This post was written by: Swati Sehgal, Alexey Perevalov, Killian Muldoon & Francesco Romani
At the node level, resource alignment is handled by Topology Manager, a native part of Kubelet. By default Kubelet won’t try to apply any specific constraints, but a Topology Manager policy can be set to enforce resource alignment. Part 1 of this blog is here.
Topology Manager is the key part of Kubernetes’ resource topology management system. It makes sure that Pods get resources with the correct alignment as they enter runtime. Kubelet is necessarily kept from knowing everything about a cluster, however. The knowledge gap can result in failures, from unexpectedly low performance to stopping an application completely.
This system works well once a pod lands on a node. Kubelet can take into account available resources and make sure that pods get the best possible alignment. What Kubelet can’t do, however, is tell us whether there’s a better resource alignment available elsewhere in the cluster. This is a job for the Scheduler.
Working in concert: Topology Manager and Topology Aware Scheduling.
The worst-case scenario for resource topology today comes when there’s a complete mismatch between the workload request and the policy set on the compute node. If Kubelet is trying to enforce a “single-numa-node” policy for Resource Topology, this sort of mismatch can cause pod failure. This presents in the cluster as a Topology Affinity Error.
Take a heavy workload (Pod 1) requesting 20 dedicated CPUs in its Pod spec, and two worker Nodes, Node A with 20 total cores, 10 in each NUMA zone, and Node B with 40 total cores, 20 in each NUMA Zone. Both Node A and Node B are running the single-numa-zone policy.

Figure 1: Diagram of Machines Layout
It may be clear from the diagram above that only Node B can meet the resource requirements of Pod Spec 1, but it’s not at all clear from the scheduler’s point of view when it reads the Kubernetes API. Here’s what it sees:

Figure 2: Diagram of Kube-Scheduler’s View
With Topology Manager enabled, the scheduler sees both Node A and Node B as suitable platforms for running Pod 1. However, when Pod 1 is deployed to Node A, we get a “Topology Affinity Error.” This prevents the workload from running and can have knock on effects in the cluster. For more discussion of this issue, see scheduler being topology-unaware can cause runaway pod creation.
If we enable Topology Aware Scheduling, the scheduler begins to see the resource topology complexity that underlies the simplified node-level resource view. With Topology Awareness enable in the scheduler, this is what it sees:

Figure 3: Diagram of Scheduler’s View With Topology Aware Scheduling
The above view means the scheduler will not deploy Pod 1 to Node A, avoiding the Topology Affinity Error. The situation described in the above article becomes increasingly likely as more distinct resource requests are added to a Pod spec and more heterogeneous types of machines are added to the cluster.
For more information on Topology Manager see Kubernetes Topology Manager Moves to Beta - Align Up!
What does this add to Kubernetes?
Topology Aware Scheduling is designed to power new kinds of workloads to function on bare- metal Kubernetes clusters.
The design is primarily concerned with offering coherent, predictable resource alignment decisions in a Kubernetes cluster. With it, enabled workloads should never be placed on platforms that cannot meet their resource needs aligned to their topology preferences.
High-performance and low-latency computing rely on almost absolute resource guarantees to enable predictable performance. These workloads are tuned to make sure the absolute maximum performance can be squeezed from a platform, with the minimum amount of disruption over the lifetime of the workload.
In Kubernetes today, NUMA-based servers require significant workarounds in order to deliver that performance. Either something outside of Kubernetes implements the constraints – such as having virtualized nodes – or the flexibility of Node and Pod configuration is reduced.
Packet processing workloads, like those found in 5G core and edge networks and machine learning workloads, are the first targets for Resource Topology alignments. But there are lots of workloads out there that may benefit from the kind of guarantees the system is able to offer.
How is this all going to work?
We’ll be doing a deep dive later in the series on what’s really going to drive Topology Aware Scheduling. From a high level, there are three components the make up the solution:
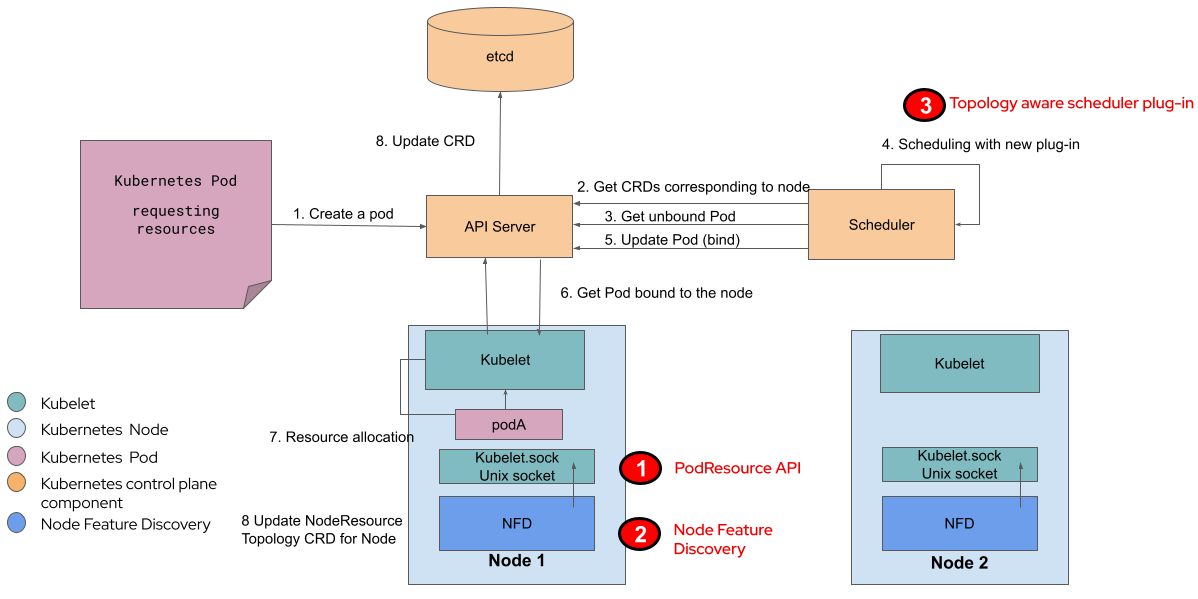
Figure 4: System Level Diagram of Topology-Aware Scheduling (click image for full size)
1) Kubelet is responsible for making information on existing Resource Topology available through the PodResource API. This API is being enhanced as part of the work on Topology Aware Scheduling.
2) Node Feature Discovery will read from the Kubelet endpoint and make Resource Topology information available through Custom Resources (CRs) corresponding to the nodes in the cluster.
3) Kubernetes Scheduler reads the information exported by Node Featured Discovery and blocks scheduling to nodes that can not satisfy the needs of specific workloads.
Topology Aware Scheduling integrates with existing Kubernetes components, including the community sponsored Node Feature Discovery, to offer a drop-in solution for cluster-level topology management:
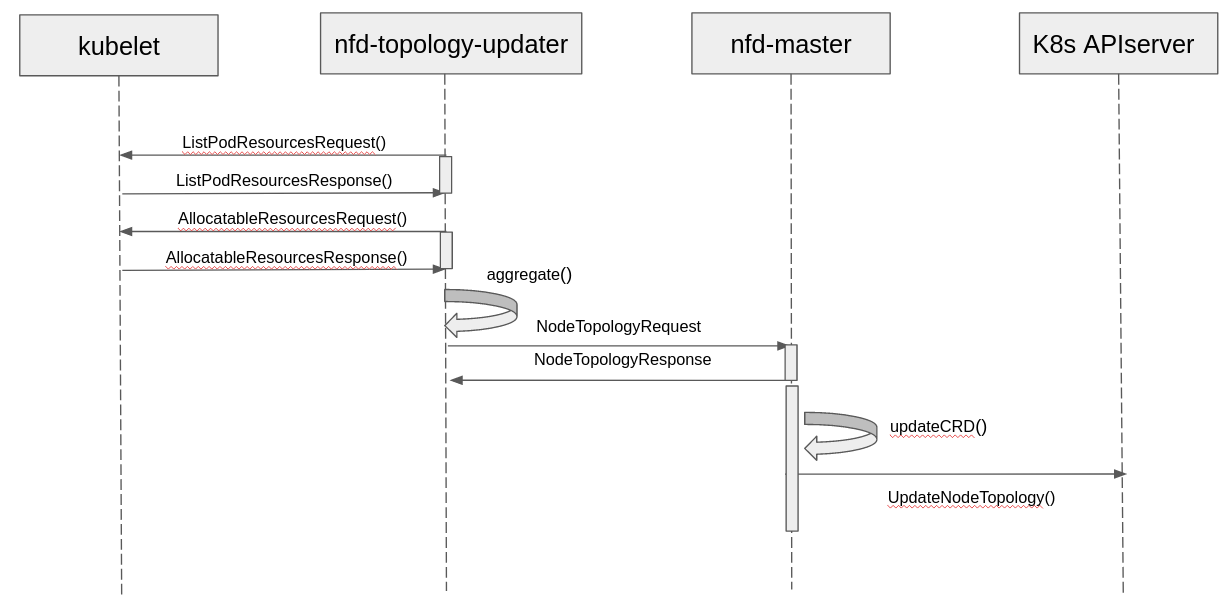
Figure 5: Sequence Diagram of Topology-Aware Scheduling (click image for full size)
The components communicate with each other through Kubernetes APIs.
Look out for more articles in this series, which will trace Resource Topology management from the node all the way up to the scheduler.







