
Of the many selling points for OpenShift, one of the biggest is its ability to provide a common platform for workloads whether they are on premise or at one of the major cloud providers. With the availability of AWS bare metal instance types, Red Hat has announced that OpenShift 4.9 supports OpenShift Virtualization on AWS as a tech preview. Now virtual machines can be managed in much the same way in the cloud as on-premise.
To get started, follow the steps outlined in the OpenShift Documentation for AWS Installations through the section “Creating the installation configuration file”. The default installer-provisioned infrastructure (IPI) configuration creates three control plane nodes and three worker nodes, each on EC2’s M4.xlarge instance types. Unfortunately, these instance types are already virtual, and do not offer virtualization extensions to the operating system. OpenShift Virtualization will not schedule virtual machines on these instances without activating software emulation, a route we strongly discourage because it significantly impacts performance. Instead, we will utilize EC2 M5.metal instances, which, as the name suggests, provide non-virtual baremetal nodes that can be used the same way as the virtual instances.
There are multiple ways to add metal instances to an OpenShift cluster on AWS. We will cover two of these.
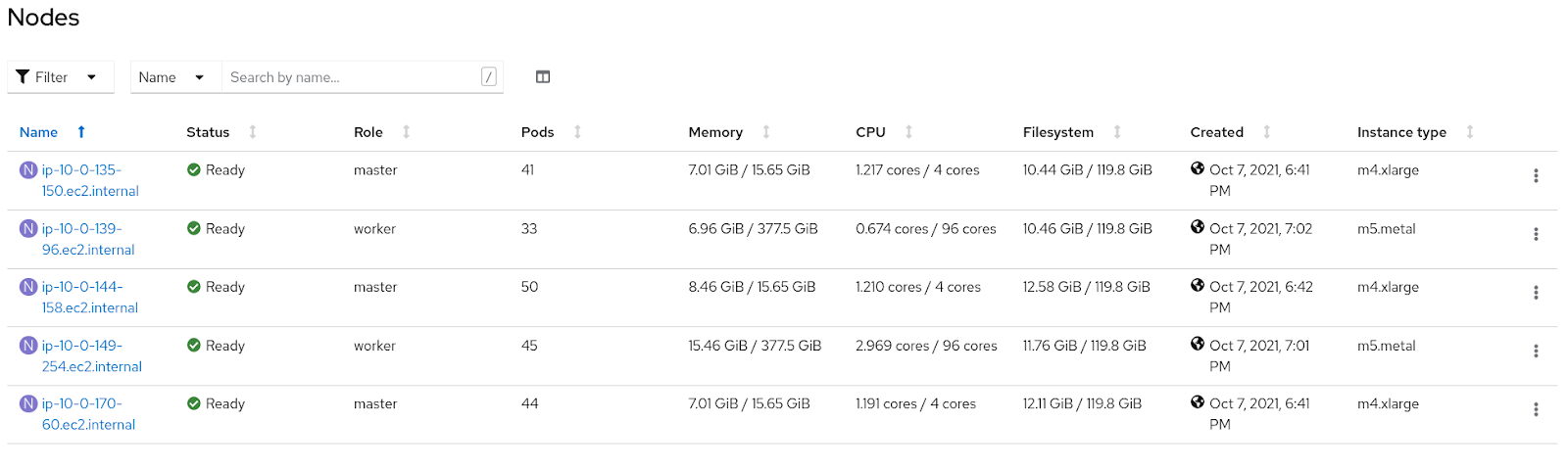
Install OpenShift with all metal nodes
In the first case, we will use the default m4.xlarge instance type only for the control plane, and change the default for worker nodes to m5.metal. To accomplish this, generate an install configuration using the openshift-install command line tool and edit it prior to cluster installation to include two metal worker nodes instead of three virtual ones. As openshift-install consumes and deletes the install-config.yaml every time it creates a cluster, if you plan to experiment with this method more than once, be sure to make a copy of the generated install-config.yaml file outside of the cluster directory.Find the section for compute: and make the following changes:
compute:
- architecture: amd64
hyperthreading: Enabled
name: worker
platform:
aws:
type: m5.metal
replicas: 2
As the metal nodes are around 20 times more expensive than virtual, it is worth scaling back the number of worker nodes to two, especially in a proof of concept environment. Do not go lower than two; the install will fail if there is only one worker node.
Copy the edited install-config.yaml to a cluster directory and run the openshift-installer create cluster command specifying that directory using the --dir option:
cp install-config.yaml cluster/install-config.yaml
openshift-install create cluster --dir=cluster
Note: It is important to preserve the contents of this directory during the lifetime of the cluster. When it comes time to destroy the cluster, openshift-install will process this directory to ensure it destroys all resources it created. Without it, you must manually clean up the AWS account, which can be quite time intensive.
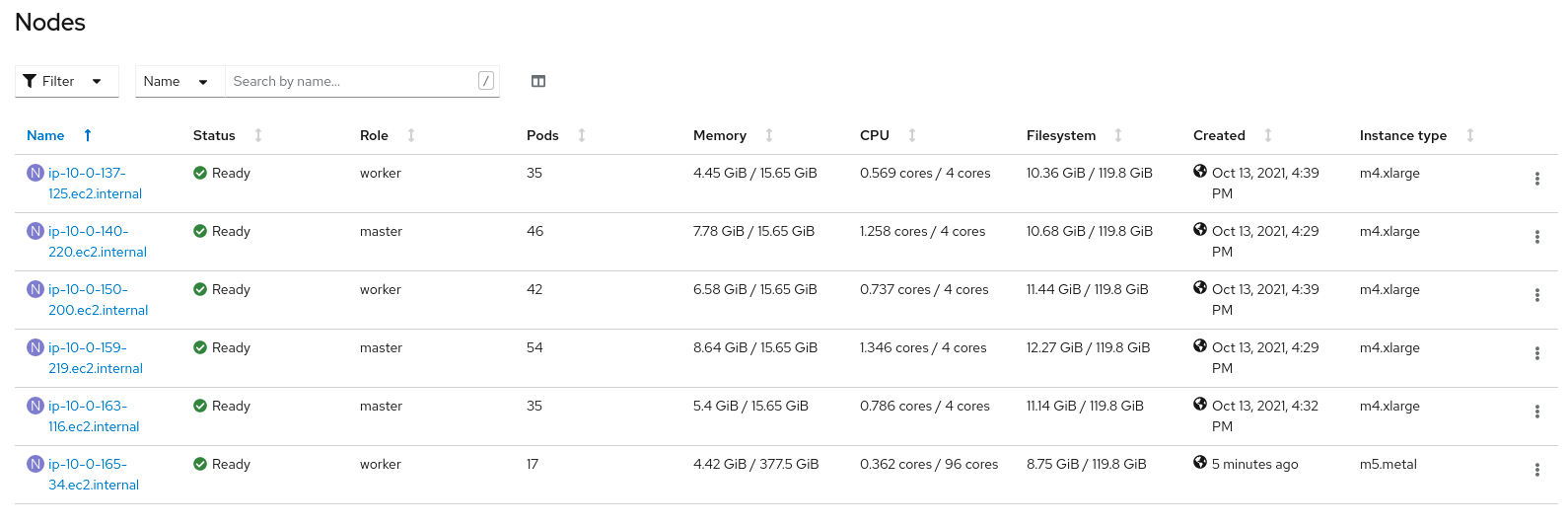
Install OpenShift with a mix of metal and virtual nodes
The second case is more flexible but requires more work post-install. We will use the default m4.xlarge instance types for a five node cluster, then add a metal node once it installs. Edit the compute: section of the install-config.yaml as above, but leave the platform untouched (it should be “{}”) and decrease the replicas to 2. This will ensure the cluster comes up as expected. In an EC2 region with multiple availability zones (AZs), nodes will round-robin from each AZ until replicas are met. In the us-east-1 region, two replicas will create a worker node in us-east-1a and us-east-1b. All other AZs in the region should be present as machine sets, but scaled down to zero replicas. We can see the current distribution of nodes and node types by looking at the machines in the openshift-machine-api namespace:
oc -n openshift-machine-api get machines
NAME PHASE TYPE REGION ZONE AGE
integration-q26vf-master-0 Running m4.xlarge us-east-1 us-east-1a 26m
integration-q26vf-master-1 Running m4.xlarge us-east-1 us-east-1b 26m
integration-q26vf-master-2 Running m4.xlarge us-east-1 us-east-1c 26m
integration-q26vf-worker-us-east-1a-jqf6m Running m4.xlarge us-east-1 us-east-1a 17m
integration-q26vf-worker-us-east-1b-89prs Running m4.xlarge us-east-1 us-east-1b 17m
The MachineSet name is embedded in the machine name for each worker. From this list you can see that there are m4.xlarge worker nodes running in us-east-1a and us-east-1b as mentioned above. To see all the MachineSets, perform a get in the same namespace for those resources instead:
oc -n openshift-machine-api get machinesets
NAME DESIRED CURRENT READY AVAILABLE AGE
integration-q26vf-worker-us-east-1a 1 1 1 1 29m
integration-q26vf-worker-us-east-1b 1 1 1 1 29m
integration-q26vf-worker-us-east-1c 0 0 29m
integration-q26vf-worker-us-east-1d 0 0 29m
integration-q26vf-worker-us-east-1e 0 0 29m
integration-q26vf-worker-us-east-1f 0 0 29m
Here we can see that the machineset in us-east-1c has no replicas since we created the cluster with only two workers.
Next, edit the first unused MachineSet, integration-q26vf-worker-us-east-1c in our case, and change the spec.template.spec.providerSpec.value.instanceType to m5.metal.
export NAME=integration-q26vf
oc -n openshift-machine-api patch machineset $NAME-worker-us-east-1c \
--type=json \
-p='[{"op": "replace", "path": "/spec/template/spec/providerSpec/value/instanceType", "value": "m5.metal"}]'
After making the edit, scale the MachineSet to 1 replica:
oc -n openshift-machine-api scale machineset integration-q26vf-worker-us-east-1c --replicas=1
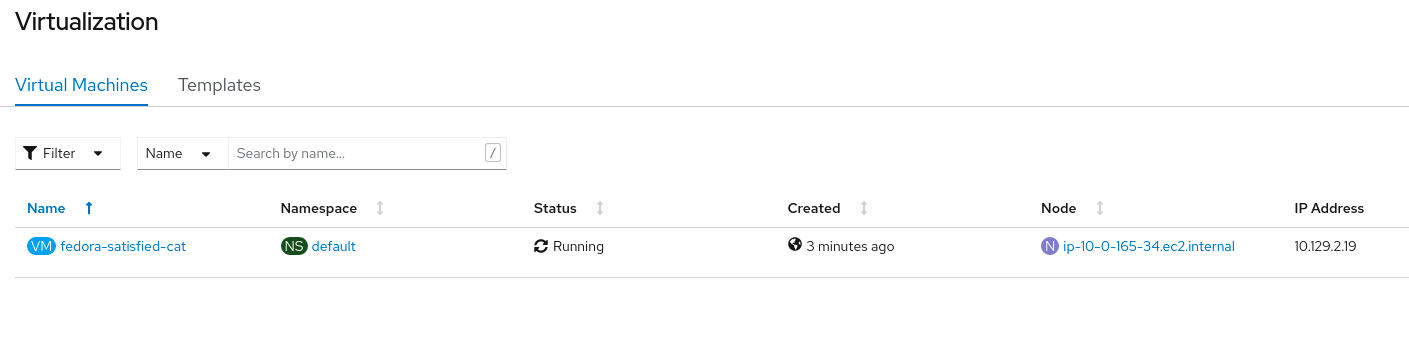
Install OpenShift Virtualization
Following the instructions on the OpenShift Virtualization documentation website, install OpenShift Virtualization from OperatorHub and create a HyperConverged resource to instantiate it. Specifying nodes for OpenShift Virtualization components details how to ensure OpenShift Virtualization only runs on particular nodes, but since the virtual worker nodes are unschedulable due to lack of virtualization functions, this is unnecessary. Virtual machines will automatically find their way to the baremetal node or nodes in the cluster.
Create a virtual machine
Fedora 34 has a relatively small cloud image available for download at https://alt.fedoraproject.org/cloud/ so to demonstrate running a VM on the new baremetal node, visit the Workloads -> Virtualization -> Virtualization Templates page in the console, and click “Add source” next to Fedora 32. Note that the version number is not important, only the downloaded image. Follow the instructions, setting the boot source type to “Import via URL” and paste the URL to the Cloud Base compressed raw image for Fedora 34. The provider field can be set to “Fedora”.
Once the boot source image has fully downloaded, it will show a check mark, and a VM may be created. Click “Create VM”, and follow the prompts to create and start the VM. There will be a brief delay as the boot source image is cloned before the VM starts on the metal node.
A word on storage classes
It is important to note that the storage used for data volumes like the boot source images and the Fedora VM’s root disk are all AWS Elastic Block Storage (EBS) GP2 volumes. GP2 is provided as a default storage class for AWS OpenShift clusters, but it only supports ReadWriteOnce (RWO) mode as opposed to Read Write Many (RWX). Due to this difference, VM migration is not possible using the default storage class.
If VM migration is desired, then OpenShift Container Storage (OCS) fits the bill. OCS may be installed through OperatorHub. Specific instructions for installing OCS on AWS are available through the Red Hat Customer Portal.
Once OCS is installed and available, a new StorageClass “ocs-storagecluster-ceph-rbd” will be available. Set this as the default StorageClass by deleting the storageclass.kubernetes.io/is-default-class annotation from the “gp2” StorageClass and adding it to “ocs-storagecluster-ceph-rbd”
oc annotate storageclass gp2 storageclass.kubernetes.io/is-default-class-
oc annotate storageclass ocs-storagecluster-ceph-rbd \
storageclass.kubernetes.io/is-default-class=true
Now any PVCs and DataVolumes created by OpenShift Virtualization should be RWX and therefore VMs running them will be migrateable.
Note the StorageClass of the VM’s disk:

Migrating...

Migrated.

Clean up and conclusion
In the case that this is a proof of concept, there is strong motivation to spin up, perform tests, and spin down quickly. OpenShift’s installer makes cleanup a simple matter. Run:
openshift-install destroy cluster --dir=cluster
Assuming the cluster’s state directory is still available, the installer will spin down the whole OpenShift cluster, including the additional bare metal nodes, deleting resources in reverse order of their creation.
As you can see, OpenShift Virtualization is a powerful tool to abstract older virtualized infrastructure, allowing you to carry workloads wherever your computing needs are best satisfied.
Sobre el autor
Más como éste
La paradoja agéntica y los argumentos a favor de la IA híbrida
Deja de administrar el pasado y comienza a forjar el futuro de TI
Command Line Heroes en español. Temporada 1: Descifrando el código de la nube abierta
Edge computing covered and diced | Technically Speaking
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube