Operator Metering es una herramienta de generación de informes y devolución de cargos (chargeback) que proporciona información sobre el uso de los recursos en un clúster de Kubernetes. Los administradores pueden programar informes basados en datos de uso históricos por pod, espacio de nombres y clúster.
Una vez que se instala el operador, puede acceder a muchas consultas de informes listos para usar. Por ejemplo, si un administrador desea medir el uso de la CPU o de la memoria para los nodos o los pods del clúster, todo lo que debe hacer es instalarlo y escribir un recurso Report personalizado para generar un informe, que puede ser por mes, por hora, etc.
Casos prácticos
Los clientes siempre solicitan ciertos requisitos.
- Es posible que los nodos de trabajo en un clúster de OpenShift para entornos que no son de producción no se estén ejecutando todo el tiempo (por ejemplo, un administrador desea desactivar algunos nodos según la capacidad disponible o durante los fines de semana). Por lo tanto, necesitan medir mensualmente el uso de la CPU o de la memoria de un nodo para que el equipo de infraestructura pueda devolver los cargos a los usuarios en función del uso real del nodo.
- Los clientes tienen un modelo en el que implementan un clúster de OpenShift exclusivo para ciertos equipos en particular. Podrían instalar la herramienta Operator Metering y conocer el uso que se le da al nodo; sin embargo, desean incluir el equipo o la línea de negocio que se usa en el informe de devolución de cargos. Este caso práctico también puede aplicarse para las situaciones en las que un clúster exclusivo compartido tiene nodos "etiquetados" y cada etiqueta identifica la carga de trabajo de la línea de negocio o del equipo que se ejecuta en ellos.
- En un clúster compartido, al equipo de operaciones le gustaría devolver los cargos a los equipos según el tiempo de ejecución de los pods (puede ser el consumo de la CPU o de la memoria). Una vez más, desean que el informe sea más sencillo al incluir el equipo o la línea de negocio a la que pertenecen los pods.
Estos requisitos conducen a la creación de algunos recursos personalizados en el clúster, y en este artículo aprenderemos la forma de realizarlo con facilidad. Tenga en cuenta que no se incluye la instalación de Operator Metering. Puede consultar la documentación relacionada con este tema aquí. Para obtener más información sobre la implementación de los informes listos para usar, consulte la documentación aquí.
¿Cómo funciona Metering?
Como se mencionó en la sección anterior, analicemos el funcionamiento de OpenShift Metering antes de pasar a la creación de nuevos recursos personalizados para nuestro caso práctico. Hay un total de seis recursos personalizados que Operator Metering crea una vez que se instala; de los cuales los siguientes requieren una explicación más detallada.
- ReportDataSources (rds): es el mecanismo para definir los datos que están disponibles y pueden ser usados por los recursos personalizados ReportQuery o Report. También permite obtener datos de varias fuentes. En OpenShift, los datos se extraen de Prometheus y del recurso personalizado ReportQuery (rq).
- ReportQuery (rq): contiene las consultas SQL para realizar análisis en datos almacenados con rds. Si un objeto Report hace referencia a un objeto rq, entonces este también gestionará lo que se documentará cuando se ejecute el informe. Si un objeto rds hace referencia al objeto rq, este indicará que la medición cree una visualización dentro de las tablas de Presto, que se crean como parte de la instalación, según la consulta que se procese.
- Report: es un recurso personalizado que logra que se generen informes con el recurso ReportQuery configurado. Es el recurso principal con el que interactúa un usuario final de Operator Metering. Se puede configurar para ejecutarse en un momento específico.
Hay muchos rds y rq listos para usar que están disponibles. Dado que nos centramos en la medición del nivel de los nodos, mostraré los que necesitamos conocer para escribir nuestras propias consultas personalizadas. Ejecute el siguiente comando mientras está en el proyecto "openshift-metering":
$ oc project openshift-metering $ oc get reportdatasources | grep node node-allocatable-cpu-cores node-allocatable-memory-bytes node-capacity-cpu-cores node-capacity-memory-bytes node-cpu-allocatable-raw node-cpu-capacity-raw node-memory-allocatable-raw node-memory-capacity-raw |
Nos centraremos en los siguientes dos rds: "node-capacity-cpu-cores" y "node-cpu-capacity-raw", ya que queremos medir el consumo de la CPU. Centrémonos en node-capacity-cpu-cores y ejecutemos el siguiente comando para ver cómo recopila datos de Prometheus:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml spec: prometheusMetricsImporter: query: | kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id) |
Se puede observar la consulta que se usa para obtener datos de Prometheus y almacenarlos en tablas de Presto. Ejecutemos la misma consulta en la consola de indicadores de OpenShift y veamos el resultado. Hay un clúster de OpenShift con 2 nodos de trabajo (cada uno tiene 16 núcleos) y 3 nodos maestros (cada uno tiene 8 núcleos). La última columna denominada "Value" registra los núcleos asignados a los nodos.
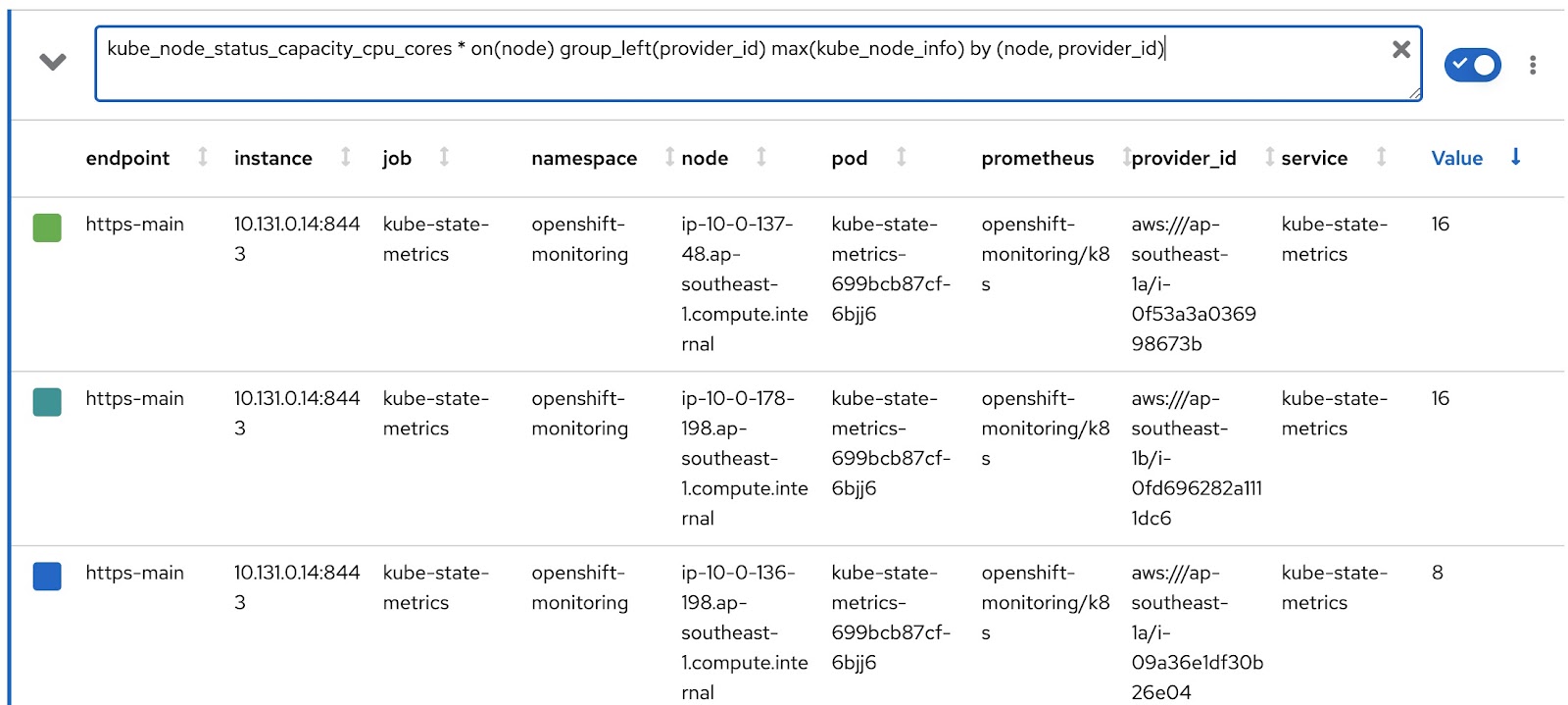
Por lo tanto, los datos se recopilan y almacenan en las tablas de Presto. Ahora, centrémonos en un par de recursos personalizados ReportQuery (rq):
$ oc project openshift-metering $ oc get reportqueries | grep node-cpu node-cpu-allocatable node-cpu-allocatable-raw node-cpu-capacity node-cpu-capacity-raw node-cpu-utilization |
En este caso, nos centraremos en los rq "node-cpu-capacity" y "node-cpu-capacity-raw". Si describe estos objetos ReportQueries, descubrirá que calculan datos, como el tiempo que lleva activo el nodo, la cantidad de CPU asignadas, etc., y los agrupan.
