Introduction
This is the fifth installment in the series regarding capacity management with OpenShift.
- In the first post, we saw the basic notions on how resource management works in OpenShift and a way to visualize node and pod resource consumption using kube-ops-view.
- In the second post, we illustrated some best practices on how to protect the nodes from being overcommitted.
- In the third post, we presented best practices on how to setup a capacity management process and which metrics to follow.
- In the fourth post, we introduced the vertical pod autoscaler operator was introduced along with its potential use as a way to estimate the correct sizing of pods.
In this post, we will introduce a ready to use dashboard for which you can base your capacity management process.
The primary goal of this dashboard is to answer a very specific question: Do I need a new node?
Naturally, this is not the only question for a well conceived capacity management process. But, it is certainly a good starting point. It can be used as a foundation for a more sophisticated dashboard that will fully support your capacity management process.
The Dashboard
This capacity management dashboard works on a group of nodes and will help deciding if you need more or less nodes for that group. You can have many node groups in your cluster, so the user can select the node group they want to work on with a drop down list box.
The following illustrates the contents of the capacity management dashboard:

This primary metrics presented are for memory and cpu. The way metrics are collected is the same for memory and CPU. The metrics always refer to aggregates within the selected node group. The Dashboard displays three metrics:
- Quota/Allocatable ratio
- Request/Allocatable ratio
- Usage/Allocatable ratio
If you may recall from the second post on overcommitment, Allocatable is the amount of resources actually available to pods on a given node. This value is calculated out of the total capacity of a node after reserved resources for the operating system and other basic services, such as the container runtime service and the node service, have been accounted for.
In OpenShift 4.x, Prometheus Alerts are also set up during installation. These alerts trigger when the when the Quota/Allocatable ratio passes 100% and when the Request/Allocatable ratio passes 80%.
You can find the dashboard and its installation instructions at this repository. In order to work properly, this dashboard requires the cluster nodes and projects to be organized in a certain way, see at the end of the post more information on this.
In the next section we are going to explain how the collected metrics can be interpreted and used to deduce or forecast whether you need more nodes.
Interpretation of quota/allocatable ratio
This metric is collected as in the formula:
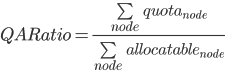
This metric can be interpreted as: what has been promised (the granted quota) vs the actual available amount (the allocatable).
Changes to his metric do not occur frequently and fluctuations typically only occur when new projects are introduced. This metrics is suitable for making long term projections of the needed cluster capacity. Organizations with OpenShift deployments where the nodes cannot be scaled quickly (non-cloud deployments such as bare metal deployments) should most likely use this metric to make a decision on when to scale up nodes.
Depending on your tolerance to risk, it can be ok for this metric to be above 100%, which signals that you have overcommitted the cluster.
Interpretation of request/allocatable ratio
This metric is collected as in the formula:

This metrics can be interpreted as: the value tenants are estimating (if you recall from blog post #3 of this series on developing a capacity management process, resource requests on containers should correspond to the estimated value that will be needed at runtime) they would need versus the actual available amount.
This metric is more volatile than the previous metric because the value changes when new pods are added/removed and is more suitable for making a scaling decision when a new node can be provisioned quickly. This is likely to happen when you are running on cloud environments.
The OpenShift 4.x cluster autoscaler uses this metric indirectly. In fact, it will trigger the addition of a new node if a pod is stuck in a pending state if it cannot be allocated due to a lack of resources. This is approximately the same as triggering a scale up when this metric is measuring close to 100%.
With an approach based node groups, however, we can be more flexible than the cluster autoscaler because we can decide at which threshold we want to scale. For example, with this metric, we can be proactive and add a new node when the ratio hits 80%, so that no pods need to wait before it can be provisioned.
Interpretation of Usage/Allocatable ratio
This metric is collected as in the following formula:
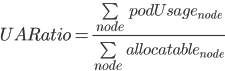
This metrics can be interpreted as what is being currently used vs the amount of available resources. This is clearly the most volatile metric, as it depends on an instant by instant load of running pods.
This metric is generally poor for making capacity forecasts because the values fluctuate too often. However, it can be used to, provide a general overview of the cluster.
The primary function of this metric is to be able to compare the actual (what we are using) with the estimates (the sum of requests from the previous ratio). If these two measures diverge, it means that our tenants are not estimating their resources correctly, and corrective actions are needed.
Another function of this metric is that it allows us to judge whether we have enough resources for the current workload. However, we have to be cognizant that the fact that at the node group level there are enough resources does not guarantee by itself that individual nodes are not resource constrained. For that reason, another set of metrics and alerts needs to be utilized. Fortunately, these node level metrics and alerts are included in the Prometheus setup that comes with OpenShift.
Assumptions
In order for the dashboard to be effective and accurate, there are several assumptions that must be considered
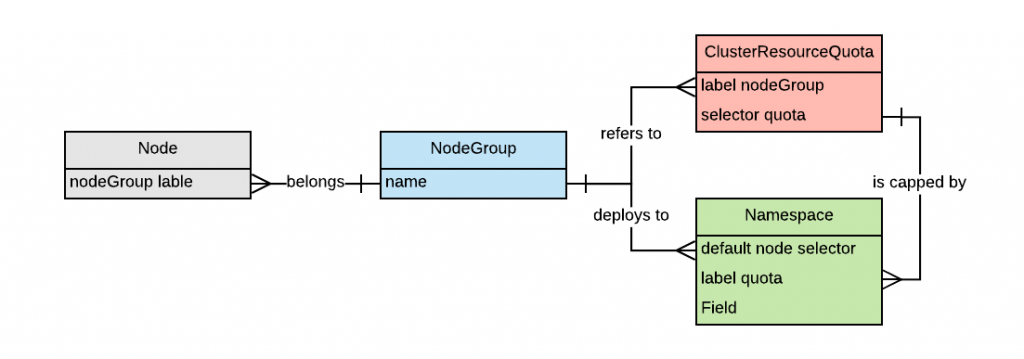
Nodes are grouped into non-overlapping groups. Groups are identified by a node label. The default for the label is nodegroup. Each node must belong to exactly one group. The capacity management dashboard will tell us if we need to add a node to a specific group. Groups can be used to manage zones or areas of the cluster that house different workloads and may need to scale independently. For example, there might be a cluster with high-priority workload nodes, normal priority workload nodes, PCI-dedicated nodes, GPU-enabled nodes, and so on. In OpenShift 3.x, there are always at least three groups: master, infranodes and worker nodes (obviously worker nodes can be fragmented further if needed). In OpenShift 4.x there is no such requirement that infranodes must exist, however the same concepts apply.
ClusterResourceQuotas are defined to limit tenants resource consumption. ClusterResourceQuota is an OpenShift-specific API object that allows for a quota to be defined across multiple projects as opposed to ResourceQuota, which is associated to just one project. The ability of a ClusterResourceQuota to be defined across several projects allows the administrator to choose the granularity at which quotas are applied, achieving higher flexibility. For example, an organization can choose to grant quotas at the application level (an application usually exist on multiple projects to support the environments as defined by a SDLC), the business capability level (usually business capability are provided by a set of applications) or finally, at the line of business level (a set of business capabilities). As a result, ClusterResourceQuotas also allow for a flexible showback/chargeback model should a company decide to enact those processes.
ClusterResourceQuotas must be defined for memory and cpu requests. At the moment, these are the only monitored resources. Other resources can be put under quota, but they would be ignored by the dashboard.
Each ClusterResourceQuota refers to only one node group. For the dashboard to function properly, each ClusterResourceQuota must have the same label as the label used to determine the node group. For example:
apiVersion: quota.openshift.io/v1
kind: ClusterResourceQuota
metadata:
name: quota1
labels:
nodegroup: group1
spec:
quota:
hard:
requests.cpu: "2"
requests.memory: 4Gi
selector:
labels:
matchLabels:
quota: quota1
Each tenant project refers to a ClusterResourceQuota and deploys resources to the corresponding nodegroup. Each tenant project must be controlled by one and only one ClusterResourceQuota. The project default node selector must be configured to select the nodes belonging to the node group the ClusterResourceQuota refers to. For example:
kind: Namespace
apiVersion: v1
metadata:
name: p1q1
labels:
quota: quota1
annotations:
openshift.io/node-selector: nodegroup=group1
Non-tenant projects, such as for example administrative projects, do not have to be under quota. However, the dashboard shows more accurate information if every project deployed on the monitored node groups is under quota.
The recommended approach is to define node labeling at cluster setup and to define the ClusterResourceQuotas and the project during the application onboarding process. The application onboarding process is the set of steps a development team must go through to be able to operate an application on OpenShift. Most organizations have a formalized process detailing these steps.
The below pseudo entity relationship diagram represents the configuration one would attain by the end of this preparation:
Conclusions
In this article, a capacity management dashboard was introduced that can be used as the baseline for an organization’s capacity management process.
With OpenShift 4.x and the introduction of the cluster autoscaler, the urgency of having such a dashboard may be reduced. However, the autoscaler is not always an option and even when it is implemented, it is currently very reactive (it triggers only when a pod cannot be allocated due to lack of capacity). As a result, this dashboard should provide value in understanding capacity management with OpenShift
Sobre el autor

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Más como éste
La paradoja agéntica y los argumentos a favor de la IA híbrida
Deja de administrar el pasado y comienza a forjar el futuro de TI
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube