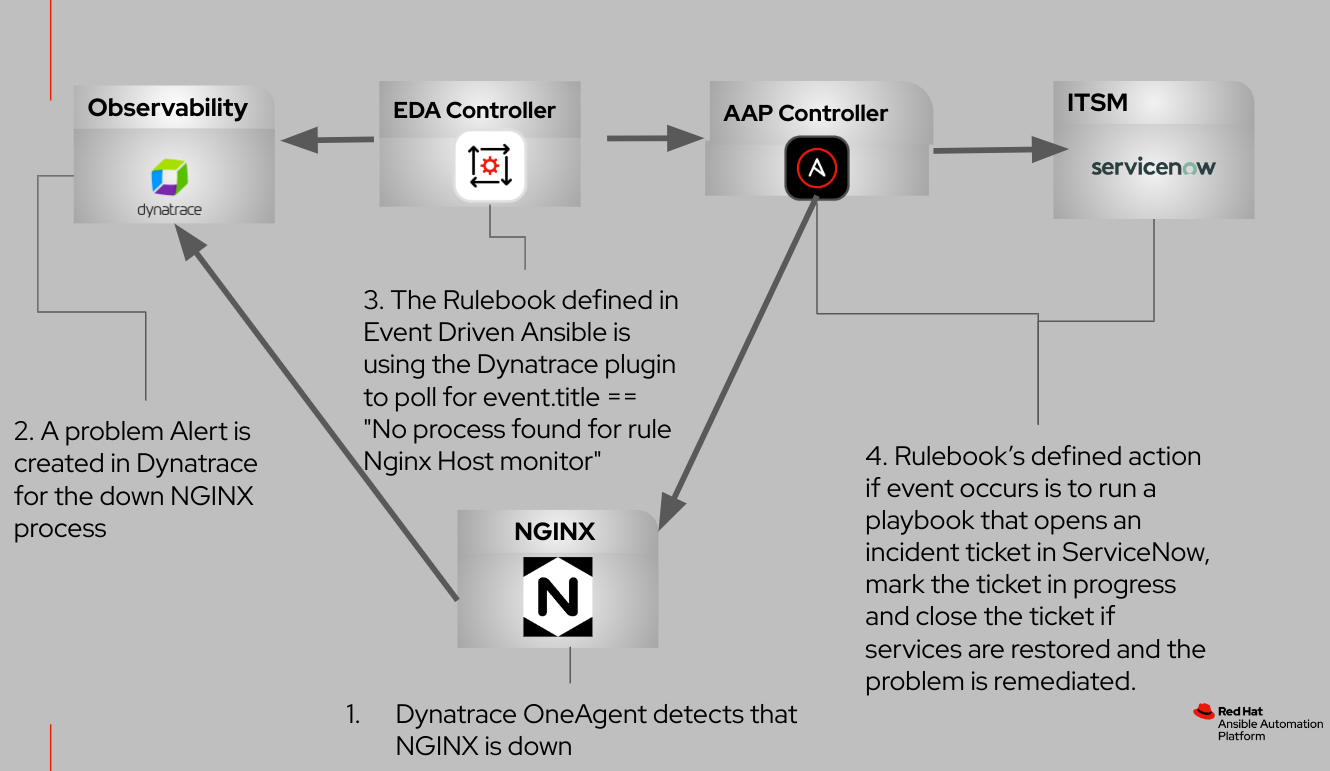
在现代 IT 运维领域,将可观测性工具与自动化进行集成至关重要,因为这能够促进可见性与效率之间的共生关系。借助可观测性工具,企业能够深入了解复杂系统的性能、健康状况和行为,从而在问题升级之前主动识别和纠正问题。
与自动化框架无缝集成后,这些工具能够协助企业实时监控动态变化并及时做出响应。这种可观测性与自动化之间的协同作用,使 IT 团队可以快速适应不断变化的条件,最大限度地减少停机时间,同时优化资源利用率。通过基于可观测性数据自动做出响应,企业能够增强敏捷性、减少人工干预,并维护一个可靠且富有弹性的基础架构。从本质上讲,在当今快节奏且复杂的技术环境中,若要实现主动、灵敏且精简的运维环境,将可观测性与自动化结合至关重要。
本文将介绍一个涉及同时监控裸机和虚拟机上进程的常见用例。我们将重点关注利用 Dynatrace 的 OneAgent,这是一个部署在主机上的二进制文件,内含一套专为环境监控精心配置的专业服务。这些服务能主动收集遥测指标,获取关于主机各个方面的见解,包括硬件、操作系统和应用进程等。
在这个用例中,我们的目标是专门为 NGINX Web 服务器进程建立一个主机级监控器。我将引导您完成事件驱动的 Ansible 的实施过程,这是一个通过定义的规则将事件源与相应操作链接起来的框架。在本例中,事件源是 Dynatrace。
完成配置后,我们将对以下场景进行模拟:
- NGINX Web 服务器遇到服务器上的计划外停机。
- 在 Dynatrace OneAgent 的协助下,进程监控器及时检测到出错的 NGINX 进程,并在 Dynatrace 平台中生成问题警报。
- Dynatrace 源插件主动轮询故障事件,如事件驱动的 Ansible 使用的 Rulebook 中所定义。
- 在响应事件时,事件驱动的 Ansible 会执行一个作业模板来采取以下操作:
- 开始创建 ServiceNow 事件工单。
- 尝试重新启动 NGINX 进程。
- 将事件工单状态更新为“进行中”。
- 仅在 NGINX 进程成功恢复时才关闭工单。
下方流程图演示了这些集成组件之间的交互。
在开始之前,我们先熟悉一些与事件驱动的 Ansible 核心概念相一致的术语:

术语:
Ansible Rulebook 同时包含了事件源和基于规则的详细说明,这些说明阐述了在满足特定条件时要执行的操作,为用户提供了高度的灵活性。
决策环境是一种容器镜像,旨在执行事件驱动的 Ansible 控制器中使用的 Ansible Rulebook。
事件源插件通常在 Python 中构建,用于满足从指定的事件源收集事件的需求。此外,插件通过红帽 Ansible 认证内容集进行分发。
我们需要构建一个决策环境。 请参见下方的构建文件示例:
---
version: 3
images:
base_image:
name: registry.redhat.io/ansible-automation-platform-24/de-minimal-rhel8:latest
dependencies:
galaxy:
collections:
- ansible.eda
- dynatrace.event_driven_ansible
system:
- pkgconf-pkg-config [platform:rpm]
- systemd-devel [platform:rpm]
- gcc [platform:rpm]
- python39-devel [platform:rpm]
options:
package_manager_path: /usr/bin/microdnf有关构建决策环境的更多指导,请参阅提供的文档。创建决策环境后,请继续将容器镜像推送到指定的镜像存储库,然后将镜像拉取到事件驱动的 Ansible 控制器。
建立决策环境后,您将在事件驱动的 Ansible 控制器中创建规则激活。这种激活将定义事件源,并提供在特定条件下要执行操作的详细说明,从而对 Rulebook 进行封装。与自动化控制器中项目内整理 playbook 的方式类似,事件驱动的 Ansible 控制器使用项目来管理和容纳 Rulebook。
在下方,您将找到一个标准的目录层次结构,用于在 Git 存储库中整理和存储 Rulebook 与 playbook。

在事件驱动的 Ansible 控制器中创建项目后,我们需要创建 Rulebook 激活,这是一个由决策环境中运行的 Rulebook 所定义的后台进程。

对于本用例,我们将构建一个 Rulebook,把 Dynatrace 插件用作 Ansible 事件源。此外,我们还要指定在满足特定条件时要执行的操作。
通常,源插件有三种集成模式:
- 轮询
- webhook
- 消息传递
在我们的用例上下文中,Dynatrace 源插件根据 Rulebook 中所概述的指定条件进行主动轮询,进而高效地检索事件。此轮询机制引入了 Dynatrace 插件固有的 delay 变量,如 Rulebook 中所述(请参阅 delay 变量设置)。
在实施限流机制以调节插件行为的过程中,这种延迟起着关键作用。从本质上讲,它将 API 调用编排为按照预定义的间隔执行,使得插件能够依据收到的响应生成新事件。事实证明,这种经过有意安排的 API 调用节奏,有助于对整个工作流进行管理和优化,降低遭遇速率限制的风险,同时确保系统能够顺畅运行。
请参阅下方 Rulebook:
---
- name: Watching for Problems on Dynatrace
hosts: all
sources:
- dynatrace.event_driven_ansible.dt_esa_api:
dt_api_host: "{{ dynatrace_host }}"
dt_api_token: "{{ dynatrace_token }}"
delay: "{{ dynatrace_delay }}"
rules:
- name: Look for open Process monitor problem
condition: event.title == "No process found for rule Nginx Host monitor"
action:
run_job_template:
name: Fix Nginx and update all
organization: "Default"
job_args:
extra_vars:
problemID: "{{ event.displayId }}"
reporting_host: "{{ event.impactedEntities[0].name }}"注:红帽不对此代码的正确性提供明确的支持声明。除非另有说明,否则所有内容均视为不受支持。
在上面的 Rulebook 中,YAML 中有两个键需要注意。其一是 rules 部分中的 condition 键。注意到 event.title 等于“No process found for rule Nginx Host monitor”。但是,这个字符串是从哪里获取的?
其二,看看 action 部分下的 reporting_host 变量。此处,我们将调用要在自动化控制器中运行的作业模板。从哪里获取 event.impactedEntities[0].name?
我们将更深入地研究,以揭示这些键在事件驱动的自动化流程中的定义和用法。
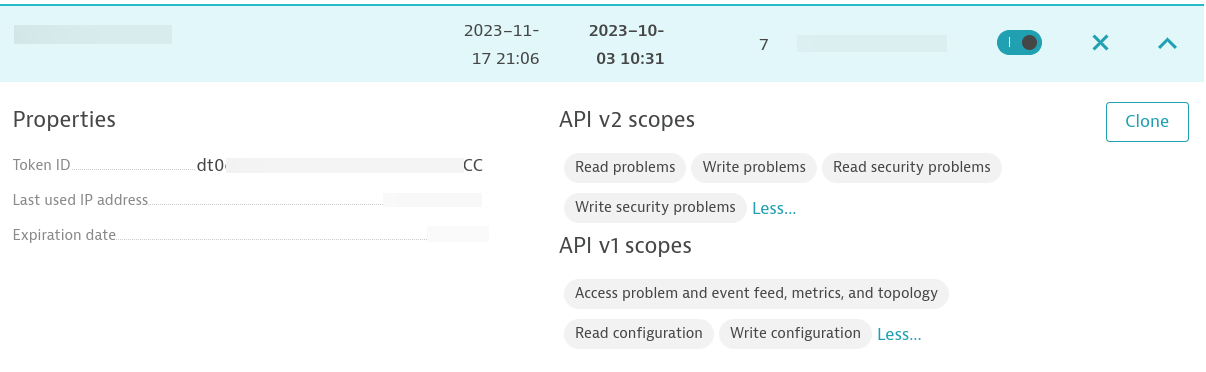
在目标主机上安装了 Dynatace OneAgent 后,您需要创建一个访问令牌。确保这个令牌具有以下权限:
您需要为 NGINX 进程配置主机级进程可用性监控规则。确保运行 NGINX 的主机名与自动化控制器内清单中指定的主机名一致。
在设置了监控器后,您可以终止托管主机上的 NGINX 进程,从而测试事件驱动的 Ansible 中的 Rulebook 激活所轮询的有效负载。
请参阅事件驱动的 Ansible 中有效负载的示例规则审计:
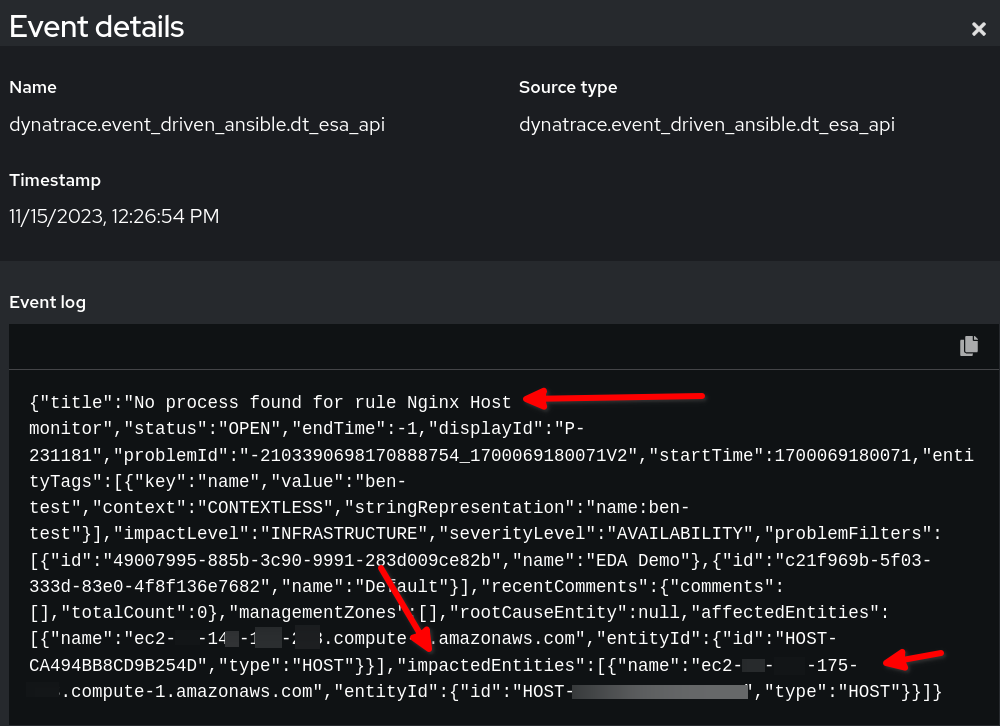
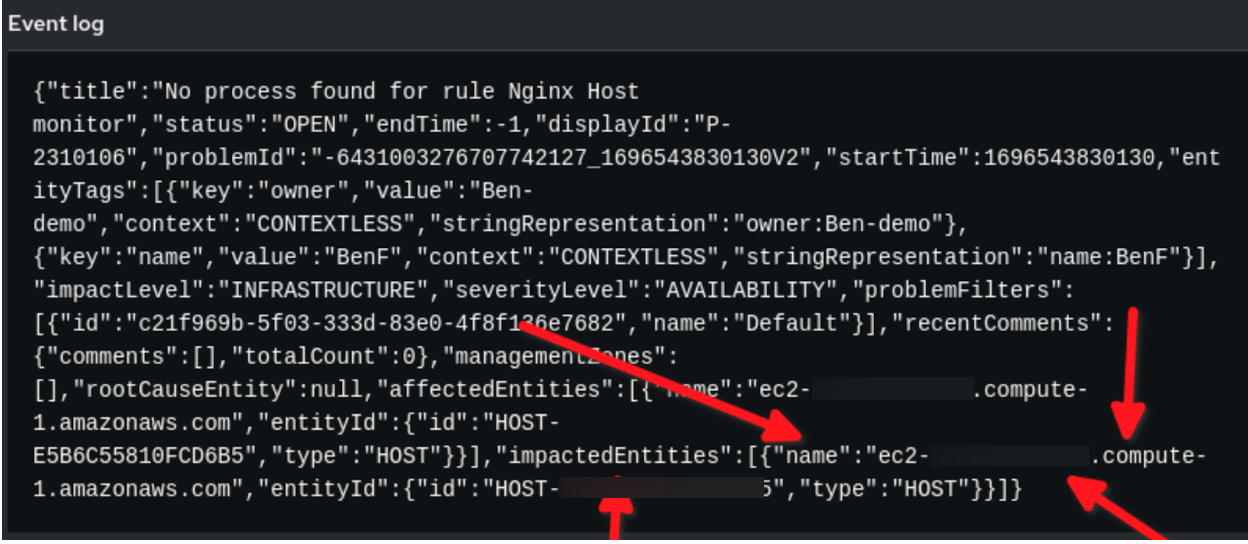
在以上示例中,您看到来自 Dynatrace 的有效负载事件数据采用了 JSON 格式。我们将 event.title 中设置的字符串用作我们的条件,而 reporting_host 变量则由 event.impactedEntities[0].name 值动态设置。请注意,impactedEntities.name[0].name 可以是多个主机。
我们已经知道如何设置 condition 键值和 report_host 变量,接下来该做什么?
要对在自动化控制器中作为作业模板执行的 playbook 进行评估,此刻正是一个好时机。当 Dynatrace 检测到事件驱动的 Ansible 报告 NGINX 进程停机而触发的事件有效负载时,可以使用此 playbook:
---
- name: Restore nginx service create, update and close ServiceNow ticket after Ansible restores services
hosts: "{{ reporting_host }}"
gather_facts: false
become: true
vars:
incident_description: Nginx Web Server is down
sn_impact: medium
sn_urgency: medium
tasks:
- name: Create an incident in ServiceNow
servicenow.itsm.incident:
state: new
description: " Dynatrace reported {{ problemID }}"
short_description: "Nginx is down per {{ problemID }} on {{ reporting_host }} reported by Dynatrace nginix monitor."
caller: admin
urgency: "{{ sn_urgency }}"
impact: "{{ sn_impact }}"
register: new_incident
delegate_to: localhost
- name: Display incident number
ansible.builtin.debug:
var: new_incident.record.number
- name: Pass incident number
ansible.builtin.set_fact:
ticket_number: "{{ new_incident.record.number }}"
- name: Try to restart nginx
ansible.builtin.service:
name: nginx
state: restarted
register: chksrvc
- name: Update incident in ServiceNow
servicenow.itsm.incident:
state: in_progress
number: "{{ ticket_number }}"
other:
comments: "Ansible automation is working on {{ problemID }}. on host {{ reporting_host }}"
delegate_to: localhost
- name: Validate service is up and update/close SNOW ticket
block:
- name: Close incident in ServiceNow
servicenow.itsm.incident:
state: closed
number: "{{ ticket_number }}"
close_code: "Solved (Permanently)"
close_notes: "Go back to bed. Ansible fixed problem {{ problemID }} on host {{ reporting_host }} reported by Dynatrace."
