
This article is the second in a six-part series (see our previous blog), where we present various usage models for confidential computing, a set of technologies designed to protect data in use—for example using memory encryption—and the requirements to get the expected security and trust benefits from the technology.
In this second article, we will focus on attestation, as a method to prove specific properties of the system and components being used.
The need for attestation
In a confidential computing environment, another form of proof called attestation becomes increasingly important. Generally speaking, attestation is designed to prove a property of a system to a third party.
In the case of confidential computing, this generally means a proof that the execution environment can be trusted before starting to execute code or before delivering any secret information.
At the highest level, one very general definition of attestation is described by the Internet Engineering Task Force (IETF) Remote Attestation Procedures (RATS) architecture using the diagram below:
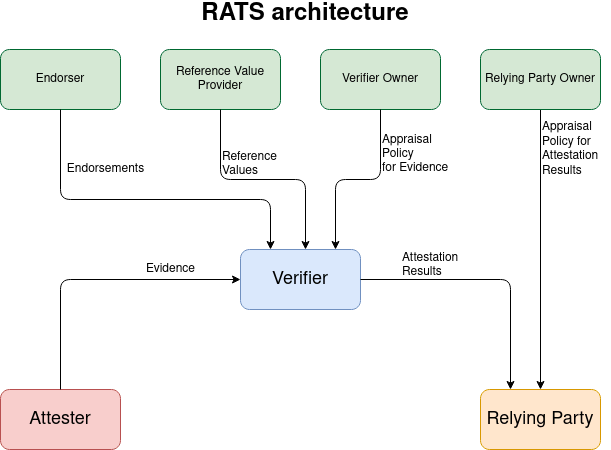
We will use the terminology from this diagram. The benefit of this model for the attestation process is that it clearly delineates the responsibilities of each component.
Remote attestation
Remote attestation decouples the generation of evidence from its verification, allowing, for example, an attestation server (AS) to dynamically respond to situations such as the discovery of new vulnerabilities and start rejecting a previously-accepted configuration. A physical chip like a Trusted Platform Module (TPM) can only do very limited policy enforcement. Using a remote server allows for a much richer policy verification, as well as near real-time updates for new vulnerabilities.
You may have heard about remote attestation outside of confidential computing through projects such as Keylime, which provides remote boot attestation for TPM-based systems. An important difference is that in its current typical usage model, Keylime focuses on proving compliance after the fact (non-blocking attestation), whereas in the case of confidential computing, attestation will typically have to pass before anything confidential is entrusted to the platform.
Two distinct attestation models can be used, known as the passport model and the background check model:
- The passport model is where the attester pre-validates an identification token with the verifier, that it can then present to the relying party. The real-life equivalent is presenting your passport.
- The background check model is where the relying party will ask for a verification when the attester presents its evidence. A real-life equivalent would be the verification of biometric measurements.
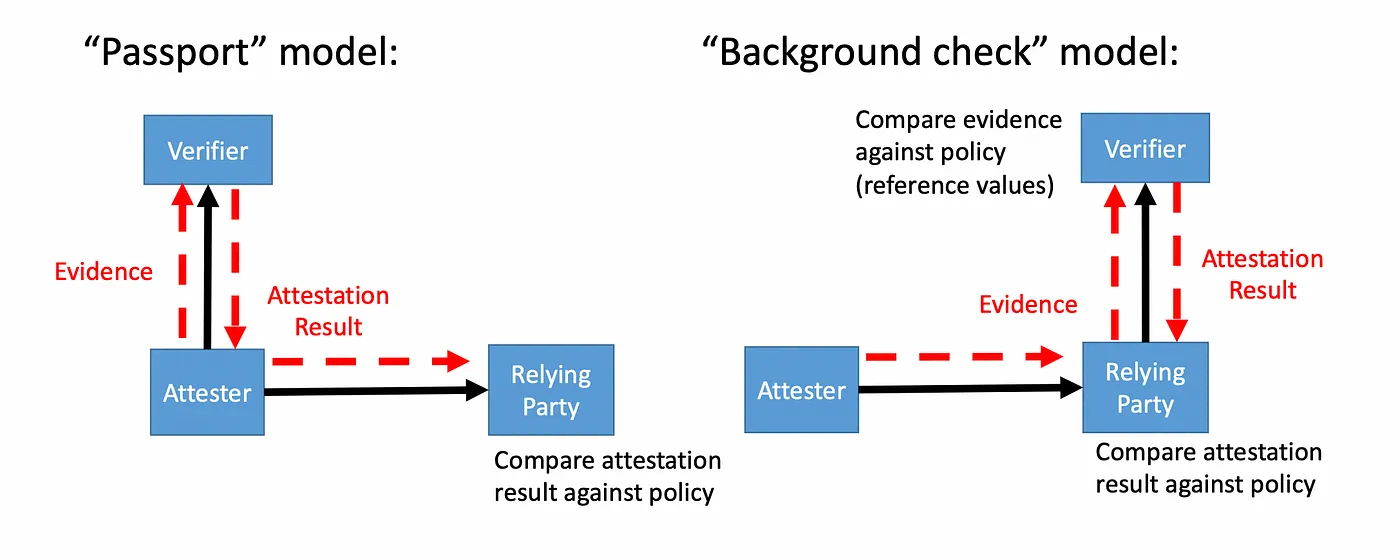
The cryptographic verification provided by confidential computing technologies generally lends itself more to a background check model than to a passport model. This is generally more useful, notably because it makes it possible to revoke access at any time. Unless stated otherwise, we will generally mean a background check when we talk about remote attestation in this post.
Components for remote attestation
Typically, remote attestation in confidential computing will involve a variety of recurring components:
- An attestation server (AS) that will submit the virtual machine to a cryptographic challenge to validate the measurement presented as evidence. It will act as a verifier on behalf of the relying party.
- An attestation client (AC) that lets the attester send evidence to an attestation server.
- A key broker service (KBS) will store secrets such as disk encryption keys, and release them only when verification is successful. This KBS can be part of a larger key management system (KMS).
- A key broker client (KBC) will receive the keys from the KBS on behalf of the attester.
Note that the key brokering part is, conceptually, distinct from attestation itself, as evidenced by products that focus primarily on attestation like Keylime, without necessarily providing key brokering services. However, in the case of confidential computing, the attestation service is typically not intended for humans to check compliance of their inventory, but becomes an integral part of the confidentiality guarantee, typically through the delivery of secrets.
Attestation flow
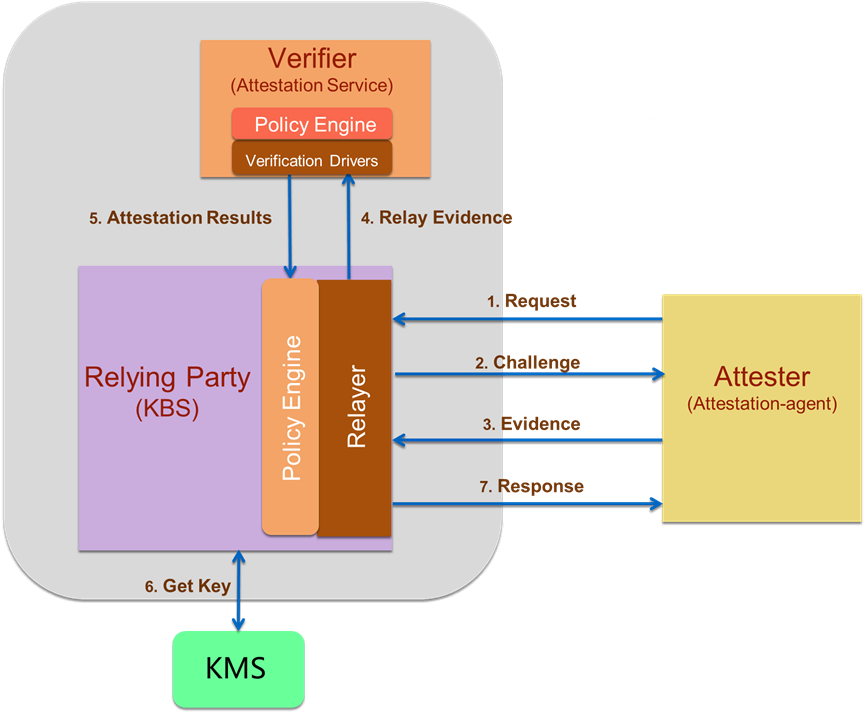
The diagram below shows an example of attestation flow for confidential computing:
- [Step 1] A request is sent to the attestation server by the attester.
- [Step 2] The server responds with a challenge, which typically includes a nonce to avoid replay attacks.
- [Step 3] The attester submits its evidence, which combines elements of the challenge with attester-provided data, in such a way that the result cannot be reproduced by a third party, nor be of use by anyone but the originator of the challenge, to block man-in-the-middle attacks.
- [Steps 4-5] The attestation server includes a verifier that applies various policies. This could include constraints about what kind of evidence is accepted, expiration dates or revocation lists.
- [Step 6] If attestation is successful, the key broker service is instructed to release the keys for that specific attester.
- [Step 7] The keys are packaged in a response that the KBC in the attester can consume.
Recipients of the proof
There is another useful way to categorize various forms of attestation, based on the intended recipient of the proof:
- User-facing: an individual using the system wants proof that the system is trustworthy.
- Workload-facing: a workload running on the system wants to ensure that it runs on a trusted execution environment (TEE).
- Peer-facing: a workload wants to ensure that a peer workload is itself trustworthy and running on a trustworthy platform.
- System-facing: system software (including firmware, bootloader or operating system) wants to guarantee its own integrity and the integrity of its execution environment.
- Cluster-facing: nodes in a cluster want to ensure that the integrity of the whole cluster is not compromised, notably to preclude non-confidential nodes from joining.
Not all of these categories of attestation are useful in all use cases, and this list is by no means exhaustive. One could attest software, hardware, configurations and more.
Securely recording the measurements: the need for hashing
The physical Root of Trust doesn’t usually contain enough storage for all the measurements. This is certainly true for today’s TPMs. So we have to resort to a hashing trick: the device usually only stores cryptographic hashes that can be used to verify the actual record in ordinary memory.
Each measurement is an ordered set of log entries consisting of a hash (the machine measurement) and a human readable description. In the case of TPMs, the log hashes are recorded in a Platform Configuration Register (PCR) whose value begins at zero and is “extended” by each measurement. Extended means that the new value is the hash of the old value and the new measurement.
Since hash functions are not reversible, it is impossible to construct a different sequence of measurement extensions that will result in the same PCR value at the top. This property means that the single PCR hash value can be used to verify the entire sequence of measurements is correct and has not been tampered with. Given a correct log, anyone can verify the PCR value by replaying all the recorded measurements through the hash extension function and verifying they come up with the same value. Note that this means the log must be replayed in exactly the same order.
In order to attest to the entire log, the root of trust usually signs the single PCR hash value. Since the only thing that can be done to a PCR is extend it, there’s no real need for security around who can do the extension: the object for most attackers is to penetrate the system undetected, and a bogus extension would lead to a log verification failure and immediate detection. This can actually be used as a feature, where a later stage can extend an earlier measurement, deliberately altering it, for example to grant access to different secrets as execution progresses.
When verifying the state of the system, it is tempting to see the single PCR value as the correct indicator of state (which it is). However, all system components (and configurations) change quite often over time which can cause a combinatorial explosion in the number of possible PCR values representing acceptable system state, so sensible verifier solutions usually insist on consuming the log so they can see the state of each individual component rather than relying on the single PCR value to represent it. In other words, the PCR only attests the validity of a configuration, but may not be the best way to access it, the TPM event log being a more extensive record of what happened.
Identity and privacy concerns
In order to sign the measurements, each TPM has to be provisioned with a unique private key, which must be trusted by the party relying on the signature. Unfortunately, this unique key also serves to uniquely identify the system being measured and has led to accusations of the TPM and Trusted Computing generally being more about social control than security.
To allay these fears, the Trusted Computing Group (guardians of the TPM specification) went to considerable lengths to build privacy safeguards into the TPM attestation mechanisms. Nowadays, of course, most attestations are done by people who know where the system being measured is and what it’s supposed to be running. Under these circumstances, all of the privacy protections now serve only to complicate the attestation mechanism. If you’ve ever wondered why it’s so complicated to get the TPM to give you a quote, this is the reason. However, while it’s a practical concern if you actually write libraries talking to a TPM, we will not concern ourselves with identity and privacy in this blog article.
Conclusion
In this second article, we covered the basic ideas about attestation, and how it can be useful for confidential computing in general. In the next article, we will enumerate the most important use cases for confidential computing, and see how they differ in their use of the same underlying technology, as well as how this impacts the implementation of attestation.
Sobre los autores
Más como éste
Las amenazas de la inteligencia artificial se mueven rápido. Tus defensas también deberían hacerlo.
Más allá de la automatización: Motivos por los que el aumento de las vulnerabilidades de seguridad basadas en la inteligencia artificial exige una defensa técnica humana
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube