Thanos is a project that turns your Prometheus installation into a highly available metric system with unlimited storage capacity. From a very high-level view, it does this by deploying a sidecar to Prometheus, which uploads the data blocks to any object storage. A store component downloads the blocks again and makes them accessible to a query component, which has the same API as Prometheus itself. This works nicely with Grafana because its the same API. So without much effort, you can view your nice dashboard graphs beyond the configured retention time of your Prometheus monitoring stack. and get an almost unlimited timeline , only restricted by object storage capacities.
On top of these already awesome features, Thanos also provides downsampling of stored metrics, deduplication of data points and some more.
Motivation
We are mostly interested in the long-term storage of several months worth of Prometheus metrics. For our data science work, we need more than just a couple of days worth of data. We might want to go back months in time. Still, we don't want to add more complexity to the tooling, we want to stay with the Prometheus query API and PromQL we already know.
We're can re-use our Grafana dashboards, ML Containers and Jupyter Notebooks
Setup
We are using the S3 access points from Ceph to store the Time Series DB (TSDB) blocks in a bucket. We also need to deploy on top of a managed Red Hat OpenShift installation, so we can't tune any network configurations or use cluster admin for our setup.

The first problem we've encountered is the gossip protocol that Thanos uses to find new nodes added to the Thanos cluster. But as we just want to store blocks from a single Prometheus instance, we're not really interested in the clustered setup. To get around this, you have to tell every Thanos component to listen to a cluster address, but don't use it for cluster discovery. Instead, use the “--store” flag to specify the nodes directly. And gossip is probably being removed from Thanos anyway, so :shrug:
We're also building on top of the OKD prometheus examples, hence you'll see diffs in this post, which should be easy to apply to your setup.
Just the sidecar
This is the least intrusive deployment. You can just add this without interfering with your Prometheus setup at all.
One thing that you might need to add to your Prometheus configuration is the external_labels section and “--storage.tsdb.{min, max}-block-duration” setting. See the sidecar documentation for the reasoning.
Here are the full deployment template and the diff to the original deployment template.
oc process -f ./prometheus_thanos_sidecar.yaml --param THANOS_ACCESS_KEY=abc --param THANOS_SECRET_KEY=xyz | oc apply -f -
Deploying this will store the TSDB blocks in the configured S3 bucket. Now, how would you query those offloaded blocks?
Thanos Query
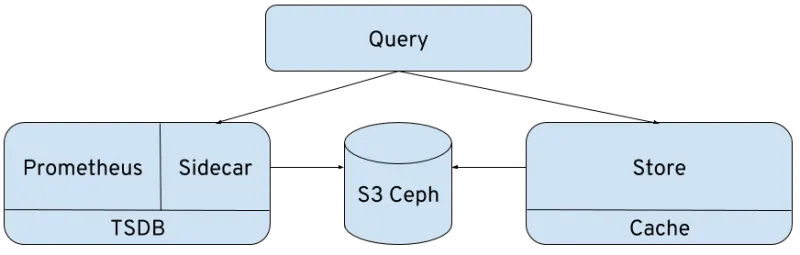
Now we've added Thanos Query, a web and API frontend which looks like Prometheus but is able to query a Prometheus instance and a Thanos Store at the same time. This gives you transparent access to the archived blocks and real-time metrics.
oc process -f ./prometheus_thanos_full.yaml --param THANOS_ACCESS_KEY=abc --param THANOS_SECRET_KEY=xyz | oc apply -f -
Wrap Up
You should start with just the sidecar deployment to start backing up your metrics. If you don't even want to fiddle with the Prometheus setup or you don't have access to it, you can also use the federate API from Prometheus to deploy another instance just for doing the backup. This is actually how we do it because other teams run the production Prometheus.
Then let it run for a couple of days and estimate the storage requirements.
After this, have fun with the query and store component and enjoy your way back in time of metrics.
A maintained version and code can be found at GitHub - AICoE/thanos-openshift: Thanos on OpenShift