delegate_to: localhost
when: chksrvc.state == "started"“红帽不对此代码的正确性提供明确的支持声明。除非另有说明,否则所有内容均视为不受支持”
需要强调的是,自动化控制器中建立的作业模板名称必须与 Rulebook run_job_template 部分中指定的名称一致。在本用例示例的上下文中,我选择将调查融合到作业模板中,在启动时为从 Rulebook 传递过来的 problemID 和 reporting_host 变量启用提示。
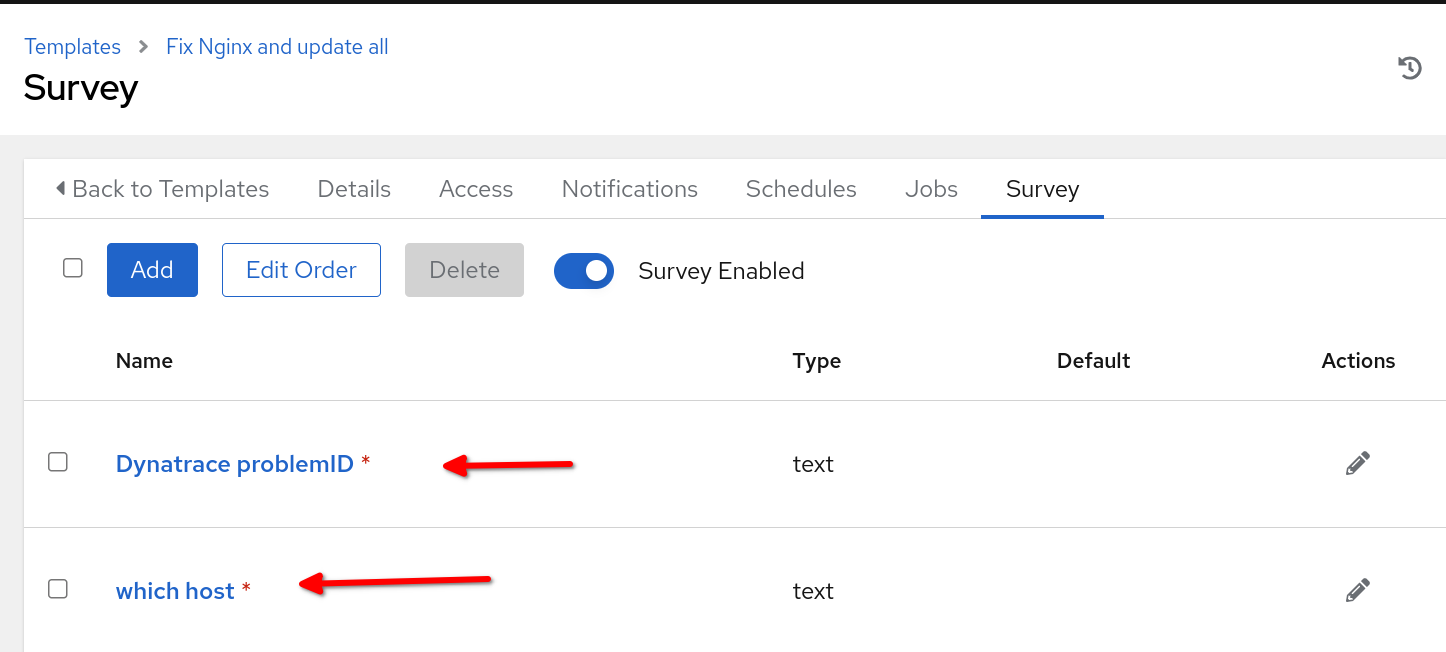
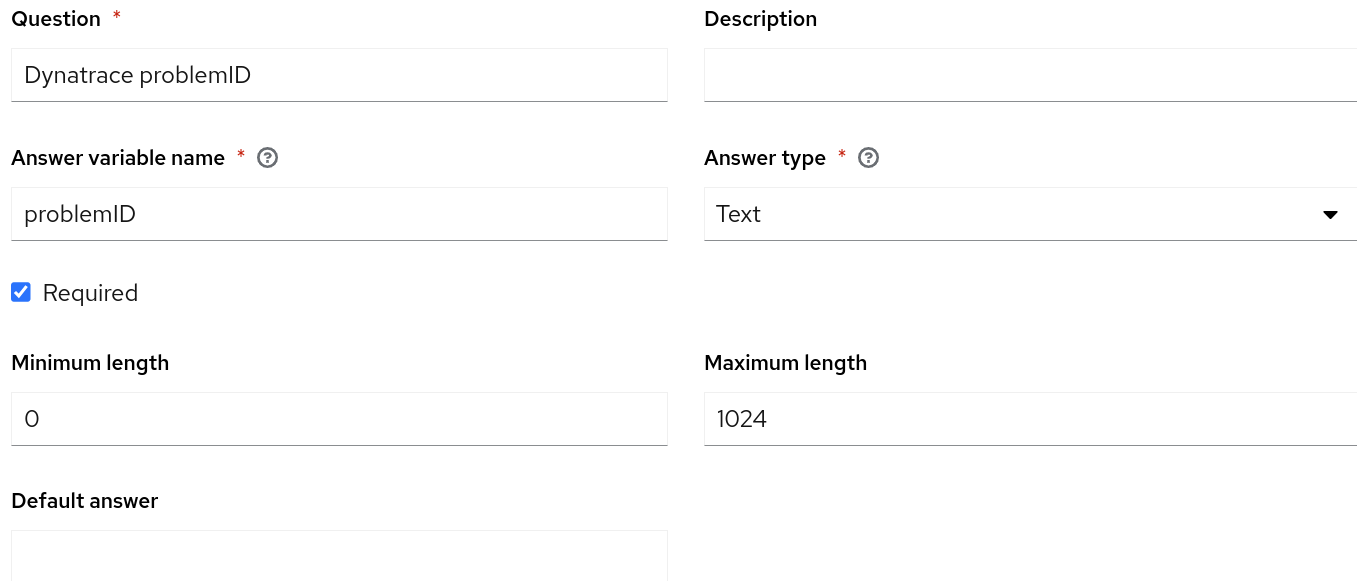
