Kubeflow 是一个 AI/ML 平台,其中汇集了多种工具,涵盖主要的 AI/ML 用例:数据探索、数据管道、模型训练和模型服务。利用 Kubeflow,数据科学家可以通过一个门户访问这些功能,其中提供了与这些工具进行交互的简要抽象信息。这意味着数据科学家无需了解 Kubernetes 插入这些工具所使用方法的具体细节。也就是说,Kubeflow 专为在 Kubernetes 上运行而设计,并充分吸纳了许多关键概念,包括 Operator 模型。实际上,除了前面提到的门户,Kubeflow 还是一个 Operator 集合。
本文将介绍在最近的客户合作当中,为了让 Kubeflow(1.3 或更高版本)在 OpenShift 环境中顺利运行,我们采用的一系列配置。
Kubeflow 多租户注意事项
Kubeflow 针对的一个用例是能够为大量数据科学家提供服务。为此,Kubeflow 引入了一种多租户方法(自 1.3 版起全面提供),其中的每位数据科学家都会获得一个 Kubernetes 命名空间并在其中运行(另外还有机制支持在命名空间之间共享构件,但本文暂不探讨)。
了解这种多租户方法非常重要,因为在 OpenShift 上支持这一功能占据了 Kubeflow 实施工作的一大部分。相比每个应用一个命名空间(部署 OpenShift 时的一种更常见模式),每个用户一个命名空间可能需要在部署 OpenShift 时进行一些重新设计,具体取决于身份验证/授权的组织方式。
为了让 Kubeflow 多租户正常运行,用户必须通过身份验证,并且要在所有请求中添加受信任的标头(默认为 kubeflow-userid,但可以配置)。Kubeflow 将从中获取所需信息,并为用户创建命名空间(如果不存在)。
Kubeflow 多租户还具有 Profile 的概念。Profile 是一个自定义资源(CR),代表用户的环境。Profile 映射到命名空间,由 Kubeflow 管理。kubeflow-userid 标头必须与现有 Profile 匹配,Kubeflow 才能正确路由请求。
建立 Profile 并与用户关联后,Kubeflow 将创建相应命名空间,该用户的所有后续活动都将在该命名空间进行。
Kubeflow 还与 Istio 紧密集成。我们不强制通过 Kubeflow 运行 Istio,但建议这样做,因为 Kubeflow 的安全性是基于 Istio 结构建立的。使用 Istio 运行时,要为多租户提供支持,最简单的方法是确保 Kubeflow 在创建 Profile 时创建的命名空间属于服务网格,同时确保所有流量都流经同一个 ingress-gateway。

此阻塞点将成为执行用户身份验证和设置前面提到的 kubeflow-userid 标头的自然候选点。
与红帽 OpenShift 服务网格集成
OpenShift 服务网格与 Istio 的不同之处在于,OpenShift 集群可以包含多个服务网格,而对于上游 Istio,意味着其网格会扩展到整个 Kubernetes 集群。
在我们的设置中,我们决定将服务网格专门用于 AI/ML 用例。考虑到这一点,只有 Kubeflow AI/ML 命名空间属于此 AI/ML 专用服务网格。
我们还需要考虑到随时可能有数据科学家添加进来或被移除。因此,我们决定采取推荐模型,即每个用户一个 Profile/命名空间。
总之,我们必须找到满足以下要求的解决方案:
- 确保数据科学家在连接时经过身份验证,并在请求中以防篡改方式添加 kubeflow-userid 标头。
- 确保为每位数据科学家创建 Kubeflow Profile。
- 确保 Kubeflow 在创建 Profile 时创建的 Kubeflow 命名空间属于 AI/ML 服务网格。
确保对数据科学家进行身份验证
如前文所述,Kubeflow 会使用标头来代表所连接的用户。虽然系统提供了更改默认标头名称 kubeflow-userid 的选项,但有多个位置都需要修改,因此,我们认为直接留用默认标头名称更为便捷。
此标头可通过多种方式注入,下面是其中一种:

Kubeflow 会在 Istio 入口网关(默认称为 Kubeflow)上发布其面向外部的服务,利用这一点,该网关可使用 oauth proxy 强制执行身份验证,将未经身份验证的用户重定向到 OpenShift 登录流。其他很多 OpenShift 组件也会采取这种 oauth-proxy 方法,强制只有经过 OpenShift 身份验证并具有必要权限的用户才能发出请求。有关如何集成 oauth proxy,这篇博客文章还有更多说明。
入口网关中的 oauth-proxy sidecar 会创建一个名为 x-forwarded-user 的标头,其中包含已通过身份验证的用户的 userid (符合 http 最佳实践),因此我们只需在入口网关上添加一个转换规则(以 EnvoyFilter CR 形式实现),将该标头的值复制到一个名为 kubeflow-userid 的新标头中。此外,oauth-proxy sidecar 还被配置为只有拥有 Kubeflow 命名空间中容器集的 GET 权限的用户(可在此处按需自由配置权限集,用于区分 Kubeflow 用户和非 Kubeflow 用户)可以通过该网关。
此法可实现以下目标:
- 所有 Kubeflow 用户同时将成为 OpenShift 用户(注意,反之不一定成立)。我们可以利用 OCP 中配置的内容与企业身份验证系统集成。因此,此方法非常易于移植。
- 由于只能通过一种方法进入 Kubeflow 网格(通过 Kubeflow 入口网关保护),我们保证了只有经过身份验证的用户才能利用 Kubeflow 服务。
确保创建 Kubeflow Profile
Kubeflow 需要 Profile 对象(CR)才能正确注册和处理用户。创建 Profile 对象的过程称为“注册”。我们可以让新用户自行注册,但我们最终决定采用自动注册流程:即在用户第一次登录时,自动创建相应 Profile。
在 OpenShift 中,用户第一次登录就会创建 User 对象。我们可以拦截该事件,以便同时创建 Profile 对象。
若要自动创建 Profile 对象,我们可以使用命名空间配置 Operator。下图展示了用户首次登录 OpenShift 时,创建 Profile 对象的事件序列:

将 Kubeflow 命名空间添加到 AI/ML 服务网格
在我们创建 Kubeflow Profile 对象的同时,Kubeflow 会创建相应的 Kubernetes 命名空间,并向新命名空间添加多种资源,如配额、Istio RBAC 规则和服务帐户。Kubeflow 会假定命名空间属于网格,但 OpenShift 服务网格并非如此,而是每个命名空间都必须显式加入给定网格(可以有多个)。为解决这一问题,我们可以再次使用命名空间配置 Operator,这次是要创建一条规则,用于在创建命名空间时触发,让命名空间加入网格。完整的工作流包括:

正确设置此工作流后,下图展示了数据科学家在登录时会看到的内容:

红色圆圈内的名称表示确认该用户已被 Kubeflow 识别。
启用 GPU 节点和节点自动扩展
此时,数据科学家可以登录 Kubeflow 主控制面板并开始使用所提供的功能。当然,要支持多个 AI//ML 用例,还需要具备的一个功能是能够访问 GPU。
只要满足前提条件,启用 GPU 节点就非常简单。这篇博客文章详细介绍了具体过程。
然而,因为 GPU 节点属于比较昂贵的资源,我们需要满足两个要求来最大限度减少开支:
- GPU 节点仅限用于 AI/ML 相关工作负载。
- 应允许 GPU 节点在需要更多资源时自动扩展,并在不再需要这些资源时自动缩减。
将 AI/ML 工作负载与普通工作负载区分开
要将 AI/ML 工作负载与集群中可能存在但不需要 GPU 节点的其他工作负载区分开,可以使用污点和容忍度。我们只需创建具有污点的 GPU 节点,以默认阻止工作负载登陆这些节点。
为避免非 AI/ML 租户将工作负载标记为容忍污点,可以使用以下命名空间注释:
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
为简化数据科学家的工作,并自动为在 AI/ML 命名空间中运行的工作负载添加容忍度,可对所有 Kubeflow 命名空间应用以下注释:
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'在本例中,已启用 GPU 的节点标有“workload: ai-ml”。
请注意,这些是 alpha 注释,目前不受红帽支持,但根据我们的测试,这些注释可以正常运行。
我们前面已经讨论过,Kubeflow 将在数据科学家首次登录时创建数据科学家命名空间。由于我们无法控制命名空间的创建方式,因此必须实施一个流程,以便为命名空间应用合适的注释。此操作可通过 mutation webhook 配置来实现。本电子书可以拦截命名空间的创建,并添加所需注释。我们使用了开放策略代理(OPA)和 Gatekeeper 项目,该项目将 OPA 与 Kubernetes 集成,是我们通过 Gatekeeper Operator 部署的。

启用节点自动缩放
为最大限度减少使用昂贵的 GPU 节点,我们需要对 AI/ML 节点启用自动缩放功能。
节点自动缩放是 OpenShift 的一项开箱即用功能,可按照官方文档中的步骤启用。
使用节点自动缩放功能时,我们发现以下情况显然有待改进:
首先,节点自动缩放器只会在 pod 停留在“待处理”状态时添加节点。这种被动行为会导致用户体验非常糟糕,因为用户在尝试启动工作负载时需要等待节点创建好(在 AWS 上约为 5 分钟),还要等待 GPU 驱动程序可用(额外再等 3-4 分钟)。为缓解这种情况,我们使用了 active-node-scaling-operator(详细说明参见这篇博客)。
其次,在使用 GPU 节点时,自动缩放器创建的节点数往往超过所需。原因是新创建的节点无法立即调度待处理的 pod,因为这些节点最初没有启用 GPU(在 GPU operator 执行初始化步骤时,如编译和注入 GPU 内核驱动程序时)。要解决此问题,必须按照此处说明,向节点模板添加特定标签(cluster-api/accelerator: "true")。此标签将告知节点自动缩放器:给定节点要启用某些功能(如支持 GPU),即使这些功能当前还不存在。
允许访问数据湖
对于数据科学家需要执行的几乎所有任务,无论是探索数据以了解数据结构及其可能的内部关联,还是通过样本数据集训练神经网络模型,抑或是检索模型以便为其提供服务,访问数据都是关键所在。在 AI/ML 中,含有各类(关系、键值、文档、树等)数据的数据存储库被称为数据湖。
对数据湖实施访问保护可能是一项挑战,尤其是在多租户环境中。此外,我们希望最大限度减少数据科学家需要了解的 Kubernetes 和凭据管理概念,以减轻他们的工作压力。
在我们的案例中,数据湖由一组 AWS S3 存储桶组成。备用存储库类型可以利用许多相同的概念。
安全团队还要求,访问数据湖所需的凭据应对应工作负载,而非特定个人。此外,凭据应设置较短有效期。此举旨在避免将可能丢失或滥用的静态凭据分发给数据科学家。
为解决此问题,我们使用了绑定服务帐户令牌和 OpenShift - STS 集成,将后者重新用于用户工作负载。我们来看看如何将这两种技术结合到一起。
有了绑定的服务帐户令牌,就可以让 OpenShift 生成一个 JWT 令牌,该令牌对应工作负载,并作为投射卷挂载,这与服务帐户令牌对其他工作负载的处理类似。与服务帐户令牌不同,此令牌有效期很短(Kubelet 负责刷新),可通过定义其受众属性进行自定义。
STS 是 AWS 的一项服务(其他云提供商也有类似服务),方便我们在 AWS 与其他身份验证系统(包括 OIDC 身份验证提供商)之间建立信任关系。通过配置 STS,我们可以指示 AWS 信任由 OpenShift 生成的 JWT 令牌,并将这些令牌与具有特定权限集的 AWS 令牌进行交换。完成交换后,pod 中运行的应用便可开始使用 AWS 资源。下图展示了这种架构:

这种方法的一个要求是,用于运行 AI/ML 容器集的服务帐户具有附加的特定注释,表明这些工作负载需要额外的绑定服务帐户令牌。为此,我们可以使用 OPA 并在数据科学家命名空间中的服务帐户上注入所需注释。
完成上述设置后,数据科学家以及一般的 AI/ML 工作负载便可使用凭据访问数据湖,这些凭据对应工作负载(而非特定个人)并且有效期很短(因此不需要在任何地方持久保留)。此外,所有这些情况对数据科学家来说都是公开透明的,他们只需要使用(能够理解 STS 身份验证方法的)标准 AWS 客户端即可访问数据湖。
与无服务器集成
在 Kubeflow 中,默认通过 Kfserving 为模型提供服务(也支持其他方法,本文另有说明)。
Kfserving 基于 Knative 实现,是 OpenShift 中的一项功能,可通过安装 OpenShift Serverless 来启用。
使用红帽 OpenShift 服务网格和无服务器时必须谨慎,因为必须满足一些前提条件才能对其正确集成。
具体而言,必须在每个服务网格命名空间创建 NetworkPolicy 规则,以允许从无服务器命名空间到网格命名空间的流量。
此外,由于多租户 Kubeflow 生态系统中的所有网格服务都受到 Istio AuthorizationPolicies 的保护,而且无服务器组件位于网格外部,因此我们需要修改 RBAC 策略,以允许来自无服务器命名空间 pod(特别是 Kourier 和 Activator)的连接:
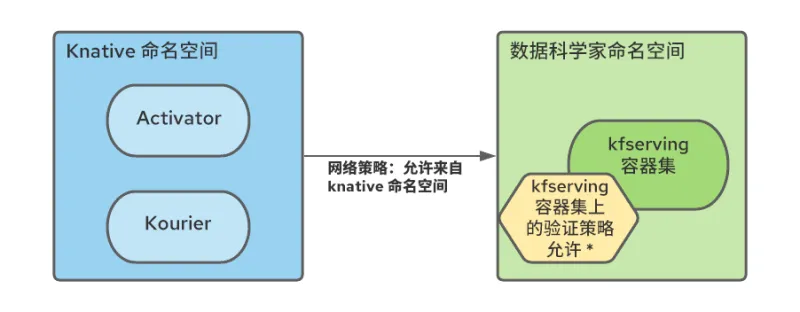
我们使用命名空间配置 Operator 自动创建了这些规则,指示其在数据科学家命名空间创建之时添加 NetworkPolicy 和 AuthorizationPolicy 资源。
安装
此存储库提供了上述每个主题的分步安装说明及相关配置。本指南还包含其他一些小的增强功能和几个 AI/ML 工作负载示例,以验证设置。
结论
本文讲述了在 OpenShift 上设置 Kubeflow 多租户部署时的几个注意事项。这只是 AI/ML 旅程的第一步,但足以入门。随后,数据科学家团队便可开始使用 Jupyter notebooks 探索数据,并创建数据管道,其中可能包括训练神经网络模型。神经网络模型准备就绪后,Kubeflow 还可帮助处理模型服务用例。
特别提醒:红帽目前不支持在 OpenShift 上运行 Kubeflow。此外,Kubeflow 是一款功能丰富的产品,此次部署为初次部署,我们尚未验证是否所有功能都能正常运行(关于已测试功能的列表,参见存储库)。例如,Kubeflow 提供的整个可观测性堆栈是一项重要功能,但遗憾的是目前尚未实施,不过日后可能会集成进来。
我们希望这类工作能够帮助想要在 OpenShift 上运行 Kubeflow 的企业顺利起步。此外,应为这些概念提供许多通用原语,以便在实施其他 AI/ML 平台时使用。
关于作者

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).






