
您的私有云是否像是一场“随意取用的自助餐”?您深知它带来了业务价值,但在账单到期结算时,却无从厘清各部门的具体资源消耗情况。
在当今瞬息万变的云环境中,能够将成本合理归因于内部用户变得愈发重要,尤其是对于运行自有云基础架构的企业而言。您需要建立责任归属机制,以便在各部门之间公平分摊成本,或鼓励团队合理调整工作负载规模;而实现这一目标的第一步,便是提升资源的可见性。
在 OpenShift 18 上的红帽 OpenStack 服务的功能版本 5(FR5)中,我们推出了一项解决该难题的关键功能:根据租户的实测使用量进行计费。
本次在 FR5 中正式发布的 OpenStack 原生计费服务 CloudKitty,打通了原始技术指标与财务运营之间的数据壁垒。
为什么 CloudKitty 至关重要?
CloudKitty 充当着一个数据转换层,将有关服务器使用情况的数据转化为指导部门预算的决策依据。它也好比一个抄表员,负责衔接收集的指标与 FinOps 或计费解决方案。它会收集虚拟机(VM)运行时长或存储空间消耗量等原始技术数据,并根据您设定的计费规则来生成报告。这有助于您实现两大目标:
- 透明的成本回收:您现在可以清晰查看每个租户的资源使用明细。这样一来,您就能精准收回运维成本,同时避免因不透明的收费而让内部客户感到困惑。
- 信任与优化:租户可以按项目、规格和指标查看自身的资源消耗情况,以及对应的成本,从而据此做出明智的决策,例如存档过时数据或优化虚拟机的使用。
需要注意的是,CloudKitty 仅作为成本可见性与计费引擎运行。如果租户的成本超过特定的阈值,它不会主动执行预算限制,也不会阻止创建资源(如 Nova 实例)。
CloudKitty 的工作原理是什么?
CloudKitty 虽非一套完整的计费解决方案,但它在使用量与成本之间架起了关键的桥梁。整个工作流非常简单:
设置计费规则 → 收集指标 → 生成计费报告
设置规则
我们以虚构名单中的租户“数据部”为例。一直以来,该部门需要启动大量虚拟机来执行分析工作负载,而且即便在计算任务完成后,这些虚拟机仍会长时间处于运行状态。
要实现透明的成本回收,我们需要跟踪其计算资源占用情况。为此,我们将跟踪 ceilometer_cpu 指标。这一特定指标支持按规格统计正常运行时间,这意味着对于虚拟机实例的每个运行时段,CloudKitty 都能根据其规格大小计算出不同的费率。
第 1 步:创建服务
首先,我们需要为指标创建一个顶层容器。服务名称必须与指标名称或 metrics.yaml 中定义的 alt_name 完全匹配。(我们稍后将更详细地讨论该文件。)
openstack rating hashmap service create ceilometer_cpu
+----------+--------------------------------------+
| Name | Service ID |
+----------+--------------------------------------+
| ceilometer_cpu | <uuid> |
+----------+--------------------------------------+保存该服务 ID(UUID),后续命令中将用到它!
通过创建 ceilometer_cpu 服务,我们可以确保从收集器传入的每个 CPU 数据点都将直接路由到这条新的计费规则。
第 2 步:创建分组(可选)
我们不希望数据部的计算费用与其存储或网络账单混为一谈。分组可以帮助我们组织相关的映射规则,并将各项计算隔离开来。
openstack rating hashmap group create cpu_rating通过对这些映射规则进行分组,我们可以区分不同的计费场景。如果同一组中的多个映射规则恰好都匹配,CloudKitty 将仅按费率最高的规则计费。
第 3 步:创建映射
映射就是成本规则。首先,让我们为数据部设定一个基线,即按每个项目收取固定费用。将 <service_id> 和 <group_id> 替换为前面步骤中返回的 UUID,即可将这条新规则直接关联到 ceilometer_cpu 服务 and cpu_rating 分组。
openstack rating hashmap mapping create 0.02 \
-s <service_id> \
-g <group_id> \
-t flat在此场景中,0.02 表示每个收集周期(默认为每小时)收取 0.02 个单位。每个 CPU 实例无论使用量多少,均按 0.02 单位收取固定费用。
第 4 步:基于字段的计费(秘密武器)
数据部同时运行着微型 Web 服务器和大量资源密集型数据库节点。对所有资源都采用固定费率收费显然不公平。我们希望根据用户使用的具体虚拟机规格,分别收取不同的费用。
首先,我们创建一个引用元数据键的字段:
openstack rating hashmap field create <service_id> flavor_id然后,为该规格值创建一个特定映射:
openstack rating hashmap mapping create 0.05 \
--field-id <field_id> \
--value <flavor_uuid> \
-t flat我们需要针对环境中存在的每种规格重复这一映射创建过程。通过为每种规格创建一条新规则,计费服务便能根据当前运行的虚拟机大小,按相应费率进行计费。
结果:如何协同工作
到了月底,数据部要求查看其使用情况时,CloudKitty 会按以下方式处理我们构建的上述规则:
ceilometer_cpu (metric)
└─> Service: ceilometer_cpu
└─> Field: flavor_id (optional)
└─> Mapping: m1.tiny = 0.01, m1.large = 0.05
└─> Mapping (direct):0.02 flat凡可衡量,皆可计费
前文以数据部的 CPU 使用量(ceilometer_cpu)作为主要示例,但计算只是整个体系的一部分。CloudKitty 在 OpenShift 上的红帽 OpenStack 服务中发挥的真正优势在于,与 Prometheus 实现集成。
请记住,任何已收集的指标都可用于计费。这意味着您可以按照上述完全相同的步骤,轻松为租户的其余资源占用创建计费规则。例如,您可以为以下各项构建成本映射:
- 块存储:使用
ceilometer_disk_device_capacity跟踪存储容量(GB/月) - 网络:使用
ceilometer_ip_floating对分配的公网地址进行收费 - 出站带宽:使用
ceilometer_network_outgoing_bytes对虚拟机的总出站流量进行计费
CloudKitty 从 Prometheus 获取这一作用域的数据后,处理器便会应用您自定义的计费规则,并将最终确定的计费指标直接推送到存储后端。它充当者连接原始技术遥测数据与 FinOps 报告的终极自动化桥梁。
生成计费报告:揭晓时刻
创建规则并从 Prometheus 收集指标后,最后一步是提取计费数据。
需要注意的是,CloudKitty 并非开票系统。它不会试图生成精美的 PDF 账单,而是充当着一个强大的数据引擎,通过其 REST API 或 OpenStack 客户端提供干净、可解析的 JSON 数据。这样一来,您便可以更轻松地将计费数据直接引入企业现有的 FinOps、成本分摊或计费中间件。
租户视角:数据部查看账单
CloudKitty 内置租户感知访问控制功能。当数据部想要查看当前使用情况时,他们只能访问自己项目的资源占用。任何试图查看其他租户数据的请求,都会被 API 自动阻止或忽略。
要获取月度汇总,数据部可以使用 OpenStack 客户端:
# Get summary for a specific month
openstack rating summary get --begin 2026-02-01 --end 2026-03-01管理员视角:全局概览
数据部只能查看自己的使用情况,而云管理员需要全面了解整个环境,以进行容量管理并促进全局成本分摊。
使用管理员令牌,运维人员便可获得全面可见性。他们可以在命令的基础上,使用 --tenant-id <project_uuid> 参数来筛选特定租户的数据。
openstack rating summary get \
--begin 2026-02-01 \
--end 2026-03-01 \
--tenant-id <project_uuid>或者,如果 FinOps 团队需要将完整数据导出到计费系统,管理员可以使用 --all-tenants 标志,一次性提取整个云的计费数据。
直接连接到您的 FinOps 解决方案
如果您的 FinOps 中间件以编程方式拉取这些数据,它可以使用 REST API 来请求按我们之前配置的特定服务类型(如 ceilometer_cpu)分组的详尽明细:
curl -X GET \
-H "X-Auth-Token: $TENANT_TOKEN" \
"http://localhost:8888/v1/report/summary?begin=2026-02-01T00:00:00&end=2026-03-01T00:00:00&groupby=res_type"生成的 JSON 输出清楚地列出了资源类型、时间段以及总计费单位
{
"summary": [
{
"tenant_id":"MoD-project-uuid",
"res_type": "ceilometer_cpu",
"begin":"2026-02-01T00:00:00",
"end":"2026-03-01T00:00:00",
"rate":125.50
}
]
}通过将这些结构化、经聚合的 JSON 数据直接汇集到企业更广泛的财务软件中,您便成功实现了原始基础架构消耗与成本责任归属之间的闭环管理。
底层架构探秘
我们已经从运维人员视角了解了 CloudKitty 的实际应用,接下来让我们深入底层,一探其内部架构。了解架构将有助于您分析可扩展性、排查问题,并理解某些设计决策背后的原因。
架构概述
CloudKitty 作为两个独立的进程运行,各自承担不同的职责:
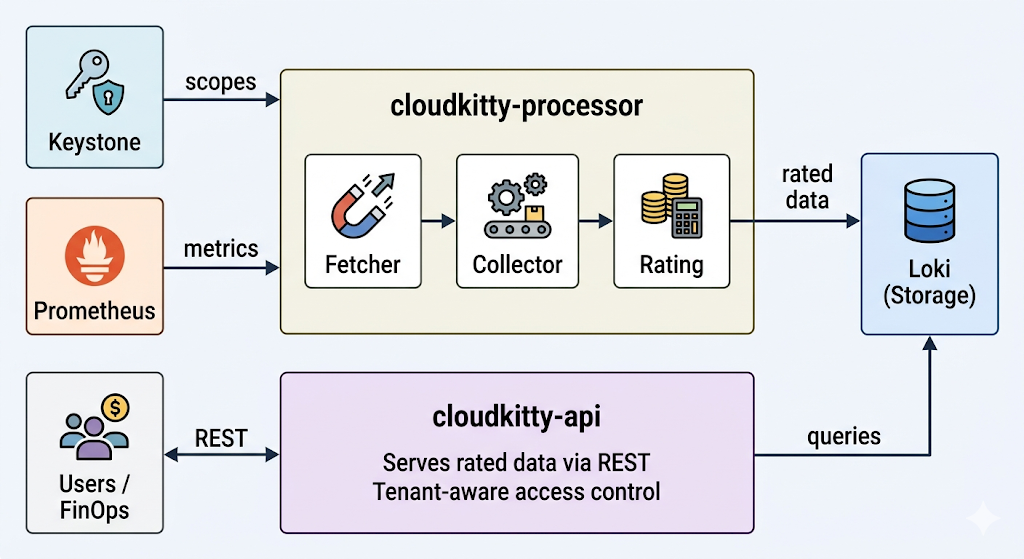
图 1. CloudKitty 架构。cloudkitty-processor 从 Keystone 获取作用域,从 Prometheus 获取指标,针对数据进行计费,然后将其存储在 Loki 中。cloudkitty-api 通过 REST,将 Loki 的计费数据提供给用户和 FinOps 工具。
