为什么要关注 AI 推理
简单来说,没有推理就没有 AI。
推理是生成式 AI 的核心。但当大型模型需要执行更宏大的策略时,情况就会变得复杂。
正因如此,我们将深入剖析 AI 推理带来的挑战和机遇,从基于 vLLM 的模型优化,到 llm-d 等最新的开源分布式框架。
为何推理至关重要?
推理是漫长而复杂的机器学习流程中的最后一步,在此阶段,模型会交付所需的输出。
最重要的是,它是 AI 取得成功所必需的功能。
因此,支持推理功能的硬件和软件,关系到 AI 战略的成败。

什么是阻碍扩展的元凶?
随着模型规模不断扩大,推理面临的压力也越来越大。模型越复杂,推理速度往往越慢。
为了成功进行推理,AI 模型需要在短时间内完成大量数学运算。因此,模型规模、高用户量和延迟等因素都可能会限制性能表现。
当模型需要更多数据和内存时,硬件和加速器便难以满足需求。
66%
预计 2026 年,推理将消耗 66% 的 AI 计算资源,高于 2023 年的 33% 和 2025 年的 50%。1
那么,该如何优化推理呢?
通过优化推理,AI 模型能够更快、更智能地运行。
优化方法包括更高效地利用 GPU、投机性解码、稀疏性处理、通过量化技术压缩模型,以及分布式推理。
LLM Compressor 等工具可利用最新模型压缩技术,使 LLM 更小巧、更节能、更快速。这可降低硬件要求并提升效率,且不影响模型准确性。
此类优化有助于 AI 推理保持成本效益,能够随团队发展而同步扩展。
99% 以上
使用 LLM Compressor 进行优化时,准确率得以保持在 99% 以上。2

两倍
采用压缩模型后,计算吞吐量提升两倍,且不影响准确性。3
50%
使用 LLM Compressor 进行优化时,可在不牺牲性能的前提下节约 50% 的成本。4

vLLM 是如何优化推理的?
模型优化只是第一步。您还需要一个高性能的推理引擎。这正是 vLLM 的用武之地。
传统的 LLM 内存管理系统在组织内存方面并不高效,因此会影响 LLM 的运行速度。vLLM 采用 PagedAttention 内存管理技术,该技术可识别重复的键值,从而减少 LLM 的额外工作量。
这使得 vLLM 能够更好地利用 GPU 内存,加速生成式 AI 的推理过程。它可最大限度地提高吞吐量(每秒处理的词元数),从而可以同时为众多用户提供服务。
更高效地利用加速器,这意味着模型可以在更短时间内完成更多数学运算,从而使团队能够更快地为更多用户和 AI 代理提供服务。
50%
采用稀疏结构后,参数量减少 50%。5

