随着 AI 成为国家竞争力的引擎,主权 AI 的概念(即在不受外部影响的情况下运行 AI 系统的能力)变得越来越重要,但采用的道路上充满了挑战。最近针对 900 多名 IT 领导者和 AI 工程师开展的一项关于 AI 采用的调查暴露了显着的“价值差距”。调查显示,尽管对 AI 采用的热情很高 (72%),但只有 7% 的欧洲、中东和非洲 (EMEA) 组织正在取得成果。
调查强调,数据隐私和基础架构孤岛导致 AI 开发工作陷入瘫痪。因此,主权 AI 已迅速从理论上的“云挑战”转变为现实中的必需品。通过缓解红帽调查中确定的特定风险,主权 AI 允许受监管企业放心地从试点阶段过渡到生产阶段,而不会影响以下方面:
- 监管合规性:遵守《通用数据保护条例》(GDPR)、《欧盟 AI 法案》等严格法规,以及要求公民数据保留在特定边界内的数据驻留法。
- 运维弹性:在地缘政治不稳定或与全球互联网断开连接的情况下继续运维的能力。
- 战略自主权:企业组织可以避免供应商锁定,并保持对从敏感数据生成的模型和权重等知识产权的完全控制。
红帽 OpenShift AI 为这种主权奠定了基础,使企业组织能够构建一个“气隙隔离”的 AI 工厂,同时保持对安全性、数据、模型和结果的绝对控制。
在本文中,我们着眼于客户面临的主权 AI 挑战的具体示例,抽象出需要解决的主要主题,并针对这些问题提出解决方案。
用户故事:“AI 独立”的困境
主角:博士Aris(基于真实客户挑战的复合角色),欧洲某中等国家卫生部的首席数据官。
挑战:该部拥有大量的数据、数十年的匿名患者记录、基因组序列和当地的流行病学历史记录。博士Aris 希望建立一个“国民健康 LLM”,以协助医生诊断特定人群的罕见疾病。
至关重要的是,该部正面临着“影子 AI”问题。沮丧的研究人员为了完成工作,偷偷将匿名代码片段上传到公共 LLM,冒着数据泄露的风险。他们需要一个经认可、完全安全、与公共云一样易于使用的内部平台。
冲突:
- 云陷阱:提供模型即服务 (MaaS) 的领先 AI 提供商要求将敏感数据上传到位于美国的公共云。这可能违反《通用数据保护条例》(GDPR)、数据驻留法和国家安全协议。
- DIY 的噩梦:博士Aris 尝试从头开始构建平台。仲裁对 500 个 GPU 集群的访问权限的运维混乱很快使他的团队陷入瘫痪,导致持续的资源争用,关键实验无限期等待,而预留硬件闲置。
解决方案:该部在 OpenShift AI 基础上构建了一个主权 AI 平台,同时也使用了 Kubeflow 和 Feast。
- 转变:博士Aris 的团队在自己的气隙、受保护的基础架构上构建了一个“模型工厂”。OpenShift AI 包含 Kubeflow 组件,可将 GPU 集群硬件抽象化,使团队能够训练大规模模型,而无需跨越边界发送单个字节。Feast 有助于在训练和推理过程中集中管理特征,使输入模型的特征得到一致定义,从而实现治理和可追溯性。
- 结果:数据科学家只需提交训练请求,系统就会自动启动分布式集群,从 Feast 检索特征,训练模型,并将其分解,所有这一切都在气隙国家数据中心内完成。博士Aris 根据本国的情况,使用可扩展的非联网 AI 平台实现了“AI 自治”。
主权 AI 的三大支柱
要从“数字殖民地”(一个国家(或社区)过度依赖外国技术基础架构,以至于失去对自己数字经济、数据和未来发展的控制)转变为“数字主权”,一个国家必须控制 AI 技术堆栈的 3 个关键层。
技术主权(基础)
原则:主权要求透明的监管链和抵御供应链武器化的弹性。通过采用与硬件无关的平台层,各国可以通过多供应商策略优化其 AI 进程,因此无论全球供应链如何变化,其战略自主权都能得到保留。主权平台必须将软件与硬件分离,并将基础架构的严格所有权与适应市场可用性的灵活性相结合。通过遵守开源标准,企业组织的 AI 功能可以独立于任何单个供应商的路线图或硬件垄断进行检查、审计和维护,从而保留对服务连续性的绝对权威。
验证:红帽 AI 调查证实,92% 的 IT 领导者认为企业开源对其 AI 战略至关重要。它提供了控制 AI 供应链所需的一致性和透明度。
数据主权(资产)
原则:数据引力是绝对的。敏感数据必须驻留在实际位于主权边界内的存储介质上,并且仅受当地法律的约束。挑战在于,如何让数据科学家像在云中一样轻松地选择和检索数据,同时从物理上将数据移动限制到安全的内部网络。
运维主权(控制权)
