

目前存在一个显著趋势:越来越多的企业组织开始将自己的大语言模型(LLM)基础架构部署在内部环境中。无论是出于对延迟、合规性还是数据隐私的考量,在自有硬件上采用开源模型进行自托管,都将让您轻松驾驶 AI 之旅。然而,将 LLM 从实验阶段扩展为生产级服务会带来显著的成本问题和复杂性挑战。
为应对上述挑战,一款名为 llm-d 的新型开源框架应运而生,它由红帽、IBM 和 Google 等一众行业领军贡献者共同提供支持。该框架聚焦于问题的核心:AI 推理——即模型为提示词、代理、检索增强生成(RAG)等应用场景生成结果的处理过程。
通过智能调度决策(解耦)和 AI 专用路由模式,llm-d 能够为 LLM 实现动态且智能的工作负载分配。这一点为什么至关重要?接下来,我们将深入了解 llm-d 的工作原理,以及它如何在提高性能的同时帮助降低 AI 成本。
扩展 LLM 推理所面临的挑战
在 Kubernetes 等平台上扩展传统的 Web 服务所遵循的是既定模式。标准 HTTP 请求通常具备速度快、格式统一且无状态的特点。然而,对 LLM 推理进行扩展却是一个本质上完全不同的难题。
造成这一差异的主要原因之一是请求特征的高度不一致性。例如,RAG 模式可能会使用包含来自向量数据库上下文的长输入提示词来生成简短的单句回答。与之相反,某项推理任务可能基于简短的提示词来生成包含多步骤的长文本响应。这种差异会导致负载不均衡,进而降低性能且增加尾延迟(ITL)。LLM 推理还高度依赖键值(KV)缓存(LLM 的短期记忆)来存储中间结果。而传统的负载均衡机制无法获取此类缓存的状态,导致请求路由的效率低下,且计算资源未能得到充分利用。

在 Kubernetes 平台上,一种现行做法是将 LLM 部署为单体式容器,这类容器如同大型黑匣子,既无法实现内部状态的可见性,也缺乏精细控制能力。除此之外,这种部署方式还忽略了提示词结构、令牌数量、响应延迟目标(即服务等级目标,简称 SLO)、缓存可用性等诸多因素,导致 LLM 推理难以实现高效的扩展。
简而言之,我们当前使用的推理系统效率低下,且消耗的计算资源超出了实际所需。
llm-d 使推理变得更高效且更具成本效益
尽管 vLLM 可跨各种硬件提供广泛的模型支持,但 llm-d 在此基础上更进了一步。llm-d 基于现有企业级 IT 基础架构而构建,具备分布式高级推理能力,可帮助企业节省资源并提升性能,包括首令牌生成时间缩短至原来的 1/3,以及在满足延迟服务等级目标(SLO)约束的前提下吞吐量翻倍。尽管 llm-d 提供了一系列强大的创新功能,但其核心还是集中于能够提升推理性能的以下两项技术创新上:
- 解耦:通过对推理过程进行解耦,我们能够在推理阶段更高效地利用硬件加速器。具体而言,该技术会将提示词处理(预填充阶段)与令牌生成(解码阶段)拆分为独立的工作负载(即 pod)。由于这两个阶段具有不同的计算需求,拆分后可对每个阶段进行独立的扩展和优化。
- 智能调度层:该调度层扩展 Kubernetes Gateway API,能够对传入请求实现更精细化的路由决策。它利用键值缓存利用率、pod 负载等实时数据,将请求定向至最优实例,从而最大限度地提高缓存命中率,并在集群内实现工作负载均衡。

除了跨请求缓存键值对来避免重复计算等功能外,llm-d 还将 LLM 推理拆分为模块化智能服务,以实现具备可扩展性的性能(同时依托 vLLM 本身提供的广泛支持)。下面我们将结合一些实际示例来深入了解每项技术,并了解 llm-d 如何运用这些技术。
解耦如何提高吞吐量并降低延迟
LLM 推理的预填充阶段与解码阶段之间存在本质差异,这给资源的统一分配带来了挑战。处理输入提示词的预填充阶段通常属于计算密集型任务,需要强大的处理能力来创建初始键值缓存条目。相反,逐一生成令牌的解码阶段则多为内存带宽密集型任务,因为该阶段主要涉及对键值缓存的读写操作,对计算能力的需求相对较低。
通过实现解耦,llm-d 可将这两种计算配置文件截然不同的任务分配给独立的 Kubernetes pod 处理。这意味着,您可以为预填充 pod 置备针对计算密集型任务优化的资源,同时为解码 pod 设置针对内存带宽效率优化的配置。
LLM 感知推理网关的工作原理
智能调度路由器是 llm-d 性能提升的核心,它负责编排推理请求的处理位置和方式。当推理请求到达 llm-d 网关(基于kgateway)时,它并不会被简单地转发至下一个可用的 pod。相反,作为 llm-d 调度程序核心组件的端点选择器(EPP)会评估多项实时因素,以确定请求的最优目标端点,具体逻辑如下:
- 键值缓存感知:调度程序会维护所有正在运行的 vLLM 副本的键值缓存状态的索引。如果新请求与特定 pod 上已缓存的会话存在共同前缀,调度程序会优先将该请求路由至相应 pod。这一机制能显著提升缓存命中率,避免重复执行预填充计算,从而直接减少延迟。
- 负载感知:除了简单的请求计数,调度程序还会评估每个 vLLM pod 上的实际负载情况,同时考量 GPU 内存利用率和处理队列,从而防止性能瓶颈。
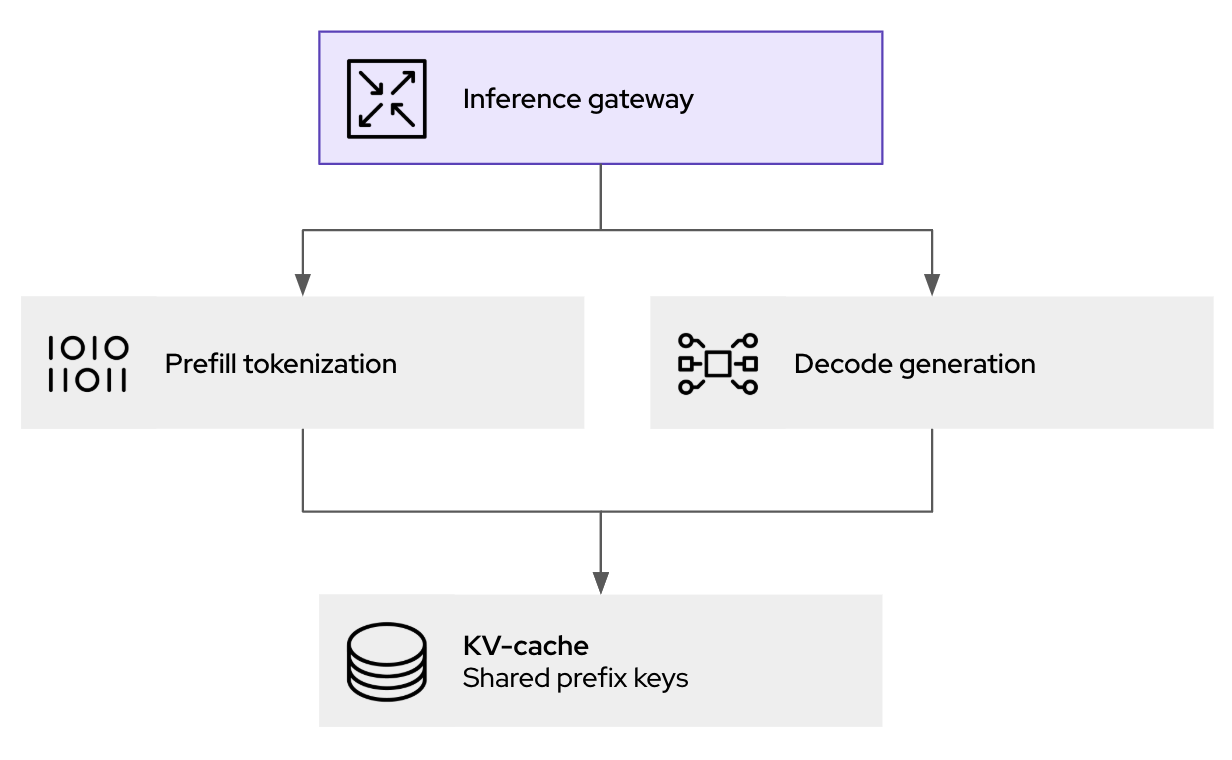
这种 Kubernetes 原生方法为生成式 AI 推理提供了策略、安全及观测性层面的支撑。这不仅有助于有效处理推理请求流量,还支持提示词日志记录与审计功能(满足治理和合规要求),同时可在请求转发至推理阶段前实施安全防护措施。
开始使用 llm-d
llm-d 项目背后蕴藏着令人振奋的发展活力。vLLM 非常适合单服务器部署场景,而 llm-d 则专为管理集群的运维人员打造,旨在实现高性能、高成本效益的 AI 推理。是否已准备好开启探索之旅?不妨访问 GitHub 上的 llm-d 存储库,并加入 Slack 社区参与交流!这是一个提问交流与参与贡献的理想平台。
AI 的未来正依托开放协作的原则逐步构建。通过 vLLM 等社区以及 llm-d 这类项目,红帽正致力于让全球开发人员都能更便捷地接触 AI、更经济地使用 AI、更高效地发挥 AI 能力。
关于作者
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Christopher Nuland is a Principal Technical Marketing Manager for AI at Red Hat and has been with the company for over six years. Before Red Hat, he focused on machine learning and big data analytics for companies in the finance and agriculture sectors. Once coming to Red Hat, he specialized in cloud native migrations, metrics-driven transformations, and the deployment and management of modern AI platforms as a Senior Architect for Red Hat’s consulting services, working almost exclusively with Fortune 50 companies until recently moving into his current role. Christopher has spoken worldwide on AI at conferences like IBM Think, KubeCon EU/US, and Red Hat’s Summit events.






