简介
适用于红帽 OpenShift 上虚拟机(VM)的灾难恢复策略,对于在计划外停机期间保持业务连续性至关重要。随着企业组织将关键工作负载迁移到 Kubernetes 平台,能够快速可靠地恢复这些工作负载已成为一项关键的运维要求。
虽然临时无状态虚拟机在云原生环境中已变得很常见,但大多数企业虚拟机工作负载仍然是有状态的。这些虚拟机需要可以在重启或迁移期间重新附加的持久块存储。因此,有状态虚拟机灾难恢复所面临的挑战,与早期 Kubernetes 灾难恢复模式(Spazzoli,2024 年)所解决的挑战有很大不同,早期灾难恢复模式通常侧重于基于容器的无状态应用。
这篇博客文章探讨了有状态虚拟机的不同要求。文章首先探讨了集群和存储架构选择如何影响故障转移可行性、复制行为及 RPO/RTO 目标;接着研究了编排层,展示 Kubernetes 原生工具(如红帽高级集群管理、Helm、Kustomize 和 GitOps 管道)如何管理工作负载放置和恢复。最后,这篇博客文章总结了复制块存储和 Kubernetes 清单的高级存储平台如何简化恢复过程,并在基础架构与应用级自动化之间架起桥梁。
明确术语定义
在深入探讨之前,我们先来定义一些重要的术语:
灾难:
在本次讨论中,“灾难”一词是指“站点丢失”。关于灾难恢复,核心始终是最大限度地减少业务服务的中断。因此,当您失去某个站点时,您需要实施灾难恢复计划,以尽可能快速高效地在备用站点恢复服务。
注意:灾难恢复计划不仅仅是在站点丢失时才执行。当某个主要组件发生故障,并且在故障组件恢复期间,需要将各个业务服务转移到备用站点时,通常会为各项业务服务制定灾难恢复计划。
组件故障:
组件故障是指影响企业组织中部分业务应用的一个或多个子系统的故障。这种故障模式将要求您将故障处理工作转移到主站点的备用系统上,或者要求您制定单独的灾难恢复计划,将业务应用的处理工作转移到辅助站点。
恢复点目标(RPO):
RPO 的定义是,从灾难或故障事件中恢复后,在数据丢失量超过企业组织可接受的范围之前,可以丢失的最大数据量(以时间为单位来衡量)。
恢复时间目标(RTO):
RTO 的定义是,企业组织可以容忍服务不可用的最长时间。虽然不同的架构选择会对 RTO 产生影响,但本博客文章未详细讨论这些考虑因素。
都市级灾难恢复与区域级灾难恢复:
灾难恢复分为两种类型:都市级灾难恢复和区域级灾难恢复。
- 都市级灾难恢复适用于数据中心距离足够近且网络性能允许同步数据复制的情况。同步复制的好处是可以实现零 RPO
- 区域级灾难恢复适用于因数据中心相距过远而无法支持同步复制,从而被迫使用异步复制的情况。异步复制几乎必然会导致部分数据丢失;但就本博客文章讨论范围而言,数据丢失量无关紧要
注意:如果您的存储基础架构不支持同步复制,则需采用区域级灾难恢复架构来满足您的都市级灾难恢复需求。
重启风暴:
重启风暴是指,您尝试同时重启的虚拟机数量过多,以至于虚拟机监控程序和支持基础架构无法应对,从而导致所有虚拟机都无法重启,或者虚拟机重启耗时远超可接受范围(通常达到数量级差异)。这也可称为非恶意拒绝服务攻击。
实现业务连续性的架构方法