De hecho, en el siguiente diagrama se muestra la cadena de conexión de los dos rds y los dos rq.
node-cpu-capacity (rq) utiliza node-cpu-capacity-raw (rds) utiliza node-cpu-capacity-raw (rq) utiliza node-capacity-cpu-cores (rds)
Personalización de informes
Centrémonos en escribir nuestros rds y rq personalizados. Primero, debemos cambiar la consulta de Prometheus para incluir la clasificación del funcionamiento del nodo como maestro o de trabajo e incluir la etiqueta adecuada que identifique el equipo al que pertenece. La métrica de Prometheus "kube_node_role" cumple la función de nodo wrt de datos (como maestro o de trabajo). Observe la columna "role":

El indicador de Prometheus "kube_node_labels" detecta todas las etiquetas que se aplican en un nodo, y todas ellas se identifican como "label_
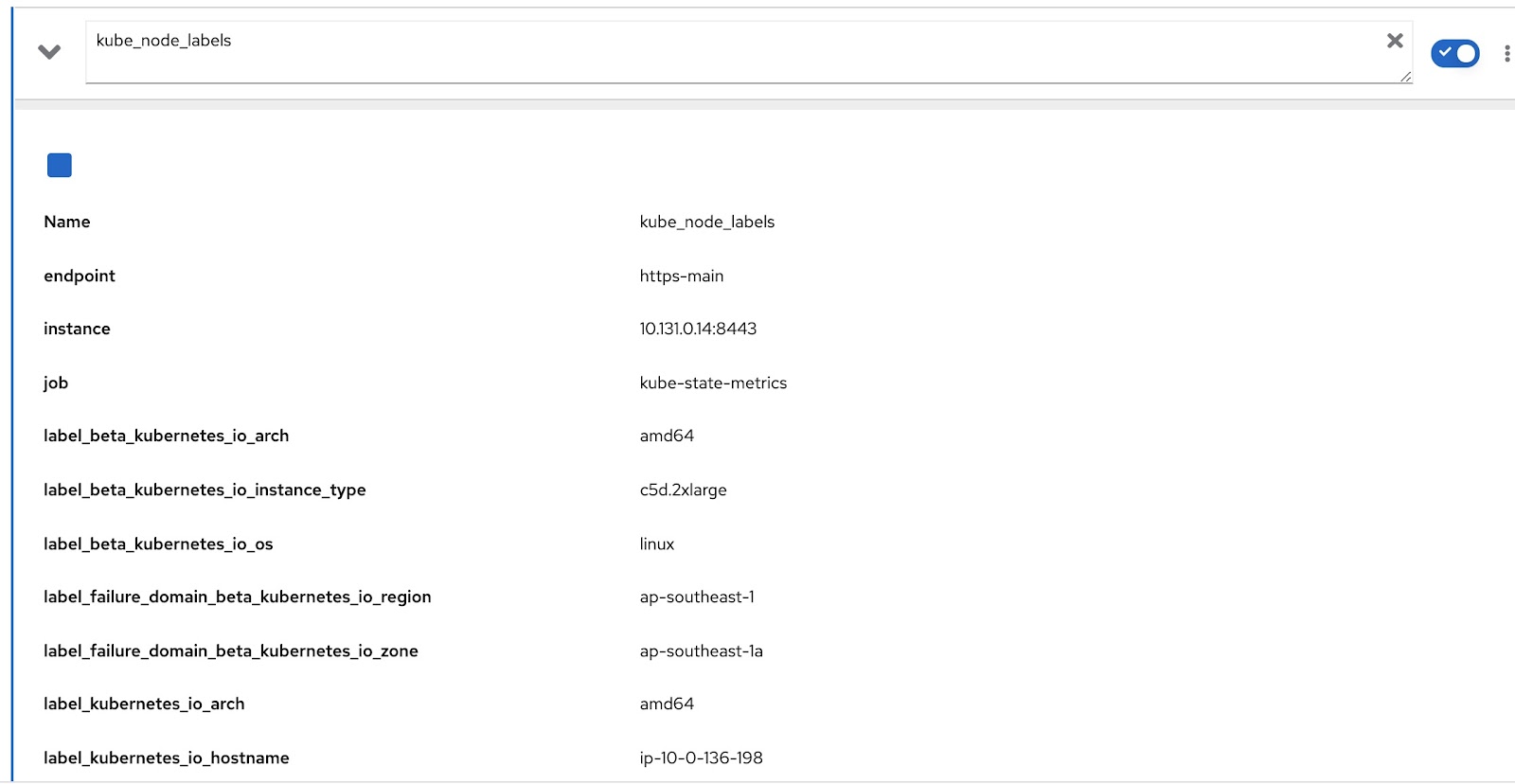
Ahora, todo lo que debemos hacer es modificar la consulta original con este par de consultas adicionales de Prometheus para obtener datos relevantes, la cual será:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, rol) kube_node_labels
Ejecutemos esta consulta en la consola de indicadores de OpenShift y comprobemos que obtuvimos tanto la etiqueta (node_lob) como la información de la función. A continuación, se observa el recurso label_node_lob como salida y función (no se puede ver la información ya que la consulta genera muchas columnas, pero sí la detecta):
