
The data is there. The insight isn't.
Telecommunications networks generate unprecedented volumes of telemetry. Every authentication attempt, packet flow, device heartbeat, controller update, and service interaction produces telemetry. As networks expand into Wi-Fi offload, 5G standalone, and distributed edge deployments, that volume continues to grow. Yet turning that data into operational intelligence remains one of the industry's hardest challenges.
The challenge for operators today is not collection. It is a correlation. Modern networks produce multiple operational signals simultaneously:
- Network KPIs
- Device syslogs
- Authentication records
- Alarm streams
- Change requests
- Maintenance windows
- Other external signals such as weather or regional outages
Fig: Telecommunications networks generate multiple operational signals that must be correlated to identify root causes.
Individually, each stream is useful. Together, they can explain service degradations that no single source could reveal.
Beyond anomaly detection toward operational AI
Traditional monitoring tools detect anomalies.
Modern network operations require systems that can detect, correlate, explain, and recommend actions. These are fundamentally different requirements and they demand a fundamentally different architecture.
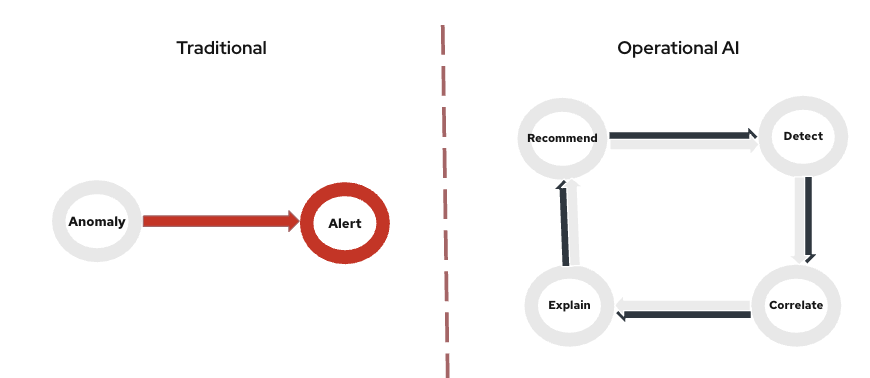
Fig: Traditional monitoring stops at alerting, while operational AI detects, correlates, explains, and recommends remediation.
The shift is from monitoring systems to operational AI systems. And most telecommunications service providers are partway through that journey without a clear map to follow.
Consider a common telco scenario.
A predictive AI model analyzing authentication traffic suddenly flags an anomaly. The model has learned the normal baseline of authentication success rates across millions of sessions. In this case, it detects a sudden spike in authentication retries across a group of access points.
A traditional monitoring system might simply trigger an alert.
But an operational AI system continues the investigation.
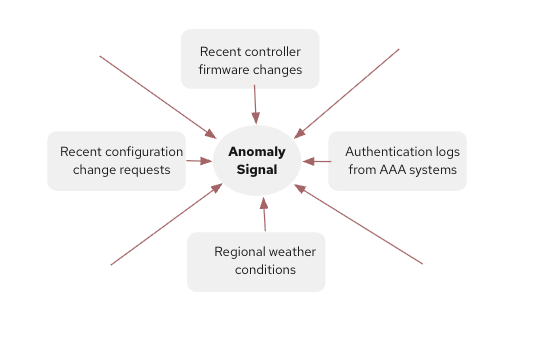
Fig: An anomaly signal becomes meaningful when correlated with configuration changes, authentication logs, and environmental context.
The anomaly signal triggers a reasoning layer that correlates additional signals:
- Recent controller firmware changes
- Authentication logs from AAA systems
- Regional weather conditions affecting connectivity
- Recent configuration change requests
The system then produces a likely explanation, that the authentication failures are correlated with a controller firmware upgrade deployed 2 hours earlier. TLS handshake behavior changed, causing authentication retries for legacy client devices.
The system then recommends an action:
- Validate controller configuration
- Roll back the firmware change
- Apply updated authentication policies
The operator reviews the recommendation before executing remediation.
In this model, predictive machine learning (ML) detects the anomaly, while language models interpret operational context and generate remediation guidance.
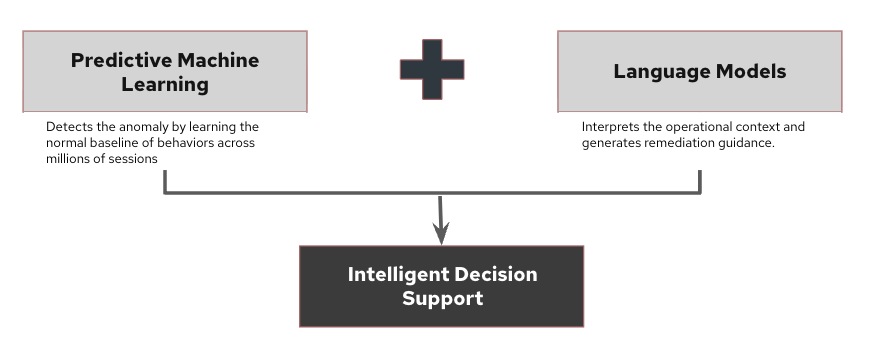
Fig: Predictive models detect anomalies while language models interpret operational context and recommend remediation.
Together, they move network operations beyond monitoring toward intelligent decision support.
3 phases most operators recognize
The maturity path follows a recognizable arc. Most operators are already deep into phase 1 or 2, and struggling with the transition into phase 3.

Fig: Many telco operators reach strong analytics maturity but stall before operationalizing AI.
Phase 3 is where organizations typically stall. Models exist in notebooks. Pipelines are stitched together with scripts. The problem is not a lack of data science capability, it is a missing architectural layer.
The symptoms are familiar: A data science team delivers a promising anomaly detection model, but it lives in a Jupyter notebook with no path to production. A second team builds a pipeline that works, until a data schema changes upstream and breaks silently. A third team deploys a model but has no way to audit which version is running, or whether it has drifted from its original validation baseline. None of these are data science failures. They are infrastructure failures. And they repeat across every organization that tries to operationalize AI on top of tools designed for data engineering.
This is also where automated machine learning (AutoML) becomes relevant. AutoML addresses a specific and common bottleneck: The time and expertise required to experiment with model architectures, tune hyperparameters, and select the best performing approach for a given dataset. In telco environments, where signal characteristics differ across network domains and change over time, the ability to rapidly train and evaluate candidate models without manual iteration accelerates the path from data to production. When AutoML is integrated with a governed model registry and deployment pipeline, experimentation stops being a research activity and becomes a repeatable operational process.
The transition from experimentation to operational AI is where most organizations encounter architectural friction.
Data science pipelines were never designed for AI lifecycle management
Data engineering platforms excel at ingesting, transforming, and preparing data at scale. But when teams attempt to operationalize ML, 4 structural challenges appear:
- Model lifecycle: Tracking versions, validation results, and production deployments across teams quickly becomes unmanageable without a dedicated registry.
- Inference at scale: Operational models must evaluate telemetry continuously and in real time, a pattern extract, transform, load (ETL) architectures were not designed to support.
- Governance and collaboration: When multiple teams build models that must be shared and audited, shared management breaks down without a common platform.
- System integration: Models need to connect with dashboards, alerting systems, and automation tools—connections that are difficult to maintain ad hoc.
The missing layer: A dedicated operational AI platform
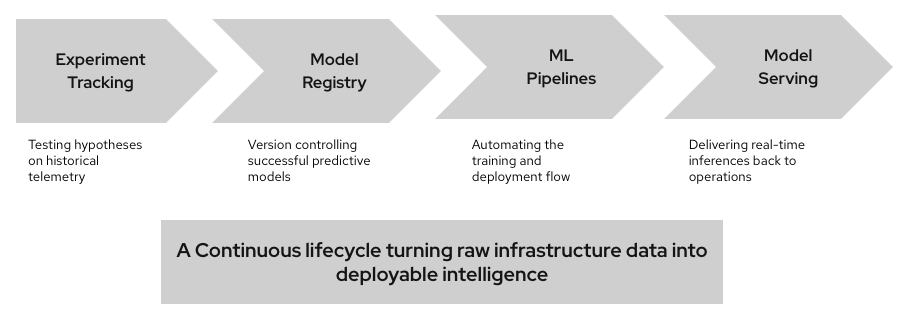
Fig: Operational AI requires a governed lifecycle from experimentation to production deployment.
The architecture evolves by introducing a dedicated operational AI layer between the data platform and network operations. This layer operationalizes the outputs of existing tools:
Network telemetry and ingestion | Existing infrastructure |
Data platform / lakehouse | Existing platform |
Red Hat OpenShift AI — Experiment tracking, model registry, ML pipelines, model serving | Operational layer |
Operational dashboards | Existing tools |
Automation | Red Hat Ansible Automation Platform, runbooks, etc. |
Red Hat OpenShift AI sits between the data platform and operational systems, providing consistent training environments, a governed model registry, scalable inference services, and continuous monitoring. It integrates with what operators already have rather than replacing it. Within this layer, predictive models detect abnormal behavior while generative models help interpret events and recommend remediation actions.
Fig: Traditional ETL to determine anomalies. |
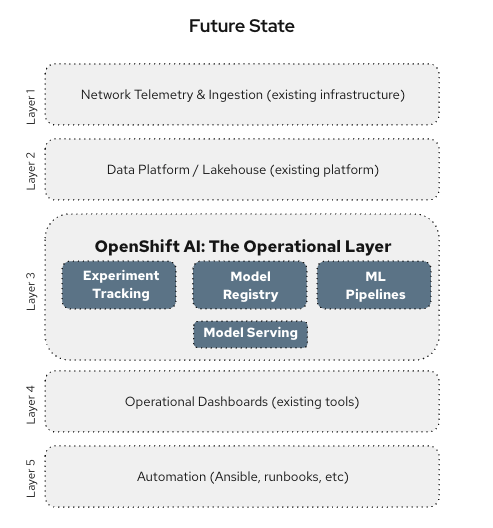
Fig: The operational AI platform layer connects data platforms to real network operations. |
Operational AI requires infrastructure that traditional data platforms were never designed to provide.
Analytics platforms excel at large-scale data processing and experimentation. But production AI requires something different—model lifecycle governance, low-latency inference services, consistent feature management, and deep integration with operational systems.
Without that platform layer, models remain experimental artifacts rather than operational systems.
Why use Red Hat OpenShift AI for telco operations?
OpenShift AI is purpose-built to address this gap with the following capabilities.
Model registry with full lineage. Every model version includes training data, hyperparameters, validation results, and deployment history that is tracked in a governed registry. When a model flags an anomaly at 2 a.m., operators can immediately see what version is running and whether it has drifted.
Real-time inference pipelines. Network telemetry cannot wait for batch scoring. OpenShift AI deploys models as scalable inference services that evaluate streaming data continuously. The same architecture that works for a single network operations center (NOC) today scales to distributed edge nodes tomorrow.
Feature store: Operational models cannot rely on raw telemetry alone. In ML, models do not analyze raw telemetry directly, they depend on structured signals derived from operational data such as authentication success rates, signal quality, firmware versions, or network congestion metrics. The OpenShift AI feature store maintains a centralized catalog of these signals, so models train and serve on consistent data, eliminating a common failure point in production AI deployments.
Consistent AI operations across hybrid infrastructure. Telco networks do not live in one place. Core analytics run in central data centers. RAN controllers sit at regional hubs. Inference needs to happen at the edge, close to the access points generating the telemetry. OpenShift AI deploys the same governed model lifecycle, registry, pipelines, inference services consistently across on-premises, cloud, and edge environments. A model trained centrally can be promoted and served at the edge without rebuilding pipelines or losing governance. For telco operators, consistency across deployment tiers is not a nice-to-have, it is an architectural requirement that makes operational AI viable at scale.
Automated model training and continuous retraining. Telco networks are not static. Device populations change, firmware updates shift baseline behavior, and 5G rollouts alter traffic patterns in ways that can cause previously reliable models to quietly degrade. OpenShift AI supports automated ML pipelines that go beyond initial training, triggering retraining workflows when model performance drifts, evaluating candidate models against current network conditions, and promoting updated models through the registry with full governance intact. For predictive AI to remain reliable in production, the pipeline that produced the model must be as operational as the model itself. AutoML capabilities within OpenShift AI make continuous model currency a platform feature rather than a manual engineering burden.
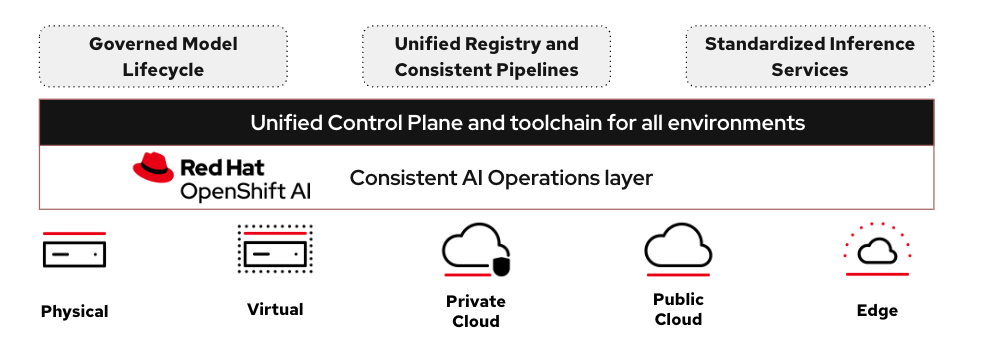
Fig: OpenShift AI brings together model registry, inference pipelines, feature management, hybrid deployment, and automated retraining into a single governed operational layer.
What operational AI actually unlocks
When the operational AI layer is in place, 4 compounding advantages become available:
- Predictive reliability: Detect abnormal patterns before customers experience failures. Move from reactive incident response to proactive prevention.
- Faster root-cause analysis: Correlate signals across systems to identify likely causes in seconds rather than hours of manual triage.
- Operational efficiency: Engineers redirect time from manual incident triage to higher-value network improvement and optimization work.
- Scalable operations: As networks expand into 5G and edge, automated intelligence scales naturally and human bandwidth is no longer the ceiling.
The operational impact compounds. Automated root-cause correlation reduces mean time to resolution—what previously required 2-4 hours of manual triage across multiple teams can be surfaced in minutes. Engineers who spent 60–70% of their time on reactive incident investigation are able to redirect that capacity toward network optimization and architecture work. And as 5G and edge deployments increase the number of network nodes by an order of magnitude, automated intelligence is able to make use of it to scale up without a proportional increase in NOC staffing.
5 stages toward fully autonomous networks
Each of these stages builds on the previous. Organizations do not skip steps but, with the right platform foundation, they move through them significantly faster:
- Rule-based anomaly detection
- ML models for predictive insights
- AI-assisted root cause analysis (RCA)
- Human-in-the-loop remediation recommendations
- Autonomous network optimization and self-healing networks—the destination
OpenShift AI is designed to accelerate the transition from stage 2 through stage 4, giving teams the governed infrastructure to move from ML experimentation to human-in-the-loop operational deployment.
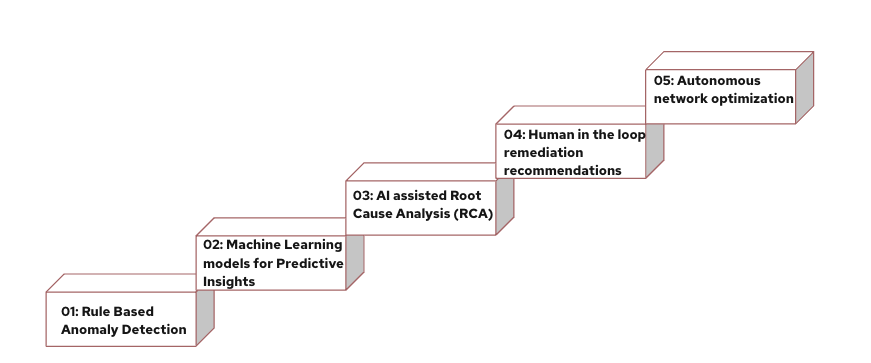
Fig: With the right platform, organizations move faster through these stages.
Final thoughts
For network operations and infrastructure leaders ready to close the gap between data and action, OpenShift AI provides the platform layer that helps move AI models from notebooks to governed production, with real-time inference, full model lifecycle management, and integrations that work with the data platforms, dashboards, and automation tools already in place.
The organizations that operationalize AI now will not just respond to network problems faster, they will stop many of them before customers notice. That is the operational advantage OpenShift AI can help deliver.
Talk to a Red Hat telco specialist to map your current AI maturity stage to a concrete deployment path.
关于作者
Vikas Grover is a senior leader in the Telco vertical at RedHat. In his role, he focuses on assisting customers with 5G deployments, intelligent self-configuring systems, service mesh, and O-RAN using Red Hat Technologies. He has over 15 experience in the software industry and has been at Red Hat for over six years. Vikas is also a contributing member to the ETSI-MEC ctandards body.






