Metering Operator 是一种用于 Kubernetes 集群的计费和报告工具,用来统计 Kubernetes 集群中不同资源的使用情况。集群管理员可以根据容器集、命名空间和整个集群范围的历史使用数据来安排报告。
安装 Metering Operator 后,许多报告查询都可以直接使用。例如,如果管理员希望测量集群节点(或容器集)的 CPU(或内存)使用情况,只需安装 Metering Operator 并编写 Report 自定义资源,即可生成报告(按照每月、每小时等时间间隔)。
用例
我经常从客户那里听到一些需求。
- 在非生产环境中 OpenShift 集群中,工作节点可能不会一直运行(例如,管理员希望基于可用容量或在周末关闭一些工作节点)。因此,他们希望每月测算一次节点的 CPU(或内存)使用情况,以便基础架构团队根据实际的节点使用情况向用户计费。
- 客户通过一个部署模型为特定团队部署专用的 OpenShift 集群。客户可以安装 Metering Operator 并获取节点使用情况,不过,客户希望计费报告中列明工作节点所属的团队(或业务线)。此用例也可以延伸至共享专用集群具有“标记”节点的情况,每个标签都可以标识节点上运行的工作负载属于哪个业务线/团队。
- 在共享集群中,运维团队希望根据容器集的运行时间(也可以是 CPU 或内存消耗情况)向团队计费。他们也希望简化报告,使其包含容器集所属的团队(或业务线)。
要满足上述需求,需要在集群中创建一些自定义资源,我们将在本文中学习如何轻松执行此操作。请注意,安装 Metering Operator 的操作步骤不在本文的讨论范围内。您可以在此处参阅安装文档。如需进一步了解如何使用预设的报告,请点击此处参阅文档。
Metering 的工作原理是什么?
在为前面提到的用例创建新的自定义资源之前,我们先了解一下 OpenShift Metering 的工作原理。安装 Metering Operator 后,一共会创建 6 个自定义资源。在这 6 个自定义资源中,我们将详细介绍以下资源。
- ReportDataSources(rds):rds 是一种机制,用于定义哪些数据可用且可供 ReportQuery 或 Report 自定义资源使用。它还支持从多个来源获取数据。在 OpenShift 中,将从 Prometheus 和 ReportQuery(rq)自定义资源中拉取数据。
- ReportQuery(rq):rq 包含对通过 rds 存储的数据执行分析的 SQL 查询。如果 Report 对象引用了一个 rq 对象,那么当运行报告时,则 rq 对象还将管理将报告的对象。如果被 rds 对象引用,rq 对象将指示 Metering 基于呈现的查询在 Presto 表中创建视图(作为 Metering 安装的一部分进行创建)。
- Report:此自定义资源可通过配置的 ReportQuery 资源生成报告。这是 Metering Operator 的最终用户将与之交互的主要资源。报告可以配置为按计划运行。
许多 rds 和 rq 都可以直接使用。我们的重点是节点级计量,因此,我将展示在自行编写自定义查询时需要熟悉的资源。在“openshift-metering”项目中运行以下命令:
$ oc project openshift-metering $ oc get reportdatasources | grep node node-allocatable-cpu-cores node-allocatable-memory-bytes node-capacity-cpu-cores node-capacity-memory-bytes node-cpu-allocatable-raw node-cpu-capacity-raw node-memory-allocatable-raw node-memory-capacity-raw |
我们需要关注以下两个 rd:“node-capacity-cpu-cores”和“node-cpu-capacity-raw”,因为我们需要测量 CPU 消耗情况。我们先来看看 node-capacity-cpu-cores,并通过运行以下命令来了解它如何从 Prometheus 中收集数据:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml spec: prometheusMetricsImporter: query: | kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id) |
您可以观察用于从 Prometheus 中获取数据并将数据存储在 Presto 表中的 Prometheus 查询。我们在 OpenShift 的指标控制台中运行相同的查询并查看结果。某个 OpenShift 集群包含 2 个工作节点(每个节点 16 个核心)和 3 个主节点(每个节点 8 个核心)。最后一列“value”记录的便是分配给节点的核心数。

因此,数据将被收集并存储在 Presto 表中。现在,我们重点关注几个 ReportQuery(rq)自定义资源:
$ oc project openshift-metering $ oc get reportqueries | grep node-cpu node-cpu-allocatable node-cpu-allocatable-raw node-cpu-capacity node-cpu-capacity-raw node-cpu-utilization |
我们要重点关注“node-cpu-capacity”和“node-cpu-capacity-raw”rq。您可以对这些 ReportQuery 进行描述,并弄清楚它们计算的数据(如节点运行时长、分配的 CPU 数量等)和聚合的数据。
下图显示了两个 rds 和两个 rq 如何实现连接的关系链。
node-cpu-capacity (rq) 使用 node-cpu-capacity-raw (rds) 使用 node-cpu-capacity-raw (rq) 使用 node-capacity-cpu-cores (rds)
自定义报告
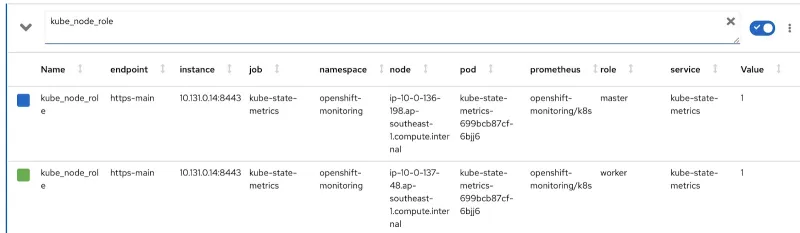
现在我们重点介绍如何编写自定义的 rds 和 rq。首先,我们需要更改 Prometheus 查询,使其包含节点作为主节点或工作节点运行,然后包含一个合适的节点标签以标识节点所属的团队。Prometheus 指标“kube_node_role”拥有与节点角色(作为主节点或工作节点)相关的数据。查看“role”列:
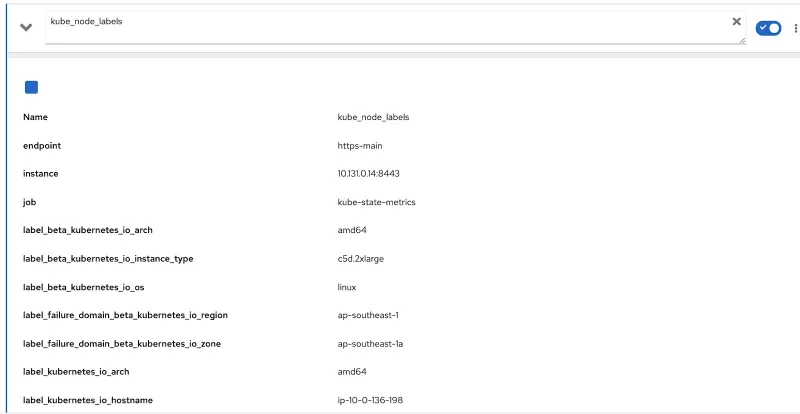
Prometheus 指标“kube_node_labels”将捕获节点上应用的所有标签。所有标签都将以 “label_”
现在,我们只需使用这两个额外的 Prometheus 查询修改原始查询以获取相关数据。此查询如下所示:
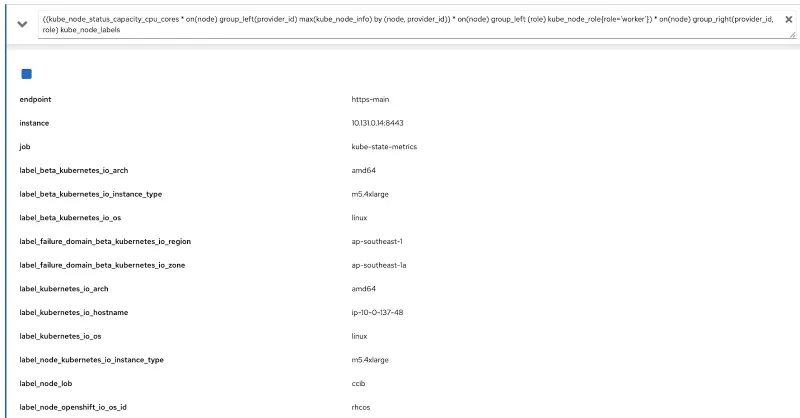
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
我们在 OpenShift 的指标控制台上运行此查询,并验证是否获得了标签(node_lob)和角色信息。下面,我们将 label_node_lob 同时作为输出和角色(您看不到角色信息的原因是查询输出了很多列,但确实捕获了):
因此,我们将编写 4 个自定义资源。为简单起见,我上传了以下自定义资源:
- rds-custom-node-capacity-cpu-cores.yaml:定义 Prometheus 查询
- rq-custom-node-cpu-capacity-raw.yaml:引用上述 rds;计算原始数据
- rds-custom-node-cpu-capacity-raw.yaml:引用上述 rq 并在 Presto 中创建视图
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml:引用上述第 3 点中提到的 rds 并根据输入的开始和结束数据计算数据。此外,这也是我们从中检索“role”和“node_label”列的文件。
编写完上述 yaml 文件后,前往“openshift-metering”项目并运行以下命令:
$ oc project openshift-metering $ oc create -f rds-custom-node-capacity-cpu-cores.yaml $ oc create -f rq-custom-node-cpu-capacity-raw.yaml $ oc create -f rds-custom-node-cpu-capacity-raw.yaml $ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml |
最后,您只需编写一个 Report 自定义对象,它将引用前面最后一次创建的 rq 对象。您可以参考如下所示进行编写。以下报告将立即运行,并显示 9 月 15 日至 30 日之间的数据。
$ cat report_immediate.yaml apiVersion: metering.openshift.io/v1 kind: Report metadata: name: custom-role-node-cpu-capacity-lables-immediate namespace: openshift-metering spec: query: custom-role-node-cpu-capacity-labels reportingStart: "2020-09-15T00:00:00Z" reportingEnd: "2020-09-30T00:00:00Z" runImmediately: true
$ oc create -f report-immediate.yaml |
运行此报告后,您可以通过以下 URL(请相应地更改域名)下载文件(CSV 或 JSON 格式):
以下 CSV 快照所示为同时包含“role”和“node_lob”列的已捕获数据。“node_capacity_cpu_core_seconds”列必须除以“node_capacity_cpu_cores”才能得出以秒为单位的节点运行时间:

总结
Metering Operator 非常出色,可以在 OpenShift 集群上的任何位置运行。它提供了一个可扩展的框架,方便客户自行编写自定义资源,根据自身的需求创建报告。前面使用的所有代码均可在此处取用。







