
为什么不能将所有的 GPU 都部署到数据中心?
传统上,集中式 IT 架构方法是应对规模扩展、管理及环境问题的首选途径,而且这种方法确实存在适用的用例:
- 容纳硬件的数据中心规模庞大、配置高端
- 几乎总是有更多空间来增设节点或硬件,并且全部都可在本地管理(有时甚至位于同一子网中)
- 电力、散热和连接都持续稳定,且具备冗余能力
为何要去修复一个完好无缺的解决方案?问题并非在于解决方案本身需要修复,而是一刀切的解决方案很少能真正全盘适用。我们以制造业的质量控制为例。
制造业的质量控制
在一间工厂或一条装配线上,可能存在数百个乃至数千个不同的区域,各条装配线上执行着特定的任务。在使用传统模式时,每个数字化步骤或实际工具不仅要完成其自身的工作任务,还需将工作结果传递给位于遥远云端的中央应用。这可能会引发一系列问题,例如:
- 速度:拍摄照片、上传到云端、由中央应用进行分析、发送响应和采取行动,整个过程需要多长时间?是选择稳健行事、收入减少,还是选择快速行动但可能引发多起错误或事故?决策制定是实时的,还是近实时的?
- 数量:每个传感器需要多少网络带宽来持续上传或下载原始数据流?这是不是可行?成本是否高得令人望而却步?
- 可靠性:网络连接中断时会发生什么?是否会导致整个工厂全面停工?
- 规模:假设业务状况良好,中央数据中心是否能够扩大规模,以处理来自所有位置上每台设备的每一条原始数据?如果可以做到,那么需要多少成本?
- 安全性:有没有任何原始数据被视为敏感数据?这些数据是否允许离开所在区域?能不能存储到任何地方?在流式传输和分析之前是否需要加密?
向边缘迁移
如果您在回答以上任一问题时举棋不定,那么边缘计算无疑是一个值得考虑的选择。简而言之,边缘计算允许将那些规模较小、对延迟敏感或具有私密性的应用功能从数据中心迁移出去,部署到更接近实际工作地点的位置。边缘计算的应用已经非常普遍,从我们驾驶的汽车到随身携带的手机,都能见到它的身影。边缘计算不仅解决了规模化带来的挑战,更是将其转化为了一种优势。
再看一看制造业的示例。如果每条装配线附近都有一个小型集群,那么上述所有问题都能得到缓解。
- 速度:在本地查看已完成任务的照片,本地硬件能以较低的延迟来运行。
- 数量:大幅减少了与外部站点连接所需的带宽,从而节省了经常性成本。
- 可靠性:即使广域网连接出现中断,本地也可以继续工作,并在重新建立连接后重新同步到中央云。
- 规模:无论是经营 2 家还是 200 家工厂,所需的资源都分布在各个位置,不必为了应对高峰时段的需求而过度扩建中央数据中心。
- 安全性:没有原始数据离开本地,减小了潜在的攻击面。
边缘 + 公共云是什么样的?
红帽 OpenShift 是领先的企业级 Kubernetes 平台,可提供灵活的环境,让应用(及基础架构)能够部署到最需要的地方。在本例中,不仅可以将它部署到中央公共云中运行,还能把那些应用从数据中心迁移出去,部署到装配线本身所在位置运行。它们可以在现场快速获取、计算和处理数据。这就是边缘机器学习(ML)。我们来看看将边缘计算与私有云和公共云相结合的三个示例。第一个示例是将边缘计算和公共云结合。

- 数据采集在现场进行,这也是收集原始数据的地方。对于负责进行测量或执行工作的传感器和物联网(IoT)设备,可以使用红帽 AMQ 流或 AMQ 代理组件来连接到本地化的边缘服务器。规模可大可小,从小型单节点到大型高可用性集群均可适用,具体取决于应用的需求。最重要的是,可以混合搭配,比如小型节点部署到偏远区域,大型集群则部署到空间充裕的地方。
- 数据准备、建模、应用开发和交付才是真正的工作重点。我们要获取和存储数据,并进行分析。以装配线为例,需要对小部件图像进行分析以寻找模式(如材料缺陷或工艺错误)。实际的机器学习就发生在这里。在获得新的洞察信息后,这些知识又重新整合到位于边缘的云原生应用中。如今,并非所有这些都是在边缘完成的。这是因为,相较于在轻量级边缘设备上运行,在密集的中央集群上运行密集型中央和图形处理单元(CPU/GPU)可以将流程缩短数日乃至数周。
- 借助红帽 OpenShift Pipelines 和 GitOps,开发人员可以利用 持续集成和持续交付(CI/CD)来不断改进应用,以尽可能加快流程速度。越快利用所获取的知识,就能越高效地将时间和资源投入到创收活动上。这促使我们再次聚焦于边缘,其中由人工智能驱动的新应用(或更新的应用),能够即时运用新知识来观察并获取数据,随后将这些数据与最新的模型进行比对分析。这一过程将不断循环往复,作为持续改进工作的一个环节。
边缘 + 私有云是什么样的?
我们来看第二个示例。整个流程保持不变,除了第 2 步改为驻留在本地的私有云中。
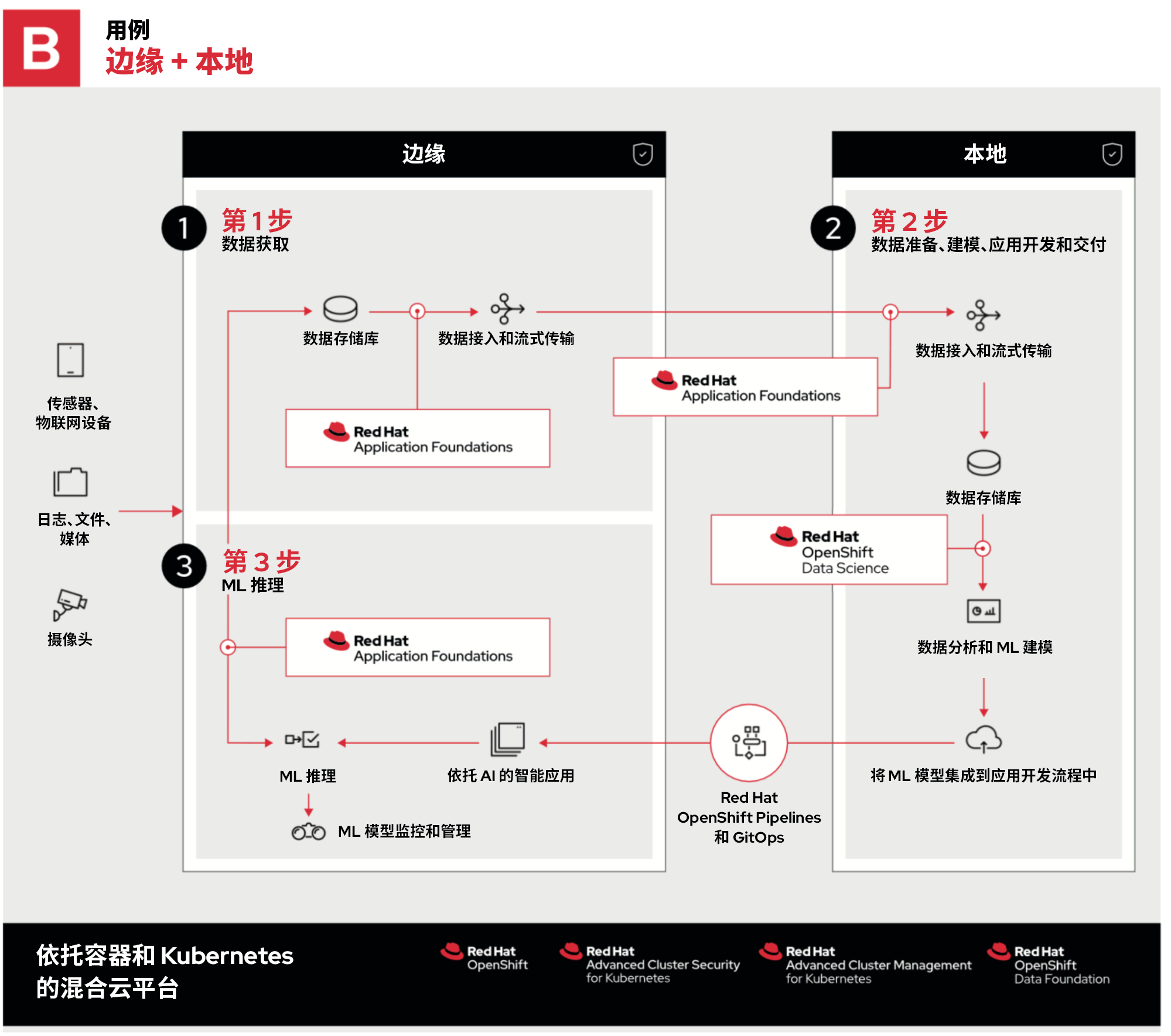
企业选择私有云的原因可能包括:
- 已经拥有相关硬件,且能使用现有的资金。
- 必须遵循有关数据区域设置和安全性的严格规定。敏感数据不可存储在公共云中,也不能通过公共云传输。
- 需要现场可编程门阵列、GPU 等定制硬件,或者需要的配置无法从公共云提供商处直接租用。
- 相较于在本地硬件上运行,特定工作负载在公共云中运行的成本更高。
以上只是 OpenShift 可带来灵活性的几个示例。它可以像在红帽 OpenStack 平台私有云上运行 OpenShift 一样简单。
边缘 + 混合云是什么样的?
最后一个示例使用了由公共云和私有云构成的混合云。
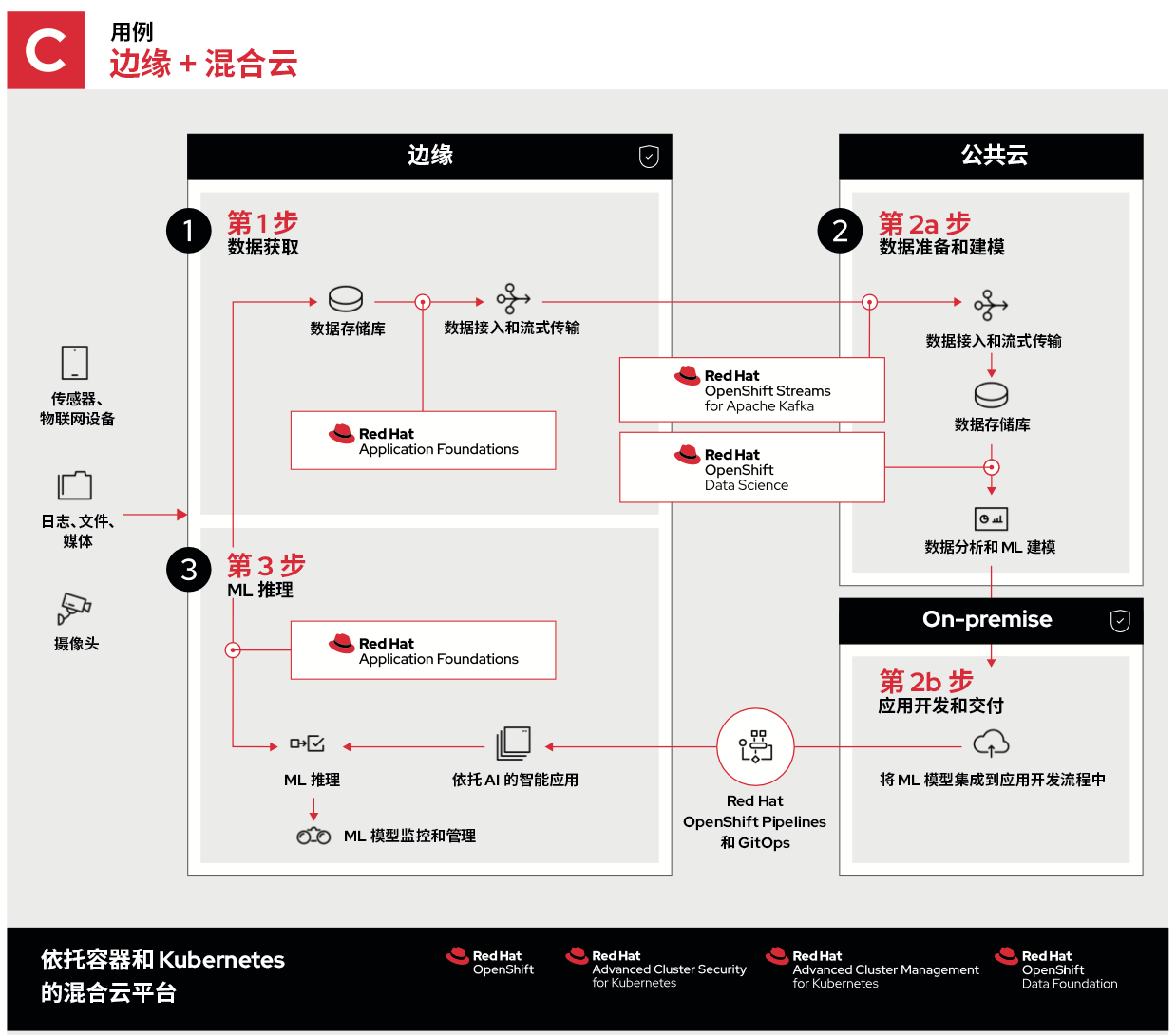
在这个示例中,第 1 步和第 3 步与之前相同,甚至第 2 步也包含同样的流程,区别在于它们被分布到了最适合的环境中运行。
- 第 2a 步主要涉及从边缘获取、存储和分析数据。这充分利用了公共云的资源规模、地理多样性和连接性来收集和解读数据。
- 第 2b 步允许进行本地应用开发,而后将更新发回到边缘,从而对特定的开发工作流进行加速、保护或自定义。
红帽能够提供什么?
鉴于有众多的变量与注意事项需要权衡,构建一个成功的边缘计算环境需要具有极高的灵活性。无论面对的是缓慢、不稳定或零网络连接的挑战,还是严格的合规性要求或极端的性能标准,红帽均能提供必要的工具,助力客户打造灵活的解决方案并进行调优,从而在最佳的位置运行最适宜的应用。
无论洞察来源位于边缘、主流公共云、本地私有云还是任意组合之中,开发人员均可使用熟悉的工具,持续推动云原生应用(在 OpenShift 上运行)的创新发展,并确保这些应用以最优方式在最佳位置上运行。
关于作者
Ben has been at Red Hat since 2019, where he has focused on edge computing with Red Hat OpenShift as well as private clouds based on Red Hat OpenStack Platform. Before this he spent a decade doing a mix of sales and product marking across telecommunications, enterprise storage and hyperconverged infrastructure.