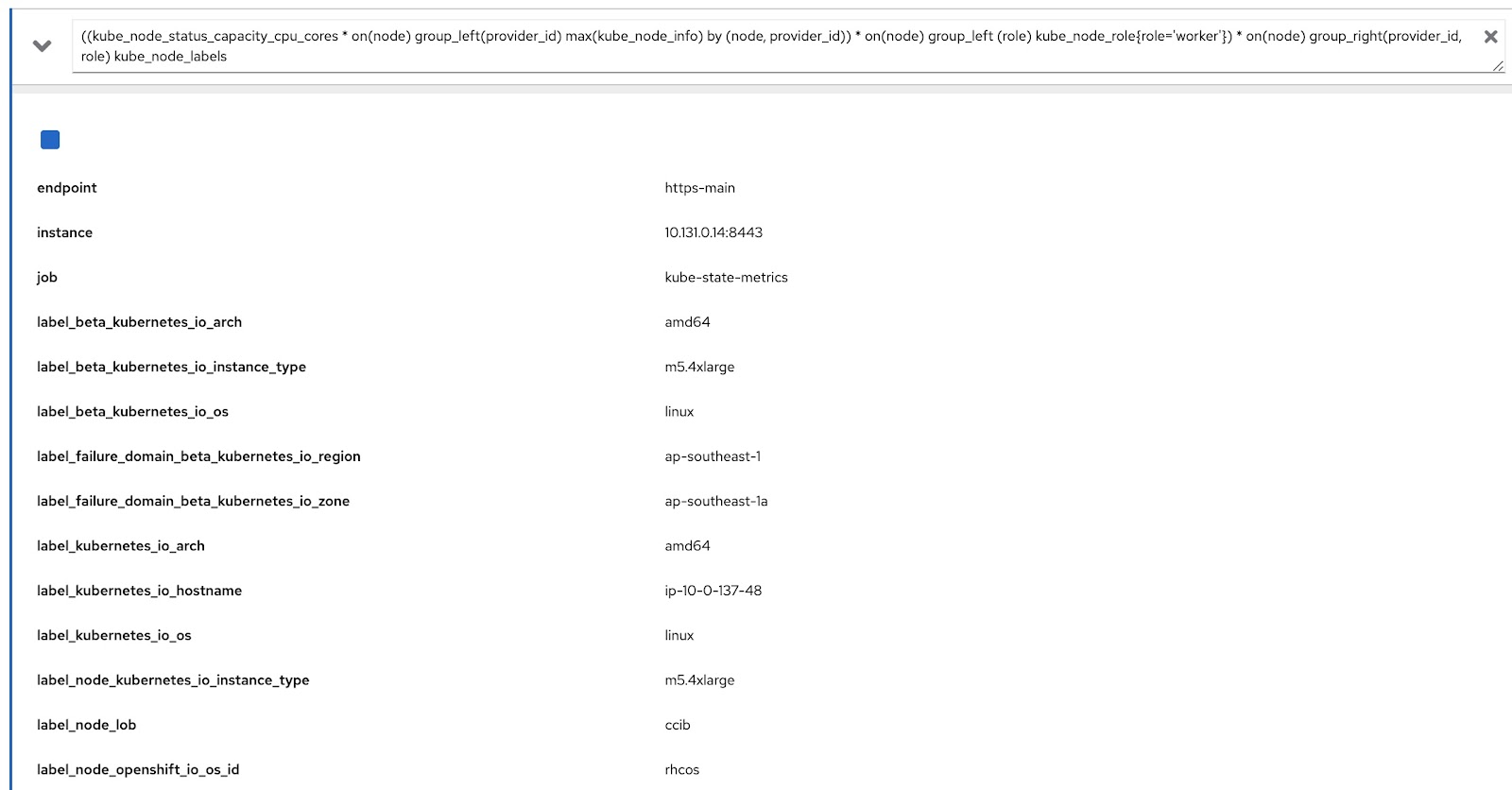
Entonces, escribiremos cuatro recursos personalizados. Para que la tarea sea más sencilla, puede verlos a continuación:
- rds-custom-node-capacity-cpu-cores.yaml: define la consulta de Prometheus.
- rq-custom-node-cpu-capacity-raw.yaml: hace referencia al rds anterior y calcula datos sin procesar.
- rds-custom-node-cpu-capacity-raw.yaml: hace referencia al rq anterior y crea una visualización en Presto.
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml: se refiere al rds que se mencionó en el punto anterior y calcula los datos en función de los de inicio y finalización de entrada. Además, este es el archivo con el cual recuperamos las columnas role y node_label.
Una vez que haya escrito estos archivos YAML, diríjase al proyecto openshift-metering y ejecute los siguientes comandos:
$ oc project openshift-metering $ oc create -f rds-custom-node-capacity-cpu-cores.yaml $ oc create -f rq-custom-node-cpu-capacity-raw.yaml $ oc create -f rds-custom-node-cpu-capacity-raw.yaml $ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml |
Por último, todo lo que queda por hacer es escribir un objeto Report personalizado que haga referencia al último objeto rq que creó con anterioridad. Puede hacerlo como se muestra a continuación. El informe se ejecutará de inmediato y mostrará los datos entre el 15 y el 30 de septiembre.
$ cat report_immediate.yaml apiVersion: metering.openshift.io/v1 kind: Report metadata: name: custom-role-node-cpu-capacity-lables-immediate namespace: openshift-metering spec: query: custom-role-node-cpu-capacity-labels reportingStart: "2020-09-15T00:00:00Z" reportingEnd: "2020-09-30T00:00:00Z" runImmediately: true
$ oc create -f report-immediate.yaml |
Una vez que ejecute el informe, podrá descargar el archivo (CSV o JSON) mediante esta URL (cambie el NOMBRE DE DOMINIO según corresponda):
En la siguiente instantánea de un archivo CSV, se muestran los datos registrados que incluyen las columnas role y node_lob. La columna "node_capacity_cpu_core_seconds" debe dividirse por "node_capacity_cpu_cores" para llegar al tiempo de ejecución del nodo en segundos:

Resumen
Operator Metering es una herramienta bastante eficiente y funciona en los clústeres de OpenShift, donde sea que se ejecute. Proporciona un marco con capacidad de expansión que permite que los clientes escriban sus propios recursos personalizados para crear informes según sus necesidades. Todo el código que se usó anteriormente está disponible aquí.
Sobre el autor

Más como éste
AI in telco – the catalyst for scaling digital business
Simplify Red Hat Enterprise Linux provisioning in image builder with new Red Hat Lightspeed security and management integrations
The Containers_Derby | Command Line Heroes
Crack the Cloud_Open | Command Line Heroes
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube