The shift from Chef to Red Hat Ansible Automation Platform has become a strategic choice for many organizations seeking simplicity, scalability and ease of use for configuration management and automation tools. This article explores the process of converting Chef cookbooks into Ansible Playbooks, providing insights and guidance for a smooth and efficient transition.
Understanding the differences
Chef and Ansible Automation Platform, while both prominent tools share the common goal of automating infrastructure tasks, they differ in their approaches to configuration management and exhibit distinctive features in terms of syntax, architecture and operational methodologies. Let's explore the key differentiators between these two remarkable technologies.
- Configuration Language: Chef utilizes a domain-specific language (DSL), which requires users to be familiar with Ruby scripting for defining configurations. The Chef DSL consists of resources, recipes, and attributes, providing a flexible but code-intensive approach.
In contrast, Ansible Automation Platform relies on a YAML-based syntax, which is known to be a simple and easy-to-understand human-readable format. - Agent Vs. Agentless: Chef follows a client-server architecture where a Chef client, installed on each managed node, communicates with a central Chef server. This requires the installation of the Chef client on each managed machine.
Ansible Automation Platform, on the other hand, operates in an agentless manner over SSH. It does not require the installation of agents on managed nodes, reducing the overhead associated with agent-based systems.
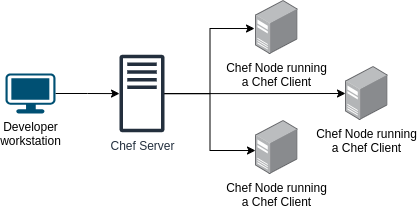
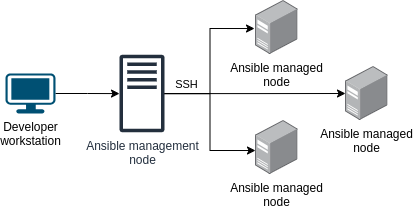
- Execution model: Chef operates with a procedural execution model where recipes define the order in which tasks are executed on nodes. It uses resources and providers to manage configurations and dependencies.
Ansible Automation Platform adopts a declarative approach, specifying the desired state of the system rather than the sequence of steps to reach that state. Ansible Playbooks define the desired configuration, and Ansible Automation Platform handles the execution details. The following example showcases the procedural nature of Chef where the action to be performed is explicit whereas the Ansible Automation Platform equivalent simply expresses the desired state.
| |
- Ease of adoption: Learning and mastering the Ruby language is a prerequisite for effectively using Chef. While powerful, this can be a barrier for those unfamiliar with Ruby.
Ansible Automation Platform's YAML syntax is straightforward and requires a minimal learning curve. Its simplicity contributes to a lower entry barrier, making it accessible to a broader audience with varying skill sets.
Chef and Ansible Automation Platform terminology
Let's closely examine and dissect the terminology employed in Chef and Ansible Automation Platform, shedding light on both their nuanced disparities and shared foundational concepts.
In the realm of shared concepts, both Chef and Ansible Automation Platform utilize the term "node" which signifies a system under Chef's (or Ansible Automation Platform’s) management. They both use the concept of a "role" as a means to encapsulate patterns and processes across managed nodes. In Chef, a role defines a set of attributes and a run list, specifying what should be applied to a node when it assumes that particular role. Similarly in Ansible Automation Platform, a role is a collection of tasks, handlers, templates and other elements organized in a predefined directory structure. Roles promote reusability and consistency in configuring different servers. Additionally, they both use the concept of "attribute" also termed as "variable" or reusable values which is a means to customize configurations.
Chef introduces a distinctive set of tool-specific terms. A "cookbook" serves as a fundamental unit, encapsulating recipes, attributes and resources. A "recipe" is akin to a script, detailing the actions Chef should perform on a given node and composed of resources, which represent building blocks specifying the desired state of a specific system aspect. A “Data Bag” is a centralized container for data that is not tied to a single node and is shared by all nodes.
