Federated AI inverts the traditional machine learning paradigm. Instead of bringing data to the model, it brings the model to the data. Training happens locally on distributed nodes (i.e., hospitals, banks, and edge devices), and only model updates are shared with a central coordinator. The raw data never leaves its source. We will discuss this approach and how it enables collaborative AI while addressing privacy regulations (i.e., GDPR-EU data protection and HIPAA-US healthcare privacy) and data sovereignty requirements critical for healthcare, finance, and cross-border deployments.
In this post, we show how Flower-combined with Open Cluster Management, the open source foundation of Red Hat Advanced Cluster Management for Kubernetes-provides a production-ready solution for deploying federated AI at enterprise scale.
Flower: The industry-standard for federated AI
Flower is currently one of the most popular open-source frameworks for federated AI in the world. Built with a deep understanding of distributed training challenges, Flower provides a remarkably simple yet powerful abstraction that allows researchers and engineers to port their existing machine learning code—whether PyTorch, TensorFlow, JAX, or scikit-learn—to a federated environment with no changes. The same Flower app can be executed in both simulation for experimentation and deployed to production. This "write once, federate anywhere" philosophy has driven its rapid adoption.
The framework's elegance has attracted widespread enterprise adoption. Technology giants like Samsung and Nokia Bell Labs use Flower for on-device machine learning. Financial institutions such as JP Morgan and Banking Circle leverage it for privacy-preserving fraud detection. Healthcare institutions like the National Health Service (NHS) in the UK and Owkin are pushing open science with Flower. Research institutions and universities (including Stanford, Cambridge, MIT, Harvard, Gachon University, and TUM) have embraced it for cross-institutional collaboration.
The community is also vibrant: Flower’s GitHub repository has accumulated 6,600+ stars and 170+ contributors.Flower is an Apache 2.0 licensed open source project with an active community and enterprise support path. It continues to gain momentum among organizations exploring privacy-preserving machine learning at scale.
Flower architecture
Federated AI typically follows a hub-and-spoke topology where one central server coordinates training while multiple clients execute tasks locally. The server distributes model weights and training instructions; clients perform local training on private data and return only model updates—never raw data. Figure 1 shows the topology adopted in Flower.

(Image from flower.ai/docs/framework/explanation-flower-architecture.htm ©2026, Flower Labs. Used with permission under Apache 2.0 )
Flower uses a pull-based communication model where clients initiate connections to the server, not the other way around. This design has significant advantages. Only the server needs to be publicly accessible, simplifying firewall configuration and enhancing security for edge deployments. This also makes Flower particularly suited for federated AI across secure enclaves or regulated data environments, where traditional push-based architectures are not an acceptable option.
From server-client to SuperLink-SuperNode
While the basic server-client model works, it tightly couples the federated AI application with network infrastructure. Every federated AI project must handle:
- Network connection management
- Client registration and heartbeats
- Task distribution and result collection
- Failure recovery and reconnection
Flower solves this by introducing SuperLink and SuperNode. These are long-running infrastructure processes that handle all network communication, allowing developers to focus purely on their machine learning (ML) logic (Figure 2).
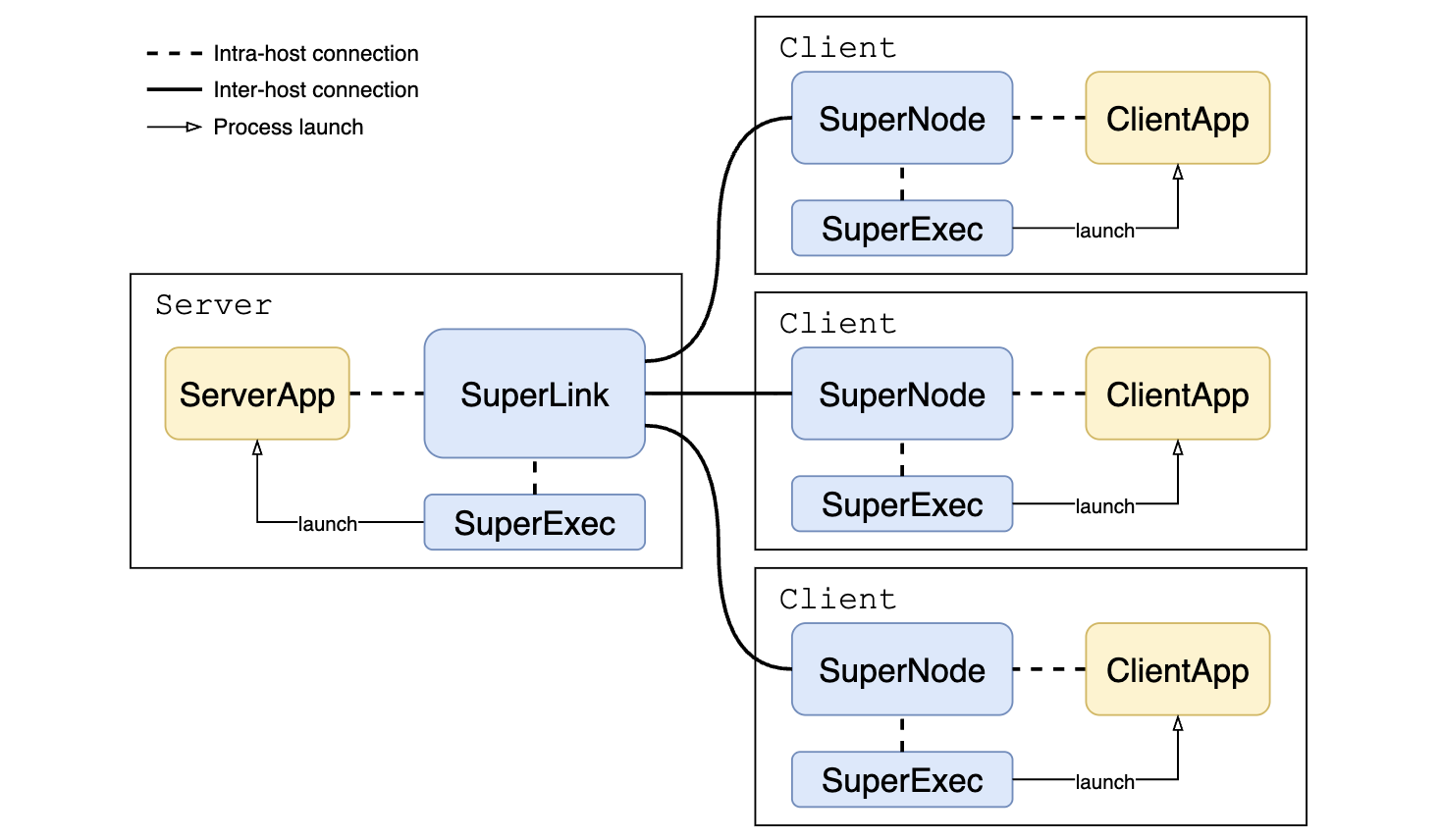
(Image from flower.ai/docs/framework/explanation-flower-architecture.html, copyright ©2026, Flower Labs. Used with permission under Apache 2.0)
SuperLink and SuperNode are long-running processes that persist across multiple federated AI projects. ServerApp and ClientApp are short-lived processes that contain project-specific ML logic.
This separation means:
- Reusable network setup: The SuperLink-SuperNode connection is established once and reused.
- Multi-run capability: Different federated AI projects can share the same infrastructure.
- Clean abstraction: Developers implement only ServerApp (aggregation logic) and ClientApp (local training/evaluation)— the infrastructure layer handles all network communication.
- Easy migration: You can port traditional ML training code to federated environments with minimal changes by wrapping existing training logic in the ClientApp.
ML framework agnosticism
Flower supports all major ML frameworks—PyTorch, TensorFlow, JAX, scikit-learn, Hugging Face, and more. Organizations can federate their existing ML pipelines without rewriting model code. Together with SuperLink and SuperNodes, different Flower apps written with any framework can therefore be executed on persistent infrastructure, which significantly reduces the setup of a federated AI system.
Deployment at scale
Federated AI solves the abstraction problems of distributed training, such as aggregation strategies, model parameter distribution, and coordination. But to deploy it efficiently on enterprise devices or cloud platforms, significant operational challenges remain.
While Flower provides Docker deployment guides and Helm charts for deploying SuperLink and SuperNode, scaling these deployments to production-scale environments with meaningful numbers of devices or data silos typically requires more streamlined and repeatable setup and management.
Deploy federated AI at enterprise scale
There are several things required to deploy federated AI at enterprise scale, such as efficient deployment, automated security, dynamic scheduling, lifecycle management, and app distribution.
For efficient deployment, define the desired state once and let the infrastructure handle convergence. This is needed to reduce manual intervention and configuration drift as deployments grow.
Automated security is also required. Automated certificate provisioning and rotation for TLS connections between SuperLink and SuperNode provides for security-enhanced communication at scale without introducing operational overhead or human error.
With dynamic scheduling, you can automatically select devices based on labels, resources, or availability. This places workloads efficiently across heterogeneous and changing environments.
You also need lifecycle management to handle node failures, updates, and scaling automatically to maintain reliability and continuity without requiring constant operator involvement.
For app distribution, you need to automatically deploy ClientApps to suitable SuperNodes. This allows the on-demand orchestration of ClientApp hosts with isolated dependencies to connect to SuperNodes. This deployment pattern is compatible with the Flower Isolation Model where SuperLink and SuperNodes run in process mode.
Open Cluster Management (OCM) provides an intuitive and native solution for these requirements.
The solution: Open Cluster Management
OCM is a CNCF Sandbox project that provides multi-cluster management for Kubernetes. It is the upstream project for Red Hat Advanced Cluster Management for Kubernetes (ACM), which already manages thousands of production Kubernetes clusters across enterprises worldwide. The patterns described below work in both OCM and ACM environments.
Hub-spoke architecture
OCM uses a hub-spoke model that mirrors Flower's SuperLink/SuperNode topology. Figure 3 shows the Open Cluster Management architecture.
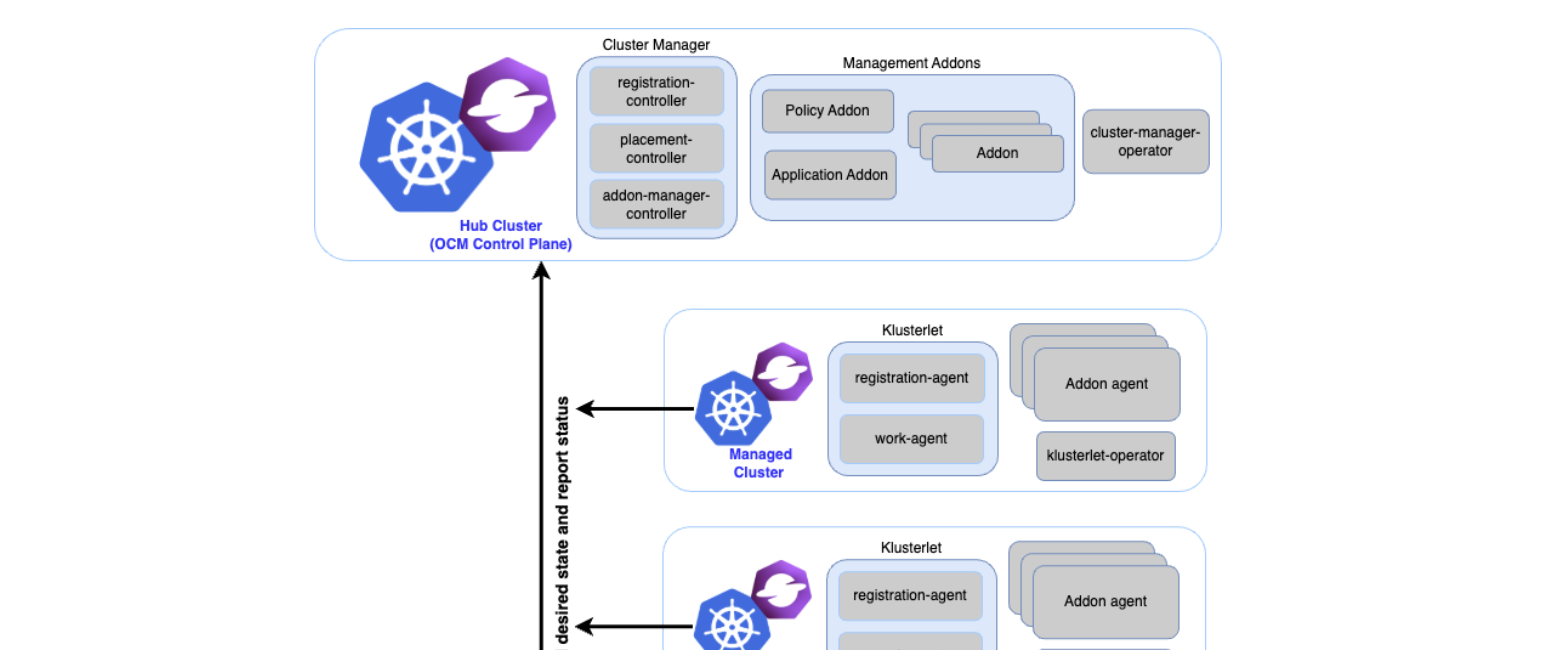
(Used with permission under Apache 2.0.)
Key OCM components
The Addon Framework provides a pattern for deploying and managing agents across managed clusters. Figure 4 illustrates the addon architecture of open cluster management.
It handles:
- Distributed deployment: Define an addon once (
ClusterManagementAddOn), OCM automatically createsManagedClusterAddOninstances on target clusters - Security-focused communication: Built-in certificate management for addon-to-hub authentication—no manual TLS configuration
- Lifecycle management: Automatic installation, upgrade, and health monitoring

(Used with permission under Apache 2.0)
The Placement API enables flexible cluster selection based on labels, resources, or custom predicates:
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: gpu-clusters
spec:
predicates:
- requiredClusterSelector:
labelSelector:
matchLabels:
gpu: "true"When combined with addons, Placement enables dynamic scheduling—clusters matching the criteria automatically receive the addon deployment.
The Work API distributes Kubernetes resources to managed clusters:
- ManifestWork: Deploy manifests to a specific cluster
- ManifestWorkReplicaSet: Combine with Placement for batch distribution—deploy manifests to all clusters matching the placement criteria
This enables declarative workload distribution across the fleet without manual per-cluster deployment.
OCM vs. Flower
Flower offers architectural alignment. Both Flower and OCM adopt a hub-spoke architecture with pull-based communication. In both systems, spoke components (SuperNode / Klusterlet) initiate connections to the hub—meaning only the hub needs to be publicly accessible. This shared network model means Flower can run on OCM-managed clusters without additional network topology or infrastructure changes.
This provides component correspondence. This shared architecture creates a natural mapping between Flower and OCM components in which each core Flower component has a direct counterpart in OCM that serves the same role.
- SuperLink → Hub Cluster: Central coordinator that orchestrates the federation
- SuperNode → Managed Cluster (Klusterlet): Distributed agent that executes tasks locally
- Flower ClientApp → ManifestWork: Workload distributed to spoke nodes for execution
It also provides functional complementarity. At a deeper level, the distribution requirements of SuperLink and SuperNode align precisely with OCM's addon management capabilities as follows:
- SuperNode deployment → Addon Framework handles per-cluster agent deployment with secure certificate management
- ClientApp distribution → Work API (
ManifestWorkReplicaSet) automates workload distribution across the fleet - SuperNode and ClientApp scheduling → Placement API selects target clusters or devices based on labels, resources, or status
This alignment positions OCM as a native platform for deploying Flower at scale.