cloudkitty-processor 为计费引擎。在每个收集周期(默认为 1 小时),该引擎会执行一个四阶段管道:
- 获取:向 Keystone 查询需要计费的 OpenStack 项目(作用域)列表。
- 收集:对于每个作用域,向 Prometheus 查询
metrics.yaml中定义的原始指标值。 - 计费:应用哈希映射规则(我们之前配置的服务、字段和映射),将原始使用量转换为计费数据。
- 存储:将生成的计费数据帧推送到 Loki 以实现持久性存储。
cloudkitty-api 为 REST 前端。它处理来自租户、管理员和外部 FinOps 工具的所有传入查询。当用户请求计费汇总信息时,它会查询 Loki 并返回结果。此进程是无状态的,可以横向扩展以处理更多并发请求。
由于这两个进程相互解耦,您可以对它们进行独立扩展:添加更多 API 副本以处理查询负载,或调整处理器的并行机制以同时处理更多作用域。
为什么选择 Loki?
使用 Grafana Loki 作为计费数据的存储后端似乎并非常规选择,毕竟 Loki 主要以日志聚合系统著称,但实际上它非常契合这一场景:
- 时间序列原生:计费数据本质上具有时间属性:每个收集周期内每个作用域的成本。Loki 专为对结构化流进行高效的时间范围查询而构建。
- 已集成于堆栈:OpenShift 上的 OpenStack 服务部署已包含用于日志管理的 LokiStack。CloudKitty 重复使用由运维人员管理的相同基础架构,因此无需部署或维护额外的数据库。
- 基于对象存储:Loki 会将数据持久存储到与 S3 兼容的对象存储中,从而保持较小的运维占用空间,无需管理额外的 PVC 或数据库集群。
- 结构化元数据:未来,CloudKitty 将直接在每个日志条目上存储索引元数据(租户、指标类型、规格)。这将实现快速过滤查询,而无需完整的 JSON 解析,从而大规模提高查询性能。
指标配置
收集阶段的核心是 metrics.yaml。该文件会告知 CloudKitty 要收集哪些 Prometheus 指标以及如何处理。以下是随附配置中的一个典型片段:
metrics:
ceilometer_cpu:
unit: instance
alt_name: instance
groupby:
- resource
- user
- project
- flavor_name
- flavor_id
mutate: NUMBOOL
extra_args:
aggregation_method: max
ceilometer_image_size:
unit: MiB
factor: 1/1048576
groupby:
- resource
- project
metadata:
- container_format
- disk_format
extra_args:
aggregation_method: max每个条目控制 CloudKitty 如何收集和解读特定的 Prometheus 指标:
unit:计费报告中显示的计费单位(如实例、GiB、B、ip)。alt_name:指标的替代名称。在创建哈希映射服务时,您可以使用 Prometheus 指标名称(ceilometer_cpu)或alt_name(instance)。groupby:用于分解指标的 Prometheus 标签。对于 ceilometer_cpu,按 flavor_name 和 flavor_id 分组正是我们之前配置的基于规格的计费规则得以实现的关键。mutate:应用于原始值的转换。 NUMBOOL 会将任何非零值转换为 1,非常适合“该资源是否处于活动状态?”这类语义,我们并不关心原始的 CPU 计数器,只关心实例是否正在运行。factor:用于单位转换的换算系数。例如,ceilometer_image_size使用 1/1048576 将原始字节转换为 MiB。metadata:附加 Prometheus 标签,传递到计费数据中用于信息参考(例如,用于镜像的container_format和disk_format)。extra_args:特定于后端的参数。aggregation_method: max告知 Prometheus 收集器在每个收集周期内使用最大值。
由于 CloudKitty 的收集器直接与 Prometheus 通信,针对任何可用指标进行计费都很简单:使用适当的标签和单位向 metrics.yaml 添加新条目,CloudKitty 将会在下一个处理周期开始收集和计费。
检查原始数据
虽然命令 openstack rating summary get 可以提供汇总总计,但有时您需要更深入地了解。无论您是要验证计费规则是否得到正确应用、调试缺失的指标,还是试图了解 CloudKitty 存储的内容,您都可以使用 openstack rating dataframes get 命令来检查 Loki 中的各个计费数据点。
可将汇总信息视为月度对账单,而将数据帧视为收据上的各个行项目。
检索特定时间窗口内的原始计费数据帧:
openstack rating dataframes get --begin 2026-03-01T00:00:00Z --end 2026-03-01T01:00:00Z输出中的每一行代表一个收集周期的单个计费数据点:
| 开始时间 | 结束时间 | 指标类型 | 单位 | 数量 | 价格 | 分组依据 | 元数据 |
|---|---|---|---|---|---|---|---|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.05 |
flavor_id=<uuid>, flavor_name=m1.large, project=<project_uuid>, resource=<vm_uuid> |
|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.01 |
flavor_id=<uuid>, flavor_name=m1.tiny, project=<project_uuid>, resource=<vm_uuid> |
我们来拆解一下每一列的含义:
- 开始/结束时间:该数据点所涵盖的收集周期。默认情况下,CloudKitty 每小时收集一次,因此您将看到一小时的窗口。
- 指标类型:来自
metrics.yaml的指标名称(例如ceilometer_cpu、ceilometer_ip_floating)。 - 单位:计费单位,如
metrics.yaml中所定义。 - 数量:经过 mutate 或 factor 转换后的原始用量。对于包含
NUMBOOL的ceilometer_cpu,只要实例处于运行状态,该值即为 1。 - 价格:应用哈希映射规则后的计费值。您可以通过该值验证是否应用了正确的映射。如果您将
m1.large设置为 0.05,那么此处就应该显示 0.05。 - 分组依据:来自
metrics.yaml中groupby字段的标签值。这是 CloudKitty 对数据进行分类汇总的方式,也是让您能够深入查看特定资源、规格或项目详情的关键。 - 元数据:通过
metrics.yaml中的元数据字段传递的任何其他标签。
这为运维人员提供了一个具体的工具来跟踪从原始指标到最终价格的完整路径,使 CloudKitty 的行为在每一步都透明且可调试。
准备好计算成本了吗?
无论您的目标是向内部部门进行严格的成本回收,还是提供对资源消耗的透明可见性,CloudKitty 都能为您提供实现目标所需的结构化、可靠数据。它可以打破原始 OpenStack 遥测数据与企业 FinOps 中间件之间的数据壁垒。
私有云资源随意取用、不计成本的使用模式已成过去。我们很高兴能在功能版本 5 中,将这一高度可自定义的原生功能引入 OpenShift 上的 OpenStack 服务生态系统中。告别成本估算,开启精准计费。
开始使用
浏览官方文档,在您的环境中配置和管理 CloudKitty:
观看实操演示
观看视频演示,了解管理员如何轻松配置基于规格的计费规则并提取首份月度明细。
本视频是两段独立终端会话的精选剪辑。如果您想以交互方式更详细地了解底层使用的原始命令,可以在此处浏览完整、未经剪辑的 Asciinema 录像:
- https://asciinema.org/a/ofDLdVKxHfMAsaNM:部署 CloudKitty 并创建基于规格的计费规则。
- https://asciinema.org/a/P11NR7CEqfiewF4R:验证计费数据帧并提取月度汇总信息。
关于作者
Juan Larriba is a software engineer specializing in cloud infrastructure and OpenStack observability. He is a contributor to the OpenStack Kubernetes Operators ecosystem, where he works on the Telemetry Operator — a project that brings together metrics collection, alarming, and rating services like CloudKitty into cloud-native Kubernetes deployments. His work focuses on bridging traditional OpenStack telemetry components with modern container-native architectures, helping operators gain visibility and cost insight into their cloud workloads. Juan is passionate about open source collaboration and has contributed to projects spanning Ceilometer, Aodh, and CloudKitty, with a focus on making rating and chargeback capabilities more accessible in production OpenStack environments.