2.1 倍
采用推测解码技术后,推理延迟降低了 2.1 倍。6
24 倍
与竞争对手相比,vLLM 的吞吐量性能提高了 24 倍。7
为什么 vLLM 如此受欢迎?
vLLM 通过开放且可移植的部署方案,有效解决了高效利用 GPU 的核心难题,显著降低了每词元成本,并在大规模场景下实现稳定延迟。
这也是 vLLM 社区一直保持活跃并蓬勃发展的重要原因。Hugging Face、加州大学伯克利分校、英伟达和红帽等众多组织的积极贡献,持续推动着 vLLM 的发展。社区成员在这个开源项目中不断对软件进行挑战与改进,使其持续优化。
vLLM 针对所有主流模型和加速器提供 Day 0 支持,并且它易于使用,对产业界和学术界都极具吸引力。
超过 10,000 次
2025 年,vLLM 在 GitHub 上的代码提交(commit)次数超过 10,000 次,增幅超过 200%。
如今的 vLLM 社区
超过 50 万
超过 50 万个已部署 GPU 全天候不间断运行8
超过 200
超过 200 种不同类型的加速器9
超过 500
支持的模型架构数量超过 500 种9
超过 2,200
分布式推理如何发挥作用?
借助分布式推理,AI 模型能够将推理任务分配给一组互联设备协同处理。
当模型能够同时满足不同请求时,便能显著减少所需硬件并提升推理效率。
分布式推理采用张量并行、智能推理调度和解耦等技术。当与 vLLM 结合使用时,推理的作用便相当于一台高效的多任务处理机器。
这有助于推理过程保持可观测性、可扩展性和一致性。
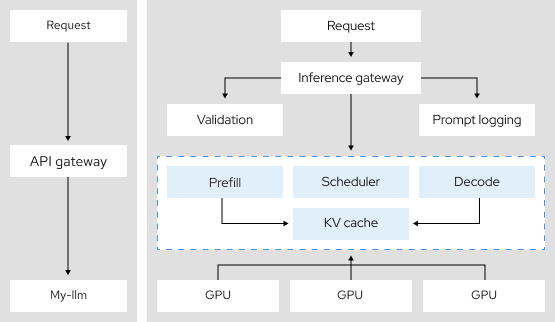
3.9 倍
采用张量并行技术(一种分布式推论架构)后,词元吞吐量提升了 3.9 倍。10
是否有相应的开源社区?
有,名字就叫“llm-d”。
llm-d 是一个开源框架,为开发人员提供了大规模构建分布式推理的参考架构。
其模块化架构能够满足复杂 LLM 的高资源需求,并以集成化的规范化路径取代过去手动的碎片化流程,从而加速从试点阶段到生产阶段的进程。
llm-d 将推理能力引入 Kubernetes,提供了一套标准化的工具包,帮助您将分布式推理应用到独特的企业用例。
两倍
llm-d 实现的每秒查询数(QPS)达到基准值的两倍。11
更多 AI 资源
红帽 AI 推理服务器
让您的 LLM 更快地从代码阶段迈向生产阶段。
借助基于 vLLM 构建的企业级推理引擎,可在不牺牲性能的前提下实现更快的推理。
使用您首选且经过优化的生成式 AI 模型,在任意 AI 加速器和云环境中实现跨混合云扩展。

引用来源
[1] “Why AI’s Next Phase Will Likely Demand More Computing Power—Not Less”(为何 AI 下一阶段或将需要更多而非更少的计算能力),《华尔街日报》,2026 年 1 月 22 日。
[2] Eldar Kurtić 等。“We ran over half a million evaluations on quantized LLMs—here's what we found”(我们对量化 LLM 进行了超过五十万次评估——以下是我们的发现),红帽开发人员博客,2024 年 10 月 17 日。
[3] Carlos Condado。 “提高 AI 推理性能的战略方法”,红帽博客,2025 年 9 月 15 日。
[4] Saša Zelenović。“释放 LLM 的全部潜力:利用 vLLM 优化性能”,红帽博客,2025 年 2 月 27 日。
[5] Eldar Kurtić 等。“2:4 Sparse Llama:Smaller models for efficient GPU inference”(2:4 稀疏化 Llama:实现高效 GPU 推理的更小模型),红帽开发人员博客,2025 年 2 月 28 日。
[6] Alexandre Marques 等。“Fly Eagle(3) fly:Faster inference with vLLM & speculative decoding”(Eagle-3 助力性能跃升:借助 vLLM 与推测解码技术加速推理),红帽开发人员博客,2025 年 7 月 1 日。
[7] Woosuk Kwon 等。“vLLM:Easy, Fast, and Cheap LLM Serving with PagedAttention”(vLLM:基于 PagedAttention 实现简单、快速且低成本的 LLM 服务),vLLM 博客,2023 年 6 月 20 日。
[8] Michael Goin。“[vLLM Office Hours #38] vLLM 2025 Retrospective & 2026 Roadmap - December 18, 2025”([vLLM Office Hours 第 38 期] vLLM 2025 年回顾与 2026 年路线图——2025 年 12 月 18 日),YouTube,2025 年 12 月 8 日。
[9] Woosuk Kwon。“Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale”(如今,vLLM 支持超过 500 种模型架构,可在超过 200 种加速器上运行,并为全球范围内的大规模推理提供动力),X,2026 年 1 月 26 日。
[10] Michael Goin。“Distributed inference with vLLM”(利用 vLLM 实现分布式推理),红帽开发人员,2025 年 2 月 6 日。
[11] Robert Shaw。“llm-d:Kubernetes-native distributed inferencing”(llm-d:Kubernetes 原生分布式推理),红帽开发人员,2025 年 5 月 20 日。