La capacidad de prestar servicios a los clientes de forma permanente y con interrupciones mínimas o nulas es fundamental en la actualidad. El complemento de alta disponibilidad de Red Hat Enterprise Linux (RHEL) puede ayudarlo a alcanzar ese objetivo al mejorar la confiabilidad, la capacidad de ajuste y la disponibilidad de los sistemas de producción. Los clústeres de alta disponibilidad lo logran eliminando los puntos únicos de falla y utilizando la tolerancia a fallos, es decir, trasladando los servicios de un nodo del clúster a otro cuando uno deja de funcionar.
En esta publicación, se demostrará el uso de la función del sistema ha_cluster de RHEL en la configuración de un clúster de alta disponibilidad que ejecuta un servidor HTTP Apache con almacenamiento compartido en modo activo/pasivo.
Las funciones del sistema de RHEL son un conjunto de funciones y módulos de Ansible que se incluyen en RHEL para brindar uniformidad en los flujos de trabajo y optimizar la ejecución de las tareas manuales. Para obtener más información sobre la agrupación en clústeres de alta disponibilidad de RHEL, consulte la documentación acerca de la configuración y gestión de los clústeres de alta disponibilidad.
Descripción general del entorno
En el entorno que pondremos como ejemplo, tengo un sistema de nodos de control denominado controlnode y dos nodos gestionados, rhel8-node1 y rhel8-node2. Todos ejecutan RHEL 8.6. Ambos nodos gestionados se alimentan a través de un interruptor de alimentación APC con el nombre de host apc-switch.
Quiero crear un clúster denominado rhel8-cluster, que conste de los nodos rhel8-node1 y rhel8-node2. El clúster ejecutará un servidor HTTP Apache en modo activo/pasivo con una dirección IP flotante que prestará servicio a las páginas desde un sistema de archivos ext4 montado en un volumen lógico LVM (gestión de volúmenes lógicos). El aislamiento estará a cargo de apc-switch.
Ambos nodos del clúster están conectados al almacenamiento compartido a través de un sistema de archivos ext4 montado en un volumen lógico LVM. Se instaló y configuró un servidor HTTP Apache en ambos nodos. Consulte los capítulos sobre la configuración de volúmenes LVM con sistemas de archivos ext4 en clústeres de Pacemaker y la configuración de servidores HTTP Apache en el documento Configuración y gestión de clústeres de alta disponibilidad.
Ya configuré una cuenta de servicio de Ansible, denominada ansible, en los tres servidores. También configuré la autenticación de clave SSH para que la cuenta ansible en controlnode pueda iniciar sesión en cada uno de los nodos. Además, la cuenta de servicio ansible se configuró con acceso a la cuenta raíz a través de sudo en cada nodo. También instalé los paquetes rhel-system-roles y ansible en controlnode. Para obtener más información sobre estas tareas, consulte la publicación Introduction to RHEL system roles.
Definición del archivo de inventario y de las variables de las funciones
Desde el sistema controlnode, el primer paso es crear una nueva estructura de directorio:
[ansible@controlnode ~]$ mkdir -p ha_cluster/group_vars
Estos directorios se utilizarán de la siguiente manera:
- El directorio ha_cluster contendrá el playbook y el archivo de inventario.
- El archivo ha_cluster/group_vars contendrá archivos de las variables para los grupos de inventario que se aplicarán a los hosts en los respectivos grupos de inventario de Ansible.
Debo definir un archivo de inventario de Ansible para enumerar y agrupar los hosts que deseo que configure la función del sistema ha_cluster. Crearé el archivo de inventario en ha_cluster/inventory.yml con el siguiente contenido:
---
all:
children:
rhel8_cluster:
hosts:
rhel8-node1:
rhel8-node2:El inventario define un grupo de inventario denominado rhel8_cluster y le asigna los dos nodos gestionados.
A continuación, definiré las variables de la función que controlarán el comportamiento de la función del sistema ha_cluster cuando se ejecute. El archivo README.md para la función ha_cluster está disponible en /usr/share/doc/rhel-system-roles/ha_cluster/README.md y contiene información importante sobre la función, lo que incluye una lista de las variables de funciones disponibles e instrucciones para utilizarlas.
Una de las variables que se deben definir para la función ha_cluster es ha_cluster_hacluster_password. Esta define la contraseña para el usuario hacluster. Usaré Ansible Vault para cifrar su valor de modo que no se almacene en texto sin formato.