How the flower-addon integration works
The flower-addon bridges Flower and OCM, enabling declarative deployment of federated AI infrastructure across multi-cluster Kubernetes environments. You can refer to the repository for more details.
The flower-addon manages the full lifecycle of Flower infrastructure across clusters through four stages.
Stage 1:
The ClusterManagementAddOnresource registers flower-addon on the hub cluster. It defines the SuperNode deployment template via AddOnDeploymentConfig, configures global variables (e.g., SUPERLINK_ADDRESS), and specifies how ManagedClusterAddOn (SuperNode) instances are distributed across clusters.
Stage 2:
For SuperNode deployment, each managed cluster receives a ManagedClusterAddOn resource that represents and manages its SuperNode instance. This enables the following:
- Automatic secure connection to SuperLink via addon auto-registration
- Per-cluster configuration via
AddOnDeploymentConfig(e.g.,PARTITION_ID) - Status collection and health monitoring
Stage 3:
Dynamic scheduling involves the Placement API selecting target clusters/devices based on labels, resources, or status to launch the ManagedClusterAddOn. As clusters join or leave the placement criteria, SuperNodes are automatically added or removed, enabling horizontal scaling.
Stage 4:
ManifestWorkReplicaSet combined with Placement provides declarative, policy-driven distribution of ClientApps across the fleet. Placement can pin ClientApps to clusters with available SuperNodes automatically and apply additional scheduling constraints, such as GPU availability, region affinity, or resource capacity. This enables precise workload placement across heterogeneous environments without manual per-cluster configuration.
The ecosystem value
The flower-addon represents a convergence point for two communities tackling complementary challenges.
For the Flower community, this integration streamlines deployments. With OCM handling the complexity of multi-cluster deployment, security-centric communication, and dynamic scaling, Flower users can more easily deploy and manage production federations spanning hundreds of clusters—from edge devices to cloud regions. The declarative approach that Kubernetes users expect for traditional workloads now extends naturally to federated AI infrastructure.
For the OCM community, flower-addon opens doors to the rapidly growing federated AI ecosystem, demonstrating that OCM is not just for traditional applications but a genuine platform for distributed computing. The patterns established here—using the addon framework for agent deployment, Placement for scheduling, and ManifestWorkReplicaSet for workload distribution—can serve as templates for integrating other distributed frameworks like Apache Spark, Ray, or Dask.
For the broader industry, this integration provides a production-ready path for privacy-preserving AI. Organizations can train models across data silos without centralizing sensitive information—addressing GDPR, HIPAA, and data sovereignty requirements. Organizations using Red Hat Advanced Cluster Management for Kubernetes can leverage their existing multi-cluster infrastructure to explore federated AI workloads with this pattern.
Get started
The integration of the Flower federated AI framework with OCM provides a robust, scalable, and declarative path for enterprise-grade federated learning. By using OCM’s native multi-cluster management capabilities—including the Addon Framework for SuperNode deployment, the Placement API for dynamic scheduling, and the Work API for ClientApp distribution—organizations can overcome significant operational hurdles in deploying privacy-preserving AI. The resulting flower-addon not only simplifies the infrastructure for Flower users but also establishes OCM as a key platform for distributed machine learning workloads.
Be sure to check out the installation, placement, and training demos. We encourage you to explore the Flower Addon repository and join the discussion on the OCM Slack #open-cluster-mgmt channel or the Flower Slack to start building your own scaled federated AI solution.
References
Flower Documentation
OCM Documentation
Flower Addon
关于作者

Meng Yan is a Senior Software Engineer at Red Hat, specializing in event-driven architectures for multi-cluster management at scale. His research interests focus on agentic AI systems and intelligent automation for software engineering, as well as AI/ML applications in distributed environments such as federated learning and multi-cluster inference.







