As Data Science teams need to move from exploratory analysis to getting their models trained, served, and optimized in production, they need to build out a set of MLOps tools to automate their Machine Learning lifecycle. Machine Learning Ops is a complex field requiring a great deal of time and, more often than not, a separate set of skills, ranging from Data and System engineering to Cloud architecture. Deploying “data science” into production is challenging at best.
Starting February 22, 2022, Pachyderm Community Edition became available on Open Data Hub. Users are able to leverage Pachyderm’s Operator and get the platform running quickly, lowering their MLOps entry cost.
Ease the transition to MLOps with Open Data Hub.
For those unfamiliar with Open Data Hub (ODH)*, ODH is an open-source project that provides a blueprint for building an AI as a service platform on Kubernetes-based Red Hat OpenShift and associated products in Red Hat’s portfolio, like Ceph Object Storage.

Open Data Hub brings together different open-source AI tools into a one-stop install. The click of a button starts Red Hat OpenShift with the installed Open Data Hub Operator. Within the platform, data scientists can create models using Jupyter Notebooks and select from popular tools for developing and deploying models.
As a result, data scientists can save time setting up a stable and scalable AL/ML environment with Open Data Hub. Read about “How Red Hat data scientists use and contribute to Open Data Hub” and get more insights on what Open Data Hub offers to the Data Science world.
* Note that ODH is the open source community project that inspired and provides the technology basis for Red Hat OpenShift Data Science. Red Hat OpenShift Data Science is a cloud service that provides a subset of the technology offered in Open Data Hub, but provides additional support from the Red Hat team. Pachyderm partnered with Red Hat to make its Enterprise product available on RHODS.
Future-Proof Your MLOps Stack with Pachyderm

[Pachyderm](http://pachyderm.com) provides a data foundation for the Machine Learning lifecycle. It provides the data layer that powers the entire [ML loop](jimmymwhitaker.medium.com/completing-the-machine-learning-loop-e03c784eaab4) by bringing petabyte-scale data versioning and lineage tracking as well as fully autoscaling and data-driven pipelines.
Having Pachyderm as this foundational backbone for a modern MLOps stack allows you to:
-
Automate your data tasks into flexible pipelines. These pipelines are code and framework agnostic so you can use the best tools for your particular ML applications.
-
Scale and optimize for large amounts of unstructured and structured data. Everything in Pachyderm is a file, therefore Pachyderm works with any type of data -- images, audio, CSV, JSON data… It is designed to automatically parallelize your code to scale to billions of files.
-
Process data incrementally. Pachyderm comes with unique capabilities such as incremental processing where it only processes diffs or changes to your data thus reducing processing time by an order of magnitude.
-
Version all changes to your data -- including metadata, artifacts, and metrics -- providing an end-to-end reproducibility and immutable data lineage. This significantly reduces the effort to debug issues and helps satisfy data governance and audit requirements. Note that Pachyderm’s data lineage is IMMUTABLE, ENFORCED, and AUTOMATIC. You cannot run a Pachyderm process without lineage being recorded. It is all tracked behind the scenes as a fundamental property of the data, without ML teams needing to do anything themselves.
Pachyderm Enterprise builds on top of its Community Edition to provide additional features such as Console (Pachyderm UI), User Access Management, and reliable support from the Pachyderm team. Contact Pachyderm for more information at info@pachyderm.io, or subscribe to Pachyderm on Red Hat marketplace.
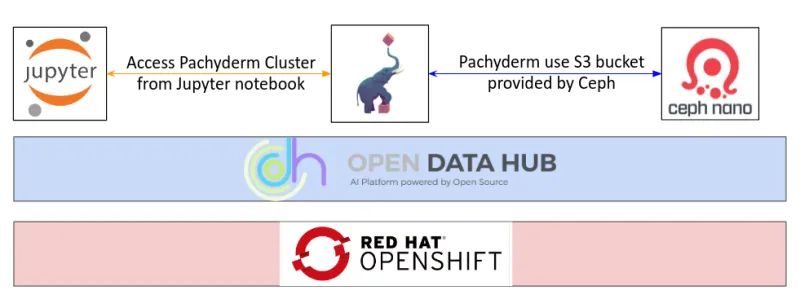
Pachyderm’s high level Architecture
Before diving into Pachyderm’s installation guide leveraging the Pachyderm Operator, let’s take a quick look at the architectural layers at play.
- Open Data Hub Operator is installed on the OpenShift Cluster.
- Open Data Hub Operator installs Jupyterhub/Pachyderm Operator/Ceph Nano.
- Ceph creates a new object storage (S3 bucket compatible).
- Pachyderm cluster uses the object storage provided by Ceph.
- Jupyter notebook access Pachyderm cluster.
Note that Open Data Hub comes integrated with many components, including Ceph Nano/JupyterHub making the deployment of Pachyderm relatively easy.
Follow the installation guide for more step-by-step details, then get started with Pachyderm’s canonical starter demo.
Additional resources:
关于作者

Jooho Lee is a senior OpenShift Technical Account Manager (TAM) in Toronto supporting middleware products(EAP/ DataGrid/ Web Server) and cloud products (Docker/ Kubernetes/ OpenShift/ Ansible). He is an active member of JBoss User Group Korea and Openshift / Ansible Group.