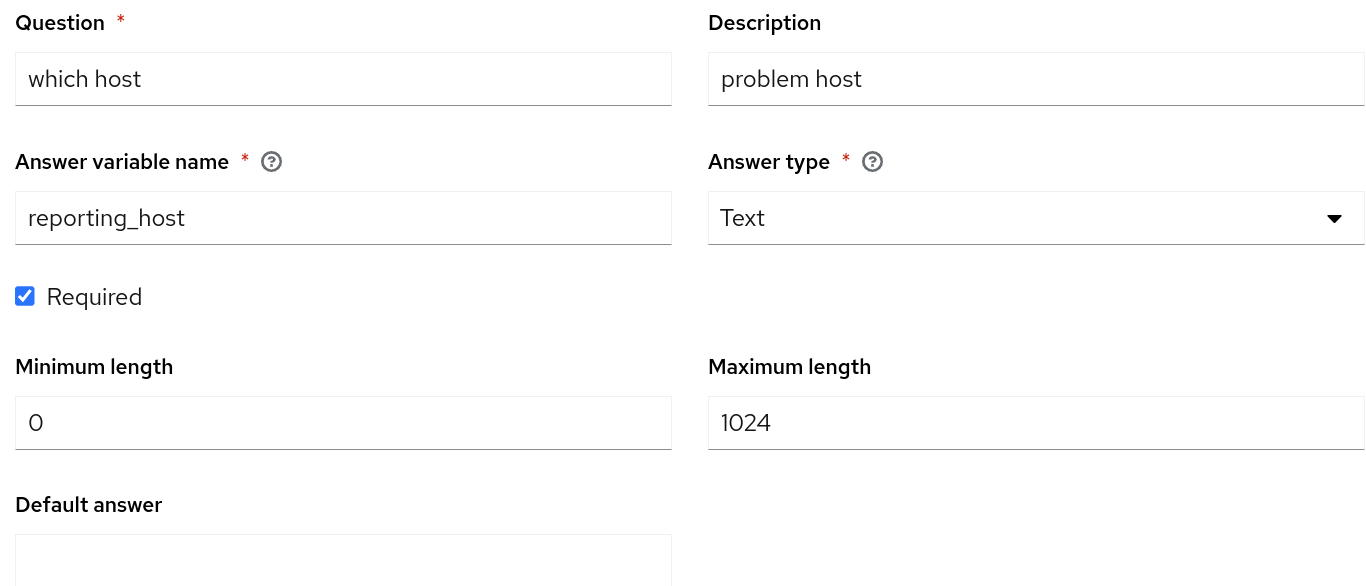
为使我们的用例发挥作用,需要将自动化控制器与 ServiceNow 集成,并拥有一个自动化执行环境,以便将自动化控制器中配置的 ITSM ServiceNow 内容集用于您的作业模板。此外,请确保已经在自动化控制器中创建了一个项目来存放修复 playbook,并且托管 NGINX Web 服务器的主机名也必须包含在自动化控制器的清单中。最后,请确保已成功将事件驱动的 Ansible 控制器与自动化控制器集成。
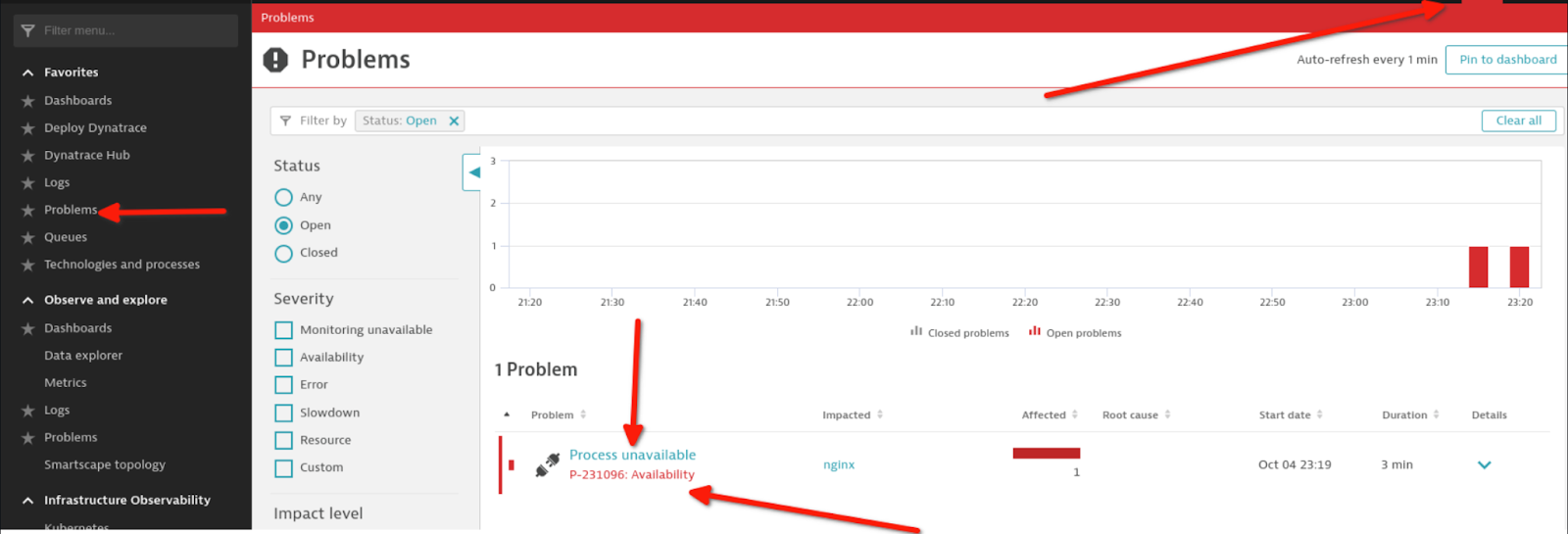
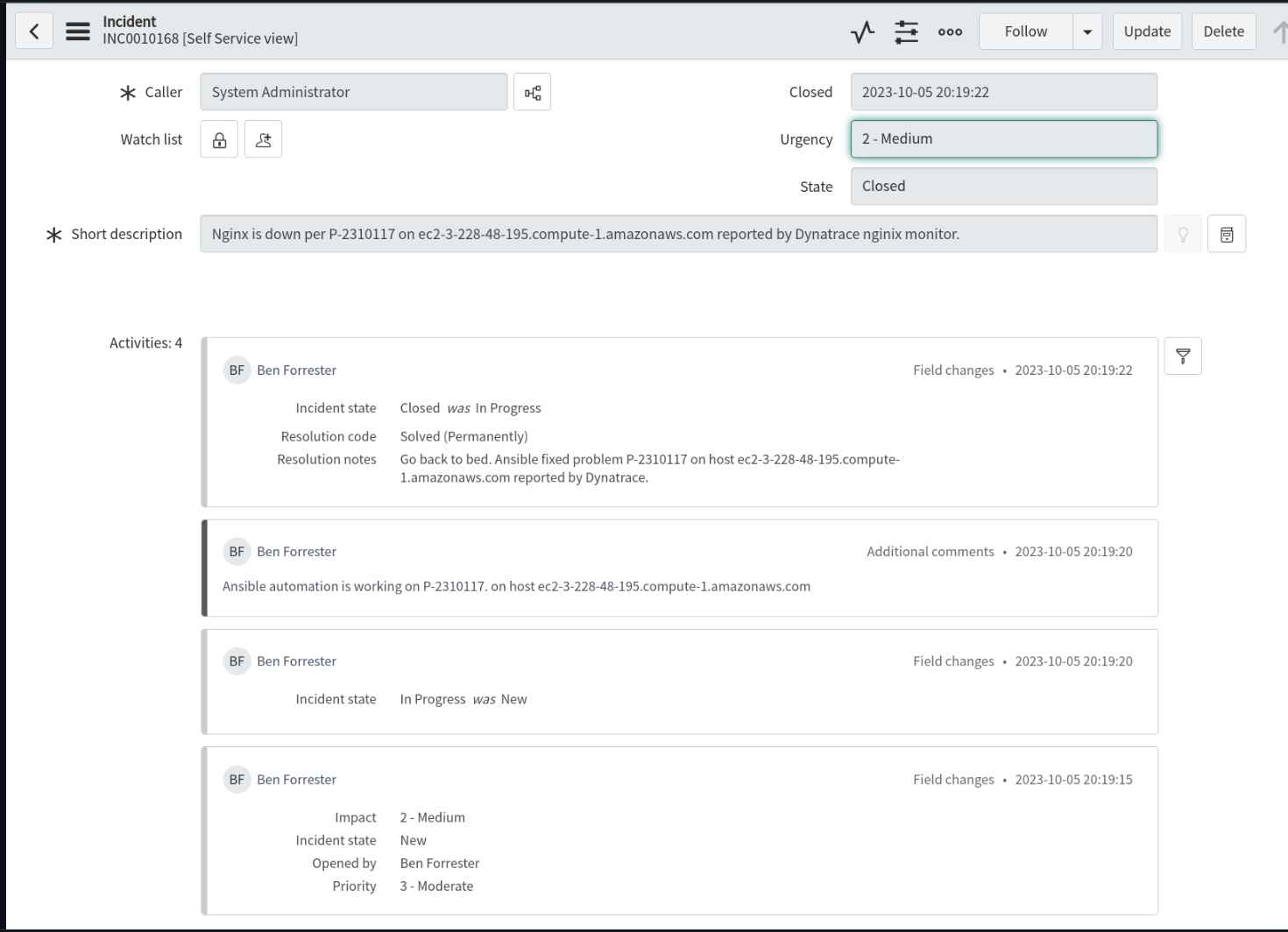
现在,一切都已设置妥当。您应该终止主机上的 NGINX 进程来进行测试,并观察以下几项:
Dynatrace 中生成的警报:
事件驱动的 Ansible 中的规则审计事件:
在自动化控制器中运行修复作业模板的作业事件

打开和更新一个事件工单,如果 Dynatrace 报告的问题主机恢复了 NGINX 进程,则关闭这个工单。
在本示例用例中,我们介绍了 Dynatrace 插件和决策环境,探索我们来源中的示例有效负载事件数据,以此演示如何动态填充变量。我们在 Dynatrace 中为 NGINX 进程实施了主机级进程监控器。另外,我们也可在 Dynatrace 中使用综合监控器来进行应用级监控。
通过强调适应性的重要性,我们的修复 playbook 保持动态,并且专门限定为仅在 Dynatrace 报告存在问题的主机上运行。虽然此示例涵盖众多主题,但我们必须认识到,对复杂任务进行自动化并不一定从一开始就要采用一种包罗万象的方法。相反,随着您学会自动执行修复,可以考虑将修复任务逐步集成到您的 playbook 中。最初,您可能会选择在实施任何修复操作之前打开事件工单,而后逐渐过渡到自动化处理常见问题。在自动化旅程中运用标准的敏捷原则,可以实现灵活的迭代式方法。值得注意的是,凌晨三点手动解决常见问题的时代正在转变,让您可以借助高效的企业级自动化实践重拾睡眠。
开心自动化!
其他资源和后续步骤
想要进一步了解事件驱动的 Ansible?
关于作者