有多种方法可以实现业务连续性和灾难恢复。如需对该主题进行一般性讨论,请先查看云原生计算基金会(CNCF)发布的 Cloud Native Disaster Recovery for Stateful Workloads(《针对有状态工作负载的云原生灾难恢复》)(Spazzoli,2024 年)白皮书。概括而言,有四种典型的灾难恢复方法,如下图所示(白皮书中对每种方法进行了详细说明):
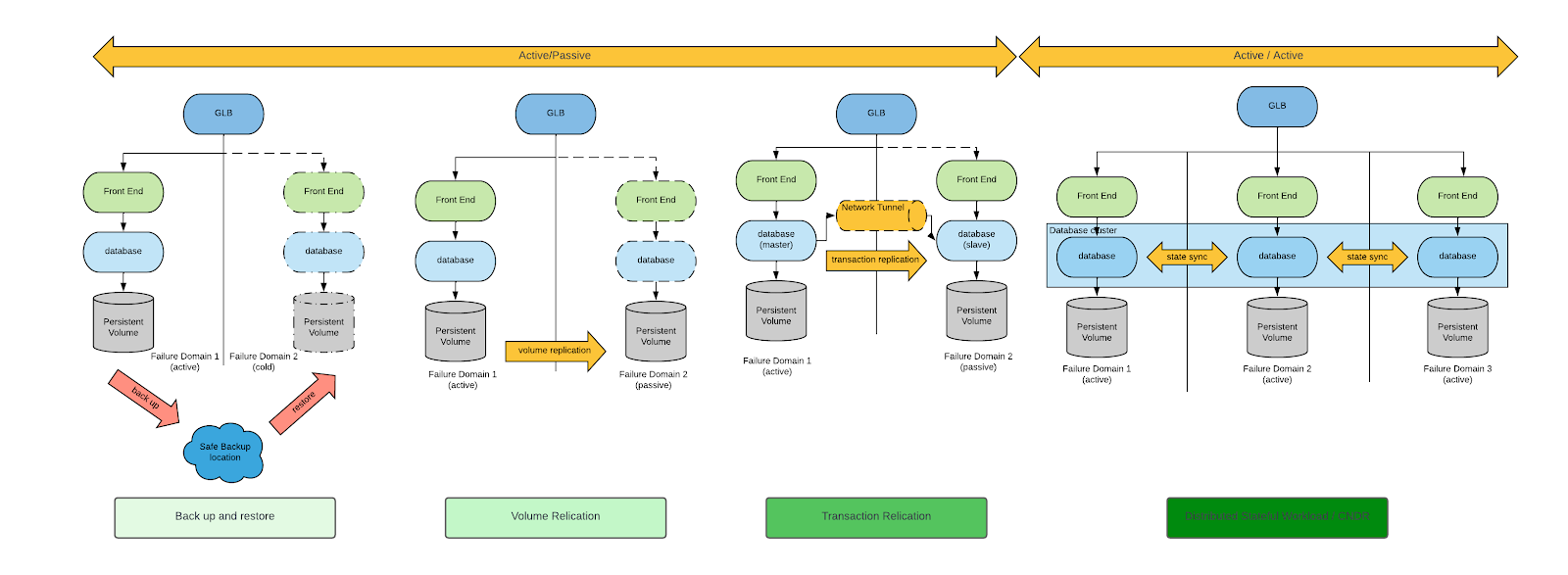
在考虑虚拟机的灾难恢复要求时,备份和恢复以及卷复制是唯一适用的灾难恢复模式。
虽然备份和恢复以及卷复制都是可行的方法,但基于卷复制的灾难恢复方法可以同时实现 RPO 和 RTO 最小化。因此,我们将仅重点关注基于卷复制的灾难恢复方法。
在缩小了分析范围后,我们将讨论两种灾难恢复架构方法,这两种方法在架构层面上通过卷复制类型进行区分:
- 单向复制
- 对称复制或双向复制
单向复制
在单向复制模式下,卷可以从一个数据中心复制到另一个数据中心,但反之则行不通。复制方向通过存储阵列控制,并且卷复制可以是同步复制,也可以是异步复制。具体选择取决于存储阵列的功能以及两个数据中心之间的延迟。异步复制适用于彼此之间延迟较高、很可能位于全球同一地理区域但不在同一都市圈的数据中心。
从架构层面看,单向复制的实现方式如下图所示:
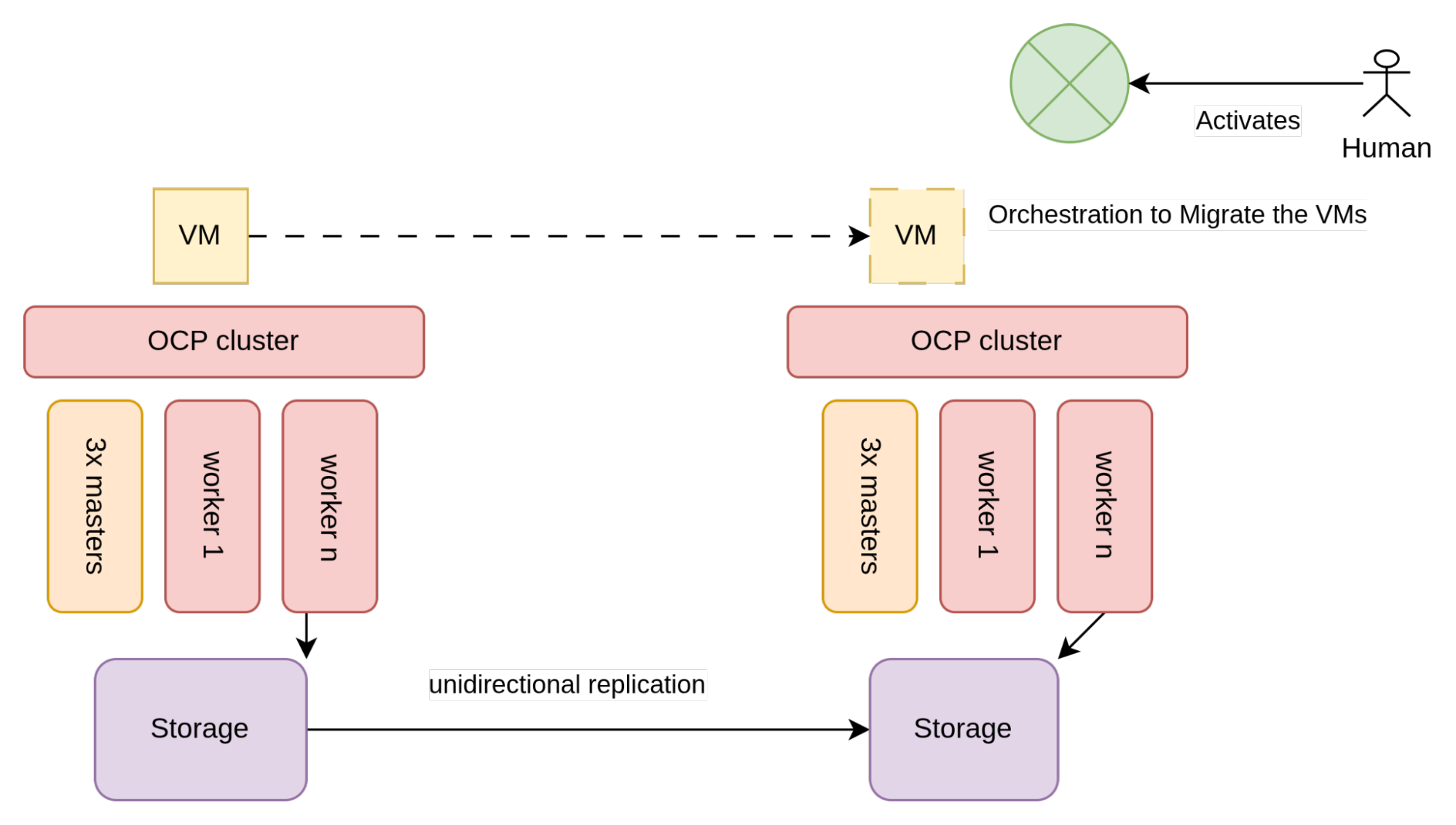
如图 2 所示,虚拟机使用的存储(通常是 SAN 阵列)配置为允许单向复制。
每个数据中心存在两个不同的 OpenShift 集群,并且每个集群都连接到本地存储阵列。集群之间彼此无感知,因此实施此架构的唯一约束条件由存储供应商规定,尤其是实现单向复制所需满足的要求。
单向卷复制注意事项
Kubernetes CSI 规范未对卷复制进行标准化。因此,存储供应商构建了专有的自定义资源定义(CRD)来实现这一功能。从总体上看,我们看到供应商在此功能方面的成熟度分为三个级别:
- 卷复制功能在 CSI 级别不可用,或者即使支持该功能,也无法在不直接调用存储阵列 API 的情况下实现完善的灾难恢复编排
- 卷复制功能在 CSI 级别可用
- 卷复制功能可用,并且供应商还负责管理命名空间元数据(即命名空间中的虚拟机和其他清单)的恢复工作
鉴于这种分散性,为区域级灾难恢复设置编写与供应商无关的灾难恢复流程并非易事。创建适当的 DR 编排方案所需写入的数据量取决于存储供应商。
让我们来看看此架构在不同故障模式下的行为:OpenShift 节点故障、存储阵列故障(组件故障)和整个数据中心故障(这是实际的灾难恢复场景)。
OpenShift 节点故障
如果节点(组件)发生故障,OpenShift 虚拟化调度程序负责在集群中下一个最合适的节点上自动重启虚拟机。在这种情况下,无需采取进一步的操作。
存储阵列故障
如果存储阵列发生故障,则依赖于该存储阵列的所有虚拟机也将发生故障。在这种情况下,需要执行灾难恢复流程。(有关所涉及的步骤,请参阅“灾难恢复流程”部分。)
数据中心故障
在数据中心出现故障期间,必须执行灾难恢复流程,以重启数据中心内未受故障影响的所有虚拟机。自动化在这里发挥着关键作用。但是,在重大事件管理框架内,该流程通常由人工启动。下一节概述了所涉及的步骤。
灾难恢复流程
灾难恢复流程可能会变得非常复杂,但简单来说,灾难恢复流程应考虑以下几点:
- 属于同一应用的虚拟机应以一致的方式复制卷。这通常意味着这些虚拟机的卷属于同一个一致性组
- 必须能够控制一致性组中的卷是否应该复制以及复制的方向。在正常情况下,卷将从主动站点复制到被动站点。在故障转移期间,不会复制卷。在故障恢复的准备阶段,卷会从被动站点复制到主动站点。在故障恢复期间,不会复制卷。
- 应该能够在另一个数据中心重启虚拟机,并且它们必须能够附加到复制的存储卷
- 可能需要限制虚拟机重启,以避免重启风暴。此外,通常需要确定虚拟机重启序列的优先级,以便首先启动最关键的应用,或者确保依赖组件(如数据库)先于依赖它们的服务启动
成本考量
根据 OpenShift 集群的配置方式,它可能被视为温或热灾难恢复站点。热站点必须完全订阅,而温站点则不需要(可能会节省一些成本)。
通常情况下,如果灾难恢复站点上没有运行中的工作负载,则可将其视为温站点。尤其是,用户可以配置持久卷(PV)、持久卷声明(PVC)甚至非运行虚拟机,以便在发生灾难时随时启动,并仍然保留温站点名称。
对称式主动/被动模式
将所有工作负载都放置到主动站点,这并非常见的做法。企业组织通常会将工作负载按 50:50 的比例分配至主数据中心和次要数据中心。这种方法比较实用,可确保任何灾难都不会一次性导致所有服务瘫痪。此外,总体恢复工作量也会相应减少。
在每个数据中心内分发活动虚拟机时,每一端都配置为能够故障转移到另一端。这种设置有时被称为“对称式主动/被动模式”。
对称式主动/被动模式将与 OpenShift 虚拟化和我们上面研究过的架构结合使用。请注意,在对称式主动/被动模式下,两个数据中心都被视为主动,因此必须订阅所有 OpenShift 节点。
对称复制模式
在对称复制模式下,卷会以同步方式进行双向复制。因此,两个数据中心均可拥有活动卷,并且能够针对这些卷执行写入操作。要实现这一点,企业组织必须拥有两个网络延迟极低(例如,约低于五毫秒)的数据中心。当两个数据中心位于同一都市区时,通常能够满足这一条件,因此该架构也被称为都市级灾难恢复。在这种情况下,可采用以下架构:

在此架构中,虚拟机使用的存储(通常是 SAN 阵列)配置为在两个数据中心之间执行对称复制。
这将创建一个跨两个数据中心延伸的逻辑存储阵列。要启用对称复制模式,需要有一个“见证站点”来充当独立仲裁节点,以防止在网络或站点故障时出现"脑裂"场景。
见证站点不必像两个主数据中心之间那样靠近(在延迟方面),因为它用于建立仲裁机制和解决脑裂问题。见证站点必须是独立的可用性区域,不承载任何应用工作负载,不需要具有较大容量,但在数据中心运维方面应具有与其他数据中心相同的服务质量(例如,物理/逻辑安全防护、电源管理、散热)。
随着存储跨数据中心延伸,OpenShift 也随之不断延伸。要在高可用性架构中实现这一点,OpenShift 控制平面需要三个可用性区域(站点)。这是因为 Kubernetes 的内部 etcd 数据库至少需要三个故障域,才能维持可靠的仲裁。这通常是通过利用其中一个控制平面节点的存储见证站点来实现的。
大多数存储区域网络(SAN)供应商的存储阵列都支持对称复制。但是,并非所有供应商都在 CSI 级别提供此项功能。假设存储供应商支持 CSI 级别的对称复制,并满足必要的前提条件和配置,那么在创建 PVC 时,就会置备多路径逻辑单元号(LUN)。此 LUN 包含通往两个数据中心的路径,因此必须对所有 OpenShift 节点进行配置,使其能够连接到两个存储阵列。多路径设备通常采用以下方式创建:非对称逻辑单元访问(ALUA)配置(Pearson IT Certification,2024 年)(即主动/被动,其中主动路径是通往最近阵列的路径);或者采用具有不同权重的主动/主动路径,其中最近阵列具有较高权重。
一些供应商甚至允许在光纤通道连接不“统一”时使用这种架构,这意味着一个站点上的节点只能连接到本地存储阵列。在这种情况下,当然不会创建 ALUA 配置。
这种集群拓扑有助于防止组件发生故障和灾难。我们来看下这种架构在不同故障模式下的行为。
OpenShift 节点故障
如果节点(组件)发生故障,OpenShift 虚拟化调度程序负责在集群中下一个最合适的节点上自动重启虚拟机。在这种情况下,无需采取进一步的操作。
存储阵列故障
多路径 LUN 有助于在两个存储阵列中的一个发生故障或脱机维护时提供服务连续性。在统一连接场景下,多路径 LUN 的被动路径或权重较低的路径,用于将虚拟机连接至其他阵列。此故障对虚拟机完全透明,可能会导致磁盘 I/O 延迟略有增加。在非统一连接场景下,虚拟机必须迁移至具备连接能力的节点。
数据中心故障
当整个数据中心变得不可用时,延伸的 OpenShift 会将其视为多个节点同时出现故障。OpenShift 会开始将虚拟机调度到另一个数据中心内的节点,如 OpenShift 节点故障部分所述。
假设有足够的备用容量供工作负载迁移,所有机器最终都将在另一个数据中心重启。已重新启动的虚拟机的 RPO 恰好为零,RTO 则为以下时间之和:
- OpenShift 意识到节点处于未就绪状态所需的时间
- 隔离节点所需的时间
- 重启虚拟机所需的时间
- 完成虚拟机启动流程所需的时间
这种灾难恢复机制本质上是完全自主的,不需要进行人工干预。但这可能并不总是符合实际需求。为避免重启风暴,通常需要控制重启哪些虚拟机以及何时启动此过程。
都市级灾难恢复注意事项
以下是关于此方法的一些注意事项:
- 由于虚拟机通常会连接到 VLAN,为了让虚拟机能够在数据中心之间自由迁移,VLAN 也必须在都市级数据中心之间延伸。在某些情况下,这可能并不符合实际需求。
- 通常,见证站点管理网络(OpenShift 节点网络)与都市级数据中心的管理网络不在同一 L2 子网中
- 有些观点认为这不是完整的灾难恢复解决方案,因为 OpenShift 控制平面和存储阵列控制平面构成了两个单点故障(SPOF)。这种 SPOF 是从逻辑意义上而言的,因为在物理层面当然存在冗余。不过,从理论上来说,OpenShift 或存储阵列的单一错误命令,确实可能会导致整个环境瘫痪。因此,对于最关键的工作负载,有时会将此架构以菊花链的形式连接到更传统的区域性灾难恢复架构
- 在灾难恢复场景下,若不加以干预,OpenShift 会自动将数据中心内受灾难影响的所有虚拟机同时重新调度到健康运行的数据中心。这可能会引发所谓的重启风暴。有许多 Kubernetes 功能可以通过控制哪些应用在何时进行故障转移来缓解这种风险。重启风暴的概念将在后续章节中进行讨论
成本考量
在对称复制模式下,两个站点均必须完全订阅,因为它们属于单个活动的 OpenShift 集群。而在单向复制模式下,必须为每个站点预留 100% 的超配容量,以确保能够完全承载另一站点的故障转移负载。
结论
选择单向复制架构还是对称复制架构,这为 OpenShift 虚拟化的整个灾难恢复策略奠定了基础。每种模型都需要在运维复杂性、基础架构成本、RPO/RTO 保证和自动化潜力之间进行权衡取舍。无论您选择双集群还是延伸集群设计,基础架构都必须符合业务连续性预期和基础架构限制。基于这些基础工作,第二部分将重点从基础架构转移到编排,超越存储层面,深入探讨如何在灾难场景下放置、重启和控制虚拟机。
关于作者

Bryon is a skilled infrastructure and software engineering specialist with deep expertise in AI/ML, Kubernetes, OpenShift, cloud-native architecture, and enterprise networking. With a strong background in storage technologies, infrastructure, and virtualisation, Bryon works across domains including system administration, AI model deployment, and platform engineering. He is proficient in C#, Golang and Python, experienced in container orchestration, and actively contributes to Red Hat-based solutions. Passionate about education and enablement, Bryon frequently develops technical workshops and training programs, particularly in AI/ML and DevOps. He is also a practising musician, blending his technical acumen with creative expression.

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).