[ansible@controlnode ~]$ ansible-vault encrypt_string 'your-hacluster-password' --name ha_cluster_hacluster_password
New Vault password:
Confirm New Vault password:
ha_cluster_hacluster_password: !vault |
$ANSIBLE_VAULT;1.1;AES256 376135336466646132313064373931393634313566323739363365616439316130653539656265373663636632383930323230343731666164373766353161630a303434316333316264343736336537626632633735363933303934373666626263373962393333316461616136396165326339626639663437626338343530360a39366664336634663237333039383631326263326431373266616130626333303462386634333430666333336166653932663535376538656466383762343065
Encryption successfulRemplace your-hacluster-password por la contraseña que prefiera. Una vez que ejecute el comando, se le solicitará una contraseña de Vault que podrá usar para descifrar la variable cuando se ejecute el playbook. Después de escribir una contraseña de Vault y volver a escribirla para confirmar, la variable cifrada se mostrará en el resultado. Se colocará en el archivo de variables que crearemos en el siguiente paso.
Ahora, crearé un archivo que definirá variables para mis nodos de clúster enumerados en el grupo de inventario rhel8_cluster mediante la creación de un archivo en ha_cluster/group_vars/rhel8_cluster.yml con el siguiente contenido:
---
ha_cluster_cluster_name: rhel8-cluster
ha_cluster_hacluster_password: !vault |
$ANSIBLE_VAULT;1.1;AES256
3761353364666461323130643739313936343135663237393633656164393161306535
39656265373663636632383930323230343731666164373766353161630a3034343163
3331626434373633653762663263373536393330393437366662626337396239333331
6461616136396165326339626639663437626338343530360a39366664336634663237
3330393836313262633264313732666161306263333034623866343334306663333361
66653932663535376538656466383762343065
ha_cluster_fence_agent_packages:
- fence-agents-apc-snmp
ha_cluster_resource_primitives:
- id: myapc
agent: stonith:fence_apc_snmp
instance_attrs:
- attrs:
- name: ipaddr
value: apc-switch
- name: pcmk_host_map
value: rhel8-node1:1;rhel8-node2:2
- name: login
value: apc
- name: passwd
value: apc
- id: my_lvm
agent: ocf:heartbeat:LVM-activate
instance_attrs:
- attrs:
- name: vgname
value: my_vg
- name: vg_access_mode
value: system_id
- id: my_fs
agent: ocf:heartbeat:Filesystem
instance_attrs:
- attrs:
- name: device
value: /dev/my_vg/my_lv
- name: directory
value: /var/www
- name: fstype
value: ext4
- id: VirtualIP
agent: ocf:heartbeat:IPaddr2
instance_attrs:
- attrs:
- name: ip
value: 198.51.100.3
- name: cidr_netmask
value: 24
- id: Website
agent: ocf:heartbeat:apache
instance_attrs:
- attrs:
- name: configfile
value: /etc/httpd/conf/httpd.conf
- name: statusurl
value: http://127.0.0.1/server-status
ha_cluster_resource_groups:
- id: apachegroup
resource_ids:
- my_lvm
- my_fs
- VirtualIP
- WebsiteEsto hará que la función ha_cluster cree un clúster denominado rhel8-cluster en los nodos.
Habrá un dispositivo de aislamiento, myapc, de tipo stonith:fence_apc_snmp, definido en el clúster. Se puede acceder al dispositivo en la dirección IP apc-switch con el nombre de usuario y la contraseña apc y apc respectivamente. Los nodos del clúster se alimentan a través de este dispositivo: rhel8-node1 se conecta al socket 1, y rhel8-node2, al socket 2. Dado que no se usarán otros dispositivos de aislamiento, especifiqué la variable ha_cluster_fence_agent_packages. Esta anulará su valor predeterminado y, por lo tanto, evitará que se instalen otros agentes de aislamiento.
Se ejecutarán cuatro recursos en el clúster:
- Al grupo de volúmenes LVM my_vg lo activará el recurso my_lvm de tipo ocf:heartbeat:LVM-activate.
- El sistema de archivos ext4 se montará desde el dispositivo de almacenamiento compartido /dev/my_vg/my_lv en /var/www mediante el recurso my_fs de tipo ocf:heartbeat:Filesystem.
- La gestión de la dirección IP flotante 198.51.100.3/24 para el servidor HTTP estará a cargo del recurso VirtualIP de tipo ocf:heartbeat:IPaddr2.
- El servidor HTTP estará representado por un recurso Website de tipo ocf:heartbeat:apache. Su archivo de configuración se almacenará en /etc/httpd/conf/httpd.conf y la página de estado para supervisión estará disponible en http://127.0.0.1/server-status.
