机迁移速度,确保工作负载不会出现重大中断。其中包括测试和推荐迁移限值和策略以提供安全的默认值,测试更高的限值以发现迁移组件瓶颈。我们还衡量创建专用迁移网络的优势,并分析节点级网络和每虚拟机迁移指标 ,以表征网络上的迁移进度。
扩展性能
我们会定期测试大规模环境,以发现任何瓶颈并评估调优选项。我们的规模测试涉及 OpenShift 控制平面规模、虚拟化控制平面规模、工作负载 I/O 延迟扩展、迁移并行、DataVolume 克隆和虚拟机“突发”创建调优等诸多领域。
在整个测试过程中,我们发现了各种与规模相关的错误,并最终实现了改进,使我们能够更好地推进下一轮的规模测试。我们在通用调优和扩展指南中记录了在此过程中发现的任何与规模相关的最佳实践。
托管集群性能
我们的一个新兴关注领域是托管控制平面和托管集群性能,特别是在使用 KubeVirt 集群提供程序的 OpenShift 虚拟化上检查本地裸机托管控制平面和托管集群时。
我们的一些初步工作领域包括:对多个 etcd 实例进行规模测试(请参阅重要信息 部分中的存储建议),使用繁重的 API 工作负载进行托管控制平面规模测试,测试在 OpenShift 虚拟化上管理托管控制平面集群时托管工作负载的性能。查看我们的托管集群大小调整指南 ,了解近期工作的主要成果之一。
后续进展
敬请关注即将发布的后续博文,其中将更详细地阐述性能和规模领域,包括深入探讨托管集群大小调整指导方法和深入的虚拟机迁移调优建议。
与此同时,我们将继续测量和分析 OpenShift 上虚拟机的性能,突破新的规模界限,并专注于在版本到达客户手中之前发现和修复任何回归问题!
关于作者

Jenifer joined Red Hat in 2018 and leads the OpenShift Virtualization Performance team. Previously, she spent a decade working at IBM in the Linux Technology Center focused on Linux Performance.