原则:“控制平面”必须是本地的。关键工作流不能依赖托管在另一大洲的软件即服务 (SaaS) 控制台来管理计算资源或用户访问。主权平台需要一个独立的控制平面,以完全在本地边界内处理身份访问管理 (IAM) 和资源编排。
技术解决方案
我们的解决方案建立在分层架构之上,其中红帽 AI 充当统一的主权平台,编排 Kubeflow 的训练功能和 Feast 的数据管理。
该解决方案建立在开源标准之上,特别是红帽 OpenShift(提供 Kubernetes 基础)和 Kubeflow 项目。通过使用随附的组件(模型注册表、KServe、Pipeline and Training 以及用于功能服务的 Feast),企业组织可以完全掌控其技术堆栈。这种透明度使企业组织能够检查代码中的漏洞,并直接为项目的路线图做出贡献。我们这里的重点是 Kubeflow Trainer 和 Feast 如何支持这些主权要求。
AI 主权的开放蓝图:红帽 AI
要实现真正的主权,底层平台必须与其处理的数据一样值得信赖。红帽 AI 提供了一个强化的企业级基础,可满足受保护的独立 AI 工厂的特定需求。
红帽 AI 可提供完全的基础架构独立性。它支持在气隙裸机、私有云或受信任的主权云合作伙伴上进行部署。这使得企业组织可以选择自己的硬件供应商(例如 NVIDIA、Intel、AMD),并保留对服务连续性的绝对控制权。
- 值得信赖的软件供应链:主权始于源头。红帽 AI 提供一系列经过认证、漏洞扫描和数字签名的 AI 工具,确保在您的气隙边界内运行的软件不存在已知漏洞,而这正是国家安全的关键要求。
- 统一 MLOps 控制平面:该平台将分散的 AI 技术堆栈整合到一个界面中。它有助于管理操作系统(红帽企业 Linux)、硬件 (GPU) 和应用层 (Kubeflow/Feast) 之间复杂的依赖关系,因此数据科学家可以专注于建模,而不是基础架构管道。
- 可扩展的硬件抽象:无论是在裸机机架上运行,还是在虚拟化私有云上运行,红帽 AI 都能将物理资源抽象化。它使用操作程序来自动调优和公开专用硬件,例如国家级超级计算机中的 GPU,从而在不向用户暴露复杂性的情况下实现强大的多租户。
有了这样的安全基础,我们就可以信赖红帽 OpenShift AI。作为红帽 AI 产品组合中的分布式 AI 平台,OpenShift AI 允许企业组织构建、调优、部署和管理 AI 模型和应用。它充当中枢神经系统,协调 3 种关键的集成功能:高性能训练引擎、精确的数据管理层和优化的模型服务框架。
集成计算:Kubeflow 训练器
对于主权 AI 工厂,由于严格的控制和数据驻留要求,依赖公共云基础架构通常不是一种选择。要保持真正的主权,您必须拥有并运维硬件。然而,这种独立性伴随着有效管理它的责任,包括调度复杂的分布式作业、处理节点故障以及高效使用高价值的超级计算资产。
Kubeflow Trainer(红帽 OpenShift AI 的一个组件)解决了这一运维悖论。它为您的私有基础架构带来云原生易用性,充当简化 Kubernetes 分布式训练的高性能引擎。它以统一的 TrainingJob API 取代了分散的工作流,使数据科学家能够扩展 PyTorch 和 TensorFlow 等框架,而无需重写复杂的基础架构代码。
- 简化:通过抽象底层主权基础架构,它为大规模分布式训练任务提供统一的接口。
- 可靠性:它基于 Kubernetes JobSet API 构建,可确保在分布式训练集群中的某个节点发生故障时,整个组得到正确管理(全有或全无调度)。这有助于减少资源浪费,因为大规模训练作业要么完全运行,要么彻底重新启动。
- 集成:它与 Kueue(红帽 OpenShift AI 调度堆栈的一部分)原生集成,以管理作业配额和队列,并从底层 OpenShift 节点池动态分配 GPU 资源,从而最有效地利用国家计算资源。
主权数据:Feast 特征存储
虽然真正的数据主权需要全面的数据策略,但还需要一个专门的组件来弥合原始数据和模型使用之间的差距。作为计算引擎的补充,Feast 充当解决方案的“内存”。Feast 在 OpenShift 上运行,将模型与原始数据基础架构分离,以提高合规性和可再现性。
Feast 负责管理“时间点”的正确性,因此模型会根据特定历史时刻的可用数据进行训练,从而防止数据泄漏并实现全面的可审计性。
- 离线存储(如 MinIO):它安全地连接到气隙 S3 兼容对象存储,以处理用于训练的高吞吐量历史数据。
- 在线存储(如 Redis):它管理用于推理的低延迟功能,因此在主权边界内做出实时决策。
- 特征注册表:它为特征定义提供单一事实来源,因此平台上的每位数据科学家都会以相同的方式计算关键指标(如“患者年龄”),从而保持主权情报的完整性。
完成生命周期:主权模型服务
真正的主权不仅限于训练,还必须涵盖整个 MLOps 生命周期。模型经过 Kubeflow 训练后,必须在不离开安全边界的情况下进行部署,以处理实时数据。
OpenShift AI 通过集成的模型服务功能来完成这一循环。通过利用平台内支持分布式推理的 KServe、vLLM 和 llm-d 等工具,企业组织可以立即将其模型工件部署到与它们接受训练的同一气隙主权集群上。这意味着:
- 内部推理:借助 vLLM 和 llm-d,用户查询(例如医生的诊断请求)和实时数据流在本地处理,无需遍历公共 API。这些技术通过 PagedAttention 优化 GPU 内存使用,并允许将大量基础模型分片到多个较小的 GPU 上。这种优化的功能使公司在自己的现有基础架构上托管高性能生成式 AI(gen AI)在财务和技术上都可行,无需租用昂贵且非主权的云 API。
- 统一主权:从硬件加速到模型监控,整个流程(收集 (Feast) → 训练 (Kubeflow) → 服务 (OpenShift AI))都在主权基础架构上执行,完全由您掌控。
这种能力将“开发”阶段直接连接到“集成”和“监控”阶段,这意味着受监管实体可以完全在内部运行端到端的世界级 AI 工厂。
架构
下图说明了 OpenShift AI 如何充当主权平台层,封装在气隙环境中运行 Kubeflow 和 Feast 所需的编排、安全防护和硬件管理。
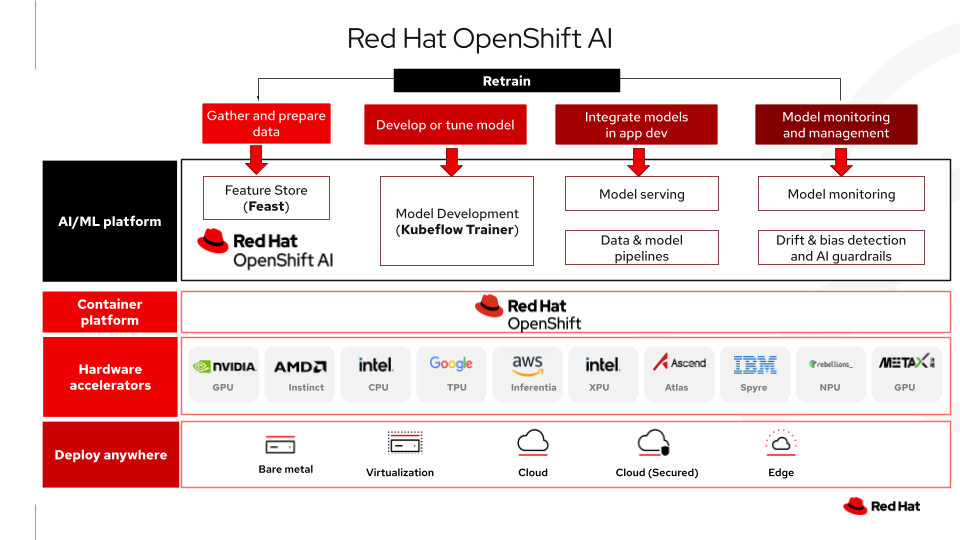
总结
实现主权 AI 需要的不仅仅是本地硬件,还需要一个尊重数据重要性和现代 AI 工作流复杂性的软件架构。
通过在 OpenShift AI 中使用 Kubeflow Trainer 和 Feast 等技术,企业组织可以构建一个主权 AI 工厂:
- 设计上经过强化:数据直接在受保护的边界内从存储流向计算,受红帽基于角色的企业级访问控制 (RBAC) 和可选的联邦信息处理标准 (FIPS) 合规性的监管。
- 可扩展:利用 Kubernetes 上分布式训练的强大功能,以及 OpenShift AI 和 Kubeflow Trainer 提供的自动化硬件管理。
- 可重现:使用特征存储来支持可审计的数据沿袭。
该解决方案使国家和企业能够在不损害其独立性的情况下利用 AI 的力量,将主权挑战转化为竞争优势。
准备好建立自己的主权 AI 工厂了吗?
- 获取技术支持:想要查看架构背后的代码?红帽开发人员博客上提供了详细的技术教程: 利用 Feast 和 Kubeflow Trainer 改进 RAG 检索。
- 探索平台:如需更深入的了解,请访问 红帽 OpenShift AI,了解我们的企业级平台如何帮助企业大规模构建、部署和管理拥有主权且受保护的 AI 应用。
关于作者

Umberto Manganiello is a Staff Engineer at Red Hat since 2025. Prior to this, he spent over 15 years as a Principal Architect and Engineer in the Financial and Telecommunications sectors. He specializes in designing high-availability systems that operate at massive scale, leveraging deep expertise in Kubernetes, Kafka, and Cloud modernization. Currently, he applies this architectural discipline to the challenges of MLOps, with a focus on GenAI, OpenShift AI, and Kubeflow, blending cloud-native resilience with AI model training workflows.