Todos los recursos se colocarán en un grupo apachegroup para que se ejecuten en un solo nodo y comiencen en el orden especificado: my_lvm, my_fs, VirtualIP, Website.
Creación del playbook
El siguiente paso es crear el archivo del playbook en ha_cluster/ha_cluster.yml con el siguiente contenido:
---
- name: Deploy a cluster
hosts: rhel8_cluster
roles:
- rhel-system-roles.ha_clusterEste playbook llama a la función del sistema ha_cluster para todos los sistemas definidos en el grupo de inventario rhel8_cluster.
Ejecución del playbook
Ya configuré todo y estoy listo para ejecutar el playbook. Para esta demostración, usaré un nodo de control de RHEL y ejecutaré el playbook desde la línea de comandos. Usaré el comando cd para moverme al directorio ha_cluster y, luego, usaré el comando ansible-playbook para ejecutar el playbook.
[ansible@controlnode ~]$ cd ha_cluster/ [ansible@controlnode ~]$ ansible-playbook -b -i inventory.yml --ask-vault-pass ha_cluster.yml
Especifico que se debe ejecutar el playbook ha_cluster.yml y que debe hacerlo como usurario root (el indicador -b), que el archivo inventory.yml se debe usar como mi inventario de Ansible (el indicador -i) y que se me debe solicitar que proporcione la contraseña de Vault para descifrar la variable ha_cluster_hacluster_password (el indicador --ask-vault-pass).
Una vez que se completa el playbook, debo comprobar que no haya tareas fallidas:
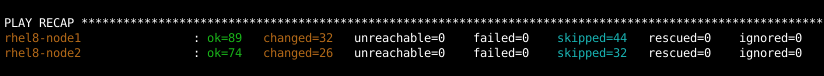
Validación de la configuración
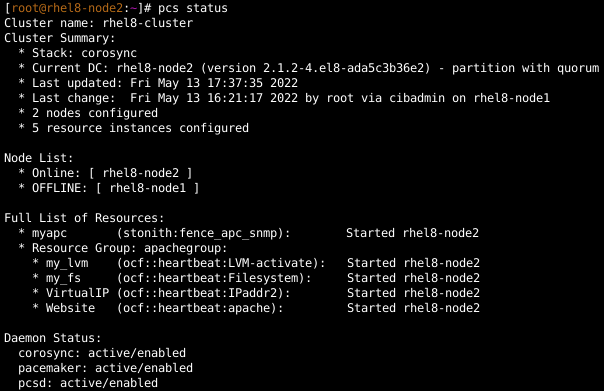
Para comprobar que el clúster se configuró y ejecuta los recursos, iniciaré sesión en rhel8-node1 y observaré el estado del clúster:

También verificaré esto en rhel8-node2, que muestra el mismo resultado.
A continuación, abriré un explorador web y me conectaré a la IP 198.51.100.3 para comprobar que se puede acceder al sitio web.
Para probar la tolerancia a fallos, extraigo un cable de red de rhel8-node1. Después de un tiempo, el clúster utiliza la tolerancia a fallos y aísla rhel8-node1. Inicio sesión en rhel8-node2 y visualizo el estado del clúster. Muestra que todos los recursos migraron de rhel8-node1 a rhel8-node2. También vuelvo a cargar el sitio web en el explorador para comprobar que aún se puede acceder a él.
Vuelvo a conectar rhel8-node1 a la red y lo reinicio una vez más para que vuelva a unirse al clúster.
Conclusión
La función del sistema ha_cluster de RHEL puede ayudarlo a configurar de manera rápida y uniforme los clústeres de alta disponibilidad de RHEL que ejecutan una variedad de cargas de trabajo. En esta publicación, expliqué cómo usar la función para configurar un servidor HTTP Apache que ejecuta un sitio web desde un almacenamiento compartido en modo activo/pasivo.
Red Hat ofrece muchas funciones del sistema de RHEL que pueden ayudar a automatizar otros aspectos importantes de su entorno. Para descubrir más funciones, consulte esta lista y comience a gestionar los servidores de RHEL de manera más eficiente, uniforme y automatizada hoy mismo.
¿Desea obtener más información sobre Red Hat Ansible Automation Platform? Consulte nuestro ebook, El manual para arquitectos de la automatización.
Sobre el autor

Tomas Jelinek is a Software Engineer at Red Hat with over seven years of experience with RHEL High Availability clusters.
Más como éste
Proving open source is ready for the industrial edge
Tackle critical vulnerabilities with the new Red Hat Lightspeed remediation workflow
Technically Speaking | Taming AI agents with observability
You Can’t Automate Expectations | Code Comments
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube