在上一篇文章中,我们重点介绍了如何通过针对特定领域的定制改造,将大语言模型(LLM)从通用工具转化为研究利器。研究团队借助微调模型,可把领域专业知识、机构研究成果与推理逻辑固化至系统中,从而加速科研突破,而非仅提供基础辅助。
然而,定制化模型只是解决方案的一部分。这些模型要在机构层面发挥作用,就需要一个平台,用于训练、部署、管理访问权限,并将其集成到更广泛的科研计算环境中。该平台必须能够连接研究人员现有的两大环境:一是运行 Slurm 工作负载管理器的传统高性能计算(HPC)集群,二是基于 Kubernetes、快速发展的云原生 AI 生态系统。
在本文中,我们将探讨这一平台的构建方式,让科研机构能够通过特定的架构实现 HPC 与云原生工作负载的融合,将定制化模型作为共享服务投入实际应用,并在确保治理能力、结果可复现及成本可控的前提下,面向整个组织提供生成式 AI 功能。
平台架构:各组件如何协同工作
明确了定制需求后,我们来看看整个平台是如何构建的。该架构具有通用性,适用于研究型大学、联邦政府资助的研究与开发中心、教学医院、能源企业或金融科研机构等各类主体。核心组件保持统一,仅需根据不同行业领域调整配置策略。
该平台的基础是红帽 OpenShift,这是一个 Kubernetes 发行版,提供平台工程师在机构层面运行共享 AI 基础架构所需的容器编排、命名空间治理、基于角色的访问权限控制(RBAC)、持久存储集成和运维工具。
在 OpenShift 的基础上,红帽 OpenShift AI 提供了特定于 AI 的功能,包括模型服务、模型定制、管道编排、面向数据科学家的 Notebook 环境,以及 AI 工作负载的可观测性。OpenShift AI 将基础 Kubernetes 平台转变为一个环境,研究人员可以通过受监管的自助服务界面来训练、微调、评估、部署和监控模型,而无需各团队管理自己的机器学习(ML)基础架构。
推理引擎采用 vLLM,通过 OpenShift AI 的模型服务层对外提供服务。凭借连续批处理和节省内存的注意力机制,vLLM 成为共享推理环境的理想之选,能够满足多个研究团队同时使用模型服务的需求。大多数科研机构普遍存在资源受限问题,而推理效率的高低直接关系到 GPU 预算的有效利用。
红帽和 NVIDIA AI 工厂硬件层则是红帽与 NVIDIA 协作的最直接体现。红帽和 NVIDIA AI 工厂 将 NVIDIA 的 GPU 硬件和 NVIDIA 推理微服务(NIM)框架与 OpenShift AI 的编排和治理功能相结合。NIM 容器封装了经过优化和验证的模型配置,可在 NVIDIA 硬件上直接提供服务,并且由于这些容器在 OpenShift 上运行,因此自然继承了平台的命名空间治理、RBAC 和可观测性堆栈。
对于正在部署 NVIDIA GPU 基础架构的科研机构(这也是大多数机构现状)而言,红帽和 NVIDIA AI 工厂参考架构提供了一套经过验证、可获得官方支持的落地方案,打通从硬件部署到推理服务上线的全流程,有效节省长达数月的集成工作量。NVIDIA 的 NIM 目录涵盖各大模型系列的基础模型,而 OpenShift AI 的定制管道则可在此基础上开展领域专属微调,实现模型能力拓展。两者结合,为研究机构提供了一条切实可行的路径:从“拥有 GPU”转变为“拥有能为研究人员提供服务的微调临床模型”。
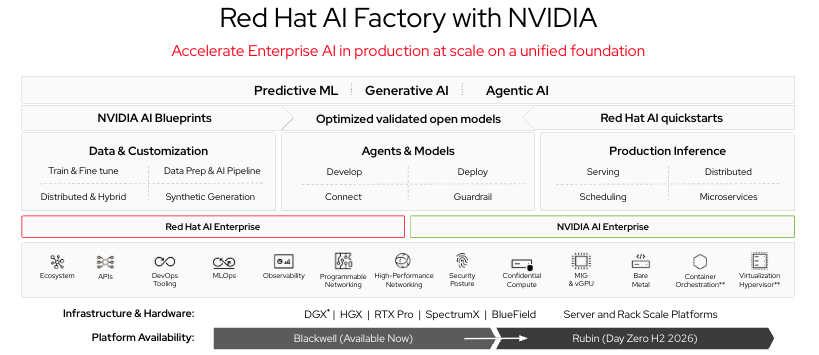
图 1:红帽和 NVIDIA AI 工厂
连接 HPC 和云原生:Slinky Operator
Slurm 为全球众多顶级超级计算机提供支持,是科研机构提交 HPC 作业的标准接口。Slurm 的优势显而易见,包括独占式 GPU 预留、可预测的性能、成熟的优先级排队机制以及与并行文件系统和消息传递接口(MPI)类工作负载的深度集成。大多数科研机构的 HPC 用户都熟悉 Slurm,且其管道也普遍基于 Slurm 开发搭建。
长期以来的挑战在于 Slurm 与 Kubernetes 两大环境之间的鸿沟:两个调度程序、两套资源核算系统、两种 GPU 请求方式、以及两支独立的运维团队。数据工件需要在不同环境间手动迁移;在业务低峰期,HPC 集群的 GPU 资源常常闲置,而 Kubernetes 环境却存在任务排队拥堵的情况。
Slinky Operator 正是为了解决这一难题而生的。正如本文关于在 OpenShift 上运行 Slurm 工作负载的讨论,Slinky 是一款 Kubernetes Operator,它能够将 Slurm 组件(包括 slurmctld 和 slurmd)作为容器化工作负载部署在 OpenShift 中并进行管理,从而自动化 Slurm 集群的部署、扩展和生命周期管理,使其能够与 Kubernetes 原生工作负载在同一硬件上共存。
这对科研平台工程师的实际意义在于:
- 统一资源调度:Slurm 批处理作业和 Kubernetes 原生 AI 工作负载共享同一个 GPU 池。在大型模拟作业之间的算力闲置期,系统无需人工干预或重新分配硬件,即可将算力自动分配给推理或微调工作负载。
- 保留研究人员现有工作流: 通过 sbatch 提交作业的 HPC 研究人员无需更改其工作流。他们熟悉的 Slurm 界面仍然存在,但现在也在 OpenShift 中运行,并具有 Kubernetes 提供的所有可观测性、生命周期管理和治理功能。
- 可重现的环境:Slurm 作业作为容器运行,这意味着环境由容器镜像定义,而不是由计算节点上安装的任何内容定义。这极大地提高了可重现性,并简化了希望共享管道的机构间的协作。
- 单一操作界面:平台工程师只需维护一个集群、一个可观测性堆栈和一个 RBAC 模型。Slinky 无需创建或增加额外的基础架构,而是将 HPC 调度功能整合到现有的平台中。
NVIDIA 收购了 Slurm 的核心研发厂商 SchedMD,标志着这种融合已成为行业趋势。HPC 调度、Kubernetes 编排和 AI 基础架构之间的界限正被有意识地打破,走向深度融合。Slinky 是红帽助力这场技术融合的成果,目前已可用于生产环境。
对于同时部署计算科学 HPC 集群与 AI 研究 OpenShift 环境的研究型大学而言,Slinky 可整合两类算力投入,发挥协同效应。
模型即服务(MaaS):面向科研机构的共享 AI 平台模型
平台融合解决了基础架构层面的难题,但还有一个同等重要、却较少被提及的问题:大多数研究团队并不配备基础架构工程师。一个致力于开发医疗公平智能咨询系统的临床信息学团队,并不希望将精力耗费在管理 Kubernetes 命名空间上。一个需要微调模型进行变异注释的基因组学实验室,并不想受困于 vLLM 的部署配置。而一个希望利用 LLM 进行文档分析的计算社会科学部门,也不愿将精力浪费在编写 Helm 应用模板上。
解决这一问题的运维模式是模型即服务(MaaS)。
什么是 MaaS?
MaaS 是一种方法,平台工程师可以将 AI 模型作为共享服务进行部署、管理和运维,并通过 API 向使用者开放。在科研机构场景中,这意味着科研计算平台团队负责运维 GPU 集群、管理模型生命周期、处理版本控制和更新,以及维护提供服务的基础架构,而研究团队则像使用计算配额或存储挂载一样,将模型端点作为一项服务来使用。
这对科研效率的提升影响深远。我们可以对比一下传统模式与 MaaS 模式下的工作流差异。
无 MaaS 的传统模式
某研究团队为开展项目需要使用一个微调模型。他们要花费数周时间来设置 GPU 环境、安装依赖项、配置服务框架并调试基础架构问题。只有在基础架构最终正常运行后,他们的实际研究才能开始,而这可能距离项目启动已经过去了数月。项目完成后,模型往往被闲置在某个人的工作站上,或保留在随后会被回收的临时集群资源中。
基于 OpenShift AI 的 MaaS 模式
研究团队将他们的数据集和业务领域要求提交给平台团队。他们与平台工程师合作,通过 OpenShift AI 上的训练中心配置和运行微调作业。生成的模型将作为共享集群上具有版本控制功能且受管控的 API 端点提供。具有相关需求的其他研究团队可以使用同一端点。使用新数据更新模型时,只需重新运行训练管道,并通过相同的受管控流程升级新版本。
平台团队负责基础架构,而研究团队负责科学研究。这种分工有助于在整个机构范围内扩展 AI 功能。

图 2:融合 HPC、云原生和模型即服务,助力科学研究
对平台工程师而言,OpenShift AI 上的 MaaS(不妨称之为“研究即服务”)提供了他们所需的运维控制能力:采用命名空间级的资源配额,避免单个研究项目独占 GPU 算力;通过镜像仓库实现模型版本控制;借助 RBAC 区分部署操作与访问使用人员的权限;以及通过统一信息面板,对所有模型服务的工作负载进行统一观测。
对于下设多个研究团队的科研机构(例如医学院、计算生物系、信息学院和数据科学研究院共用同一平台),MaaS 让平台运维团队无需随科研项目数量线性扩充人员编制,即可从容应对不断增长的业务需求。
数据引力:让 AI 贴近科研数据
科研领域普遍存在数据引力难题。最有价值的数据集(临床记录、基因组序列、模拟输出)本身就规模庞大、分散存储,并且由于成本、延迟或治理方面的限制,往往难以迁移。将 PB 级数据迁移到云端点不仅效率低下,而且通常不可能实现。
本文所述的一体化平台,秉持 AI 向数据靠拢的设计理念,而非反向迁移数据。通过在数据所在位置(本地环境、实验室、安全的研究环境等)运行模型训练、微调和推理,您可以避免不必要的数据移动,同时保障性能和合规性。
归根结底,这不仅仅是一种优化,更是一种架构要求。模型越接近数据,迭代循环越快,成本越低,在大规模研究工作流中将 AI 投入实际应用的可行性也就越高。
此架构适用的场景:跨行业研究
当然,这个平台并非仅适用于学术研究。任何机构只要满足以下条件,都可以采用这一架构:非常依赖领域专业知识、受数据治理限制而无法随意采用云原生部署、研究工作负载横跨 HPC 到云原生的整个范围。
- 研究型大学和联邦政府资助的研究与开发中心(FFRDC):大学和国家实验室等由联邦政府资助的研究与开发中心通常拥有这种架构所面向的基础架构环境,例如用于模拟密集型研究的 HPC 集群、数据科学团队日益增长的云原生 AI 需求,以及需要为众多计算需求各异的研究小组提供支持的平台工程团队。
- 医疗机构和教学医院:临床 AI 是科研投入增速最快的领域之一,同时对模型精度、数据治理与安全防护有着严苛要求。受患者数据隐私合规要求限制,通用云端模型往往并不适用。这些组织需要的是能够在本地运行的微调模型,而这些模型需具备审计日志记录和访问控制功能,并通过受管控的机构平台提供服务。
- 国防和情报研究:在涉密或受控环境中开展工作的 FFRDC 与国防承包商,与临床研究有着相同的数据治理需求,同时还需遵守涉密管控规定,禁止调用云端 API。因此必须采用本地模型服务、离线运行模式,并使用内置涉密领域知识的微调模型。
- 金融服务和定量研究:金融服务领域的研究团队(如量化研究、风险建模、合规分析)需处理内部专属数据,且受行业监管条款约束,禁止将敏感数据传送至外部 API。因此,他们需要基于内部研究数据训练的微调模型,这些模型通过 MaaS 在本地提供服务,并通过受管控的 API 接入现有科研工作流。
- 能源和工业研究:石油和天然气、公用事业及工业科研机构,既要运行计算密集型模拟工作负载,还需处理材料研究、预测性维护和地球物理分析等方面日益增多的机器学习管道。Slinky 尤其适合这一领域,一方面,基于 Slurm 的模拟工作流已是行业通用标准,另一方面,模拟下游业务对机器学习驱动的数据分析需求正持续增长。
在以上各类场景中,整体架构设计思路保持一致:融合 HPC 与云原生调度能力、针对特定领域定制模型、依托共享 MaaS 平台实现高效服务交付,并在机构层面统一管控访问权限。
整合落地:平台核心能力
下面将举例说明,整套架构在已完成部署的科研机构中可发挥的实际价值:
计算基因组学研究人员通过 Slurm 提交大规模变异识别作业,操作方式与其多年来提交 HPC 作业的习惯完全一致。Slinky Operator 会将该作业作为容器化工作负载在 OpenShift 上进行调度,并部署在同时为微调推理端点提供服务的同一组 GPU 节点上。任务完成后,输出结果存入共享对象存储区中,供 HPC 和 Kubernetes 环境共同访问。
某医学院的临床 NLP 研究人员需要一个针对去标识化临床记录进行微调的模型,用于执行命名实体识别任务。他们与平台团队合作,使用 NVIDIA NIM 目录中的基础模型,通过 OpenShift AI 上的训练中心运行低秩适应(LoRA)微调作业。生成的模型经过版本控制,并作为 MaaS 端点提供服务。另外两个具有类似 NLP 任务需求的研究团队可直接使用该端点,在整个机构范围内分摊模型微调的成本。
FFRDC 的网络安全研究团队需要使用 LLM 大规模分析威胁情报报告。由于数据高度敏感、禁止调用云端 API,模型全程在本地 OpenShift 集群上运行。该团队基于涉密自有数据集完成模型微调,并借助 InstructLab 合成数据技术扩充小规模标注样本。该端点仅对绑定对应 RBAC 权限的命名空间开放访问。
一位平台工程师在同一集群中管理所有工作负载,通过单一可观测信息面板,集中查看:Slurm 与 Kubernetes 工作负载的 GPU 利用率、各端点的模型服务延迟、训练作业队列积压量、各命名空间资源配额使用情况。工作负载之间的资源争用问题由统一调度程序解决,无需人工干预。
以上全部功能现已在红帽 AI 和 OpenShift AI 中提供,通过红帽和 NVIDIA AI 工厂参考架构与 NVIDIA 硬件集成,并借助 Slinky Operator 扩展到 HPC 工作流。
结语
推动下一轮科学发现的研究人员,将把 LLM 作为主要工具,深度融入日常科研工作流,而非仅当作现有研究方法的辅助补充。
他们对平台的核心诉求,是能够直接上手使用各项功能,无需专职承担基础架构运维工作。他们需要的是真正适配自身领域的微调模型、快速可靠的推理服务、无需切换集群环境即可运行的 HPC 工作流,以及依托合规管控服务实现的资源共享访问。
红帽 OpenShift、红帽 AI、NVIDIA 以及 Slinky Operator 协同组合,可共同打造该一体化平台。
关于作者

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

O'Neill Joseph is a Sr AI Solutions Architect in Red Hat focused on specialized AI deployments, has over 20 experience in IT Infrastructure, from telecommunications to cloud native infrastructure with a Degree in Cybersecurity and IT Networking from University of Maryland.

Working with customers to build IT solutions for over 25 years, Wes has experience integrating various technologies and approaches to produce outcomes and achieve mission objectives. Serving highly regulated industries such as healthcare and defense, Wes understands how to approach IT challenges with a secure, compliant end state in mind.
At Red Hat, Wes focuses on helping customers build cloud-native platforms where they can run AI/ML workloads, integrate heterogeneous data and facilitate outcomes anywhere in the world.
Prior to joining Red Hat, Wes was the CTO at a small technology company in DC helping build solutions for a variety of government customers.
Wes has managed global engineering teams, built services to help customers scale their missions, and designed software solutions to meet the needs of growing organizations.