On the Ansible Automation Platform front, the terminology reflects its unique approach and design philosophy. A "playbook" stands out as a YAML file that defines a set of tasks and configurations to be executed on remote hosts (the equivalent of cookbook in Chef). A "task" serves as the fundamental unit of work within an Ansible Playbook, representing a specific configuration action to be performed on a remote host. "Inventory" is a file or script that enumerates the hosts or nodes to be managed by Ansible Automation Platform. "Module" refers to a standalone, reusable piece of code that encapsulates specific tasks, enhancing modularity and reusability (the equivalent of resource in Chef). "Collections" are a way to organize, package and distribute Ansible content, including playbooks, roles, modules and plugins. "Facts" denote system information automatically gathered by Ansible Automation Platform from remote hosts, serving as variables in playbooks. Lastly, a "handler" in Ansible Automation Platform is a task triggered by other tasks, typically used for actions like restarting services.
Folder structure
In Chef, the folder structure revolves around the concept of cookbooks. Each cookbook resides within a dedicated directory, containing subdirectories like "recipes," "attributes," and "files" to organize various components. This modular structure aligns with Chef's procedural execution model, where recipes dictate the order of tasks. On the other hand, Ansible Automation Platform, following a declarative execution model, adopts a flatter and more straightforward folder structure. Playbooks, written in YAML, are at the core, residing alongside additional directories like "roles" for organizing reusable components with subdirectories for tasks, handlers, defaults, and templates.
In the subsequent table, we illuminate the key files and directories commonly encountered in a Chef folder structure, juxtaposed with their counterparts in Ansible Automation Platform.

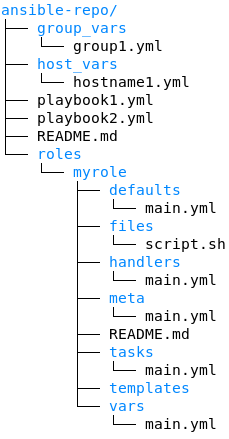
Now let’s compare some of the main Chef files and folders side by side with their closest equivalents in Ansible Automation Platform, while explaining the nuances and differences.
Chef | Ansible | |
metadata.rb | meta/main.yml | In Ansible Automation Platform, there isn't a direct equivalent to the metadata.rb file found in Chef. The metadata.rb file in Chef is used to define metadata about the cookbook, such as its name, version, dependencies and other information. Ansible Automation Platform follows a different structure and approach, and information similar to that found in metadata.rb is typically distributed across different files. Here's how you might distribute metadata-like information in Ansible Automation Platform:
While Ansible Automation Platform doesn't have a dedicated file for metadata, it encourages the use of well-documented roles and playbooks, making information easily accessible to users and contributors. The absence of a centralized metadata file aligns with Ansible Automation Platform's philosophy of simplicity and a decentralized structure. |
README.md | README.md | To provide documentation about the cookbook in Chef or Playbook in Ansible Automation Platform. |
attributes/ | group_vars/, host_vars/, defaults/, vars/ | In Chef, the attributes folder plays a role in organizing and managing attribute files within a cookbook. Attributes are variables that store configuration data, allowing for dynamic and flexible customization of the cookbook's behavior. The attributes folder typically contains one or more Ruby files (.rb), each dedicated to defining a set of attributes related to a specific aspect of the cookbook.
|
files/ | roles/myrole/files/ | In Chef, the files folder is a directory where you can store static files that need to be transferred to nodes during the chef-client run. These files are typically used by recipes to configure or support the application being deployed. For example, configuration files, scripts, or binary files might be placed in the files directory. In Ansible Automation Platform, the equivalent to the Chef files folder is the files directory within an Ansible Role. The files directory in an Ansible Role can contain files that need to be copied to the remote hosts during the playbook run. |
recipes/ | roles/myrole/tasks/ | In Chef, the recipes folder is a directory where you organize the recipes associated with a cookbook. A recipe in Chef is a collection of resources and their properties, defining a series of steps to bring a node to a desired state. The recipes directory typically contains one or more Ruby files (.rb), each representing a distinct recipe within the cookbook. The Ansible Automation Platform equivalent to Chef's recipes directory is the tasks directory within an Ansible Role. In Ansible Automation Platform, a role is a collection of tasks, handlers, templates and other elements organized in a predefined directory structure. The tasks directory contains YAML files with tasks that define the desired state for the nodes. Note that if you don’t use roles, the tasks directory is not needed and the tasks will be simply listed under the task key within a playbook file. |
templates/ | templates/ | In Chef, the templates folder is a directory where you store template files. Templates are used to dynamically generate configuration files by embedding variables and expressions. These templates can be processed during the chef-client run to produce configuration files tailored to the specific attributes and settings of a node. The Ansible Automation Platform equivalent to Chef's templates directory is the templates directory within an Ansible Role. Ansible Automation Platform uses Jinja2 templating language for its templates. Note that if you don’t use roles, the templates folder can be placed at the playbook level. In fact, the presence of this folder is not mandatory but it is a good practice for clarity and consistency. While the template syntax may differ (ERB in Chef, Jinja2 in Ansible Automation Platform), the purpose remains the same: to create configuration files that are customized based on variables and expressions defined in the respective configuration management systems. |
Berksfile | meta/main.yml | In Chef, the Berksfile is used in conjunction with Berkshelf, a dependency manager for Chef cookbooks. The Berksfile specifies the dependencies and their versions that a cookbook relies on. Berkshelf resolves and retrieves these dependencies, ensuring that the cookbook has access to the required resources during the chef-client run. In Ansible Automation Platform, there isn't a direct equivalent to the Berksfile because Ansible Automation Platform uses a different approach to dependency management. Ansible Galaxy is the primary platform for sharing and discovering Ansible Roles. Roles in Ansible Automation Platform can specify their dependencies in the meta/main.yml file. An additional requirements.yml file can be used as well by the ansible-galaxy command line tool to install role dependencies. |
Migration stages
Migrating from Chef to Ansible Automation Platform involves a strategic transition plan that typically unfolds in distinct phases to ensure a smooth and efficient process.
Planning phase
The primary objective of the planning phase is to gain a comprehensive understanding of the existing Chef infrastructure. This involves identifying the roles, recipes and attributes currently in use within the Chef environment. Clearly identify the key components within Chef that play a crucial role in defining and managing the infrastructure. These components may include custom roles created for specific server types, recipes outlining application deployment steps, and attributes specifying configuration parameters. We can then determine how each identified component in Chef can be translated into Ansible Automation Platform equivalents. Roles in Chef may correspond to roles or even collections in Ansible Automation Platform, recipes may become tasks in Ansible Playbooks and Chef attributes might be replaced with Ansible variables.
Finally identify any potential challenges or risks associated with the migration process. This may include dependencies between roles or specific configurations that require careful consideration.
Translation phase
In this step, the focus is on the conversion of Chef recipes into Ansible Playbooks. A Chef recipe, which defines the tasks to be executed on a node, is now translated into Ansible's equivalent structure using YAML syntax.
Translate each task defined in a Chef recipe into the equivalent task in Ansible Automation Platform. Pay attention to the sequence, parameters, and dependencies of each task. Consider the use of handlers if event handling is being used in the Chef recipes that you are translating. Handlers are typically employed to respond to specific events. In Ansible Automation Platform, handlers serve a similar purpose.
Convert Attributes to Ansible Variables
In Chef, attributes are used to define configuration settings. These attributes store information about the current state and configuration of nodes. They play a crucial role in customizing the behavior of recipes and, by extension, the overall infrastructure. As part of the migration process, Chef attributes need to be translated into Ansible variables. Ansible variables serve a similar purpose—they allow the dynamic definition of values that can be used across playbooks.
A classical pattern found in Chef projects is the reliance on a central data location called data bag. It acts as a global repository for sensitive information, configuration settings, or any data needed during the configuration process. How does one manage the equivalent of Chef data bags in Ansible Automation Platform?
When transitioning from Chef to Ansible Automation Platform, careful consideration is required when dealing with data bags. Ansible Automation Platform lacks a direct equivalent to the centralized server-based data bag concept in Chef due to its decentralized and agentless architecture. Consequently, translating data bags to Ansible Automation Platform involves distributing their content across multiple locations. Sensitive information may be stored in encrypted files or managed using Ansible vault for security. Configuration settings and other data can be dispersed throughout playbooks, roles or inventory files. The key lies in analyzing the specific contents of the data bag and strategically placing the information within the Ansible Automation Platform structure, enabling a seamless transition while adhering to Ansible Automation Platform's decentralized nature.
In Ansible Automation Platform, variable files provide a structured way to organize and manage variables across playbooks and roles. Several types of variable files serve different purposes within the Ansible Automation Platform framework. Firstly, there are "host_vars" and "group_vars" directories at the inventory level, allowing the assignment of variables to specific hosts or groups of hosts respectively. These variables are then accessible during playbook execution. At the playbook level, "vars_files" can be specified to include external YAML files containing variables. Roles, which encapsulate reusable components, can have their own set of variables stored in the "vars" directory. Additionally, "defaults" in the role structure can house default variable values. Lastly, Ansible vault provides a secure way to manage sensitive information by encrypting variable files. This rich ecosystem of variable files in Ansible facilitates a modular and organized approach to configuration, enabling efficient management of variables at different levels of the playbook and role hierarchy.
If the need arises to centralize data for accessibility across various independent playbooks and multiple runs, a recommended approach is to establish a dedicated data repository. This repository can house your data in either YAML or JSON files. By pushing this repository to an accessible location such as Git or its equivalent, you not only allow a centralized and version-controlled storage of data but also facilitate seamless sharing and retrieval across different playbooks. Additionally, leveraging the Ansible Git module allows for automated retrieval and synchronization of data, further streamlining your workflow and enhancing collaboration.
A complementary method to employing the Ansible Git module for retrieving common data from a Git repository is to create a dedicated Ansible Role. This role would be responsible for fetching the required data from Git and injecting it as facts, readily available for consumption by your playbook. This approach encapsulates the logic within a reusable and modular component, promoting better organization and maintainability of your Ansible infrastructure.
Leverage Ansible Modules
Ansible Automation Platform's strength lies in its extensive library of modules that abstract complex tasks into simple, reusable components. Identify Chef resources and actions and replace them with corresponding Ansible modules. Thanks to Ansible's extensive module ecosystem, it's rare not to find a suitable replacement for a Chef resource. However, in exceptional cases where a direct equivalent isn't available, Ansible Automation Platform offers the flexibility to develop custom modules using Python programming language.
A common pattern found in Chef cookbooks is the extensive use of Ruby code. Injecting Ruby code in Chef cookbooks is very tempting and powerful at the same time but leads to a complicated logic and hard to understand automation scripts. When converting to Ansible Automation Platform, you may also be tempted to simply translate the Ruby code into Python or even shell scripts and then call these from your playbook. This is generally a bad idea and the best practice is to look for an Ansible module that does what you want. Ansible modules are idempotent and regularly maintained and updated. If you code your own script or module, the responsibility of assuring idempotency and maintenance falls on you.
Test and optimize
Thorough testing is crucial to validate the functionality and integrity of your converted playbooks. Create a staging environment that mirrors your production setup and run comprehensive tests to identify and resolve any issues. This iterative testing process offers a seamless transition when deploying to production. Ansible Automation Platform has an ecosystem ranging from static syntax checking and linting such as Ansible lint to testing the execution of playbooks, roles and collections such as Ansible Molecule which provisions virtualized test hosts.
Closing thoughts
Chef and Ansible Automation Platform are both great automation tools helping companies to configure and maintain large infrastructures. In this article we shed some light on the journey of converting a Chef automation environment to its Ansible Automation Platform equivalent by highlighting commonalities and differences between the two systems.
Sobre el autor

Chad Zammar is a Red Hat Certified Architect and Senior Consultant specialized in IT and Infrastructure automation with Ansible and OpenShift.
He earned his PhD in Computer Science in 2005 and has since been very active in the field of software engineering and solutions architecture. He acquired a wide range of technical skills through engagements with companies in diverse sectors, including but not limited to distributed systems, cloud architecture and technologies, data engineering, operations research, AI, web technologies, telecommunications, virtual reality, and embedded systems.
Chad lives in Montreal where he is either hiking, road tripping, reading a paper-based book or automating something with Ansible.
Más como éste
AIOps and Ansible Automation Platform: Where AI intelligence meets trusted execution
Why automated OS upgrades still need a human in the loop
Technically Speaking | Taming AI agents with observability
Lightspeed automation with generative AI | Technically Speaking
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube