Red Hat OpenShift Container Platform (RHOCP) makes it easy for developers to deploy kubernetes-native solutions that can automatically handle apps' horizontal scaling needs, as well as many other types of management tasks, including provisioning and scaling.
Instead of statically allocating resources, developers can leverage Helm and kubernetes resources to automate this process. This will allow app teams to respond quickly to peaks in demand, and reduce costs (compute, man hours) by automatically scaling down when resources are no longer needed.
Pod-based horizontal scaling will be the main focus of this article. We will discuss the following:
- Scaling applications based on a schedule (Cron). For example scaling an app to 5 replicas at 0900; and then scaling it down to 1 pod at 2359.
- Scaling apps based on CPU/Memory utilization (HorizontalPodAutoscaler). For example scaling an app to 5 replicas when average CPU utilization is at or above 50%; and scaling it down to 1 Pod when it falls below range.
- Scaling apps based on custom metrics (Red Hat Custom Metrics Autoscaler Operator). For example, scaling an AMQ consumer app to 20 replicas when pending messages in a queue are greater than 500; and scaling it down when queue size falls below 500.
Helm helps you manage Kubernetes applications — Helm Charts help you define, install, and upgrade even the most complex Kubernetes application. Charts are easy to create, version, share, and publish. – Helm.sh
All of the different methods discussed are implemented using Helm to make it easy to templatize the kubernetes resources manifests; as well as to dynamically handle the need to have the same templates applied to multiple applications deployables by merely declaring app details in the helm values.yaml files.
To find out more about the benefits of Helm, follow this link.
To get the most out of this content, foundational understandings of Kubernetes and Helm are recommended.
Helm charts were tested on Red Hat OpenShift Container Platform (RHOCP 4.10+).
Method #1: Scaling applications pods based on a schedule
Overview
Schedule based scaling uses OpenShift/Kubernetes native resources called CronJob that execute a task periodically (date + time) written in Cron format. The scale-up-cronjob.yaml template handles patching the deployables to increase their pod replicas; while the scale-down-cronjob.yaml scales them down. Furthermore, the values.yaml is where details about apps and their scaling specs are declared. Each of these two CronJobs run an oc patch command as entrypoint command.
The CronJob schedule: "0 22 * * *" times are based on the time zone of the kube-controller-manager. Unless overridden by the Pod (Container Image or Pod Spec), you can find the kube-controller-manager time zone by creating a sample pod and running the date command in its terminal.
Implementation
The helm chart creates one scale up and scale down jobs for each app deployable.
The cronjob-scaler helm chart github repository is available at this location.
Pre-Requisites
- Access to an OpenShift/Kubernetes cluster
- Required level of access on the OpenShift cluster – Sample ServiceAccount provided in the chart
- Identification of the kube-controller-manager time zone
- Workstation with oc, helm binaries installed
Procedure
Identify namespace and deployables target for scheduled scaling
DepoymentConfigs, Deployments, StatefulSets are examples of scalable kubernetes objects.
Prepare the helm chart values.yaml file
Use this site to generate Cron formatted schedules.
To identify the kube-controller-manager timezone, run oc rsh ANY_POD_NAME> date.
scaleActions:
scaleUp:
# Provide input in Cron Format -- Must be in kube controller TZ
schedule: "0 3 * * *"
components:
- name: app1
resourceType: Deployment
replicas: 2
- name: app2
resourceType: Deployment
replicas: 2
- name: app3
resourceType: Deployment
replicas: 2
scaleDown:
# Provide input in Cron Format -- Must be in kube controller TZ
schedule: "0 5 * * *"
components:
- name: app1
resourceType: Deployment
replicas: 1
- name: app2
resourceType: Deployment
replicas: 1
- name: app3
resourceType: Deployment
replicas: 1
Install cronjob-scaler Helm Chart
helm uninstall cronjob-scaler || true
helm upgrade --install cronjob-scaler ./cronjob-scaler
sleep 30
Cleanup
helm uninstall cronjob-scaler
sleep 15
oc delete cronjob -l app=cronjob-scaler
Method #2: Scaling applications based on CPU/Memory
Overview
As a developer, you can use a horizontal pod autoscaler (HPA) to specify how OpenShift Container Platform should automatically increase or decrease the scale of a replication controller or deployment configuration, based on metrics collected from the pods that belong to that replication controller or deployment configuration. You can create an HPA for any deployment, deployment config, replica set, replication controller, or stateful set. -- OpenShift Docs
The following metrics are supported by horizontal pod autoscaler (HPA):
| Metric | Description | API Version |
| CPU Utilization | Number of CPU cores used. Can be used to calculate a percentage of the pod’s requested CPU. | autoscaling/v2beta2 |
| Memory Utilization | Amount of memory used. Can be used to calculate a percentage of the pod’s requested memory. | autoscaling/v2beta2 |
Implementation
The hpa-cpu-memory helm chart uses dynamic helm template features (ie: range, if else..etc) to enable a declarative approach to creating one HorizontalPodAutoscaler resource per target app; one HPA object per deployable. Therefore, all deployables in a namespace in need of an HPA can be managed in a single location by just providing apps scaling specs in the values.yaml file.
The hpa-cpu-memory-scaler helm chart github repository is available at this location.
Pre-Requisites
- Access to an OpenShift/Kubernetes cluster
- Permission to list, get, patch
HorizontalPodAutoscalerresources. - Workstation with oc, helm binaries installed
Procedure
Identify namespace and deployables target for HPA based scaling
DepoymentConfigs, Deployments, StatefulSets are examples of scalable kubernetes objects.
Prepare the helm chart values.yaml file
hpa:
targetCPUScalePercentage: 50
scaleDownStabilizationPeriodSeconds: 60
scaleUpStabilizationPeriodSeconds: 60
scaleTargets:
- name: loadtest
kind: Deployment
maxReplicas: 5
minReplicas: 1
- name: app1
kind: Deployment
maxReplicas: 2
minReplicas: 1
Deploy hpa-cpu-memory-scaler helm chart
helm uninstall hpa-cpu-memory-scaler || true
helm upgrade --install hpa-cpu-memory-scaler ./hpa-cpu-memory-scaler
sleep 30
Watch HorizontalPodAutoscaler in Action
The loadtest k8s Deployment in the chart is just an example. The curl command will make an API call causing the app CPU to spike.
curl http://$(oc get route/loadtest -n ${NAMESPACE} -ojsonpath={.spec.host})/api/loadtest/v1/cpu/3
watch oc get po
Cleanup
helm uninstall hpa-cpu-memory-scaler
sleep 15
oc delete all -l app=hpa-cpu-memory-scaler
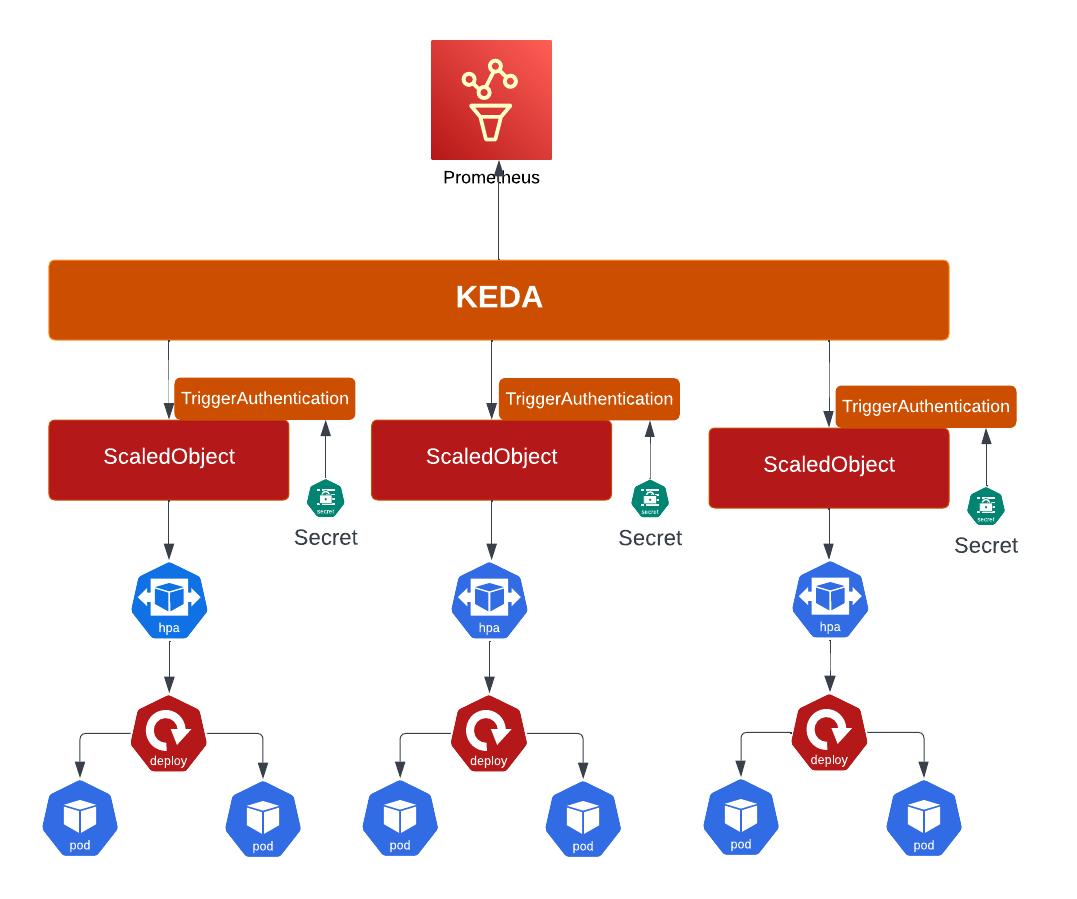
Method #3: Scaling applications based on custom metrics
Overview
As a developer, you can use the custom metrics autoscaler to specify how OpenShift Container Platform should automatically increase or decrease the number of pods for a deployment, stateful set, custom resource, or job based on custom metrics that are not just based on CPU or Memory.
Footnote, the custom metrics autoscaler currently (v2.7.1) supports only the Prometheus trigger, which can use the installed OpenShift Container Platform monitoring or an external Prometheus server as the metrics source.
At the time of writing this article, the Custom Metrics Autoscaler Operator is in Technology Preview.
Implementation
Multiple helm charts are put together to demo this solution. 50% are for setting up the AMQ installation while the other half are for KEDA deployment and configuration.
| Helm Chart | Description |
| amq-broker-operator | Deploys the AMQ Broker operator. It creates OperatorGroup, Subscription resources. |
| amq-broker-crs | Deploys the AMQ broker custom resources such as the actual broker node, and a queue. |
| amq-clients | When deployed, a producer for pushing messages and a consumer for pulling messages spin up; they both connect to the same queue. |
| rhocp-keda-operator | Deploys the Red Hat supported version of the KEDA operator. It creates OperatorGroup, Subscription resources. |
| rhocp-keda-controller | It creates a KedaController resource in the openshift-keda namespace. This resource helps with bootstrapping the operator autoscaling features. |
| rhocp-keda-crs | It deploys the app namespace CRs used for declaring app autoscaling specs. |
The custom metric chosen for this demo is artemis_message_count metric which is the number of messages currently in a given AMQ queue. This includes scheduled, paged, and in-delivery messages.
For a list of other supported Red Hat AMQ Broker metrics, follow this link.
The rhocp-keda-scaler helm chart github repository is available at this location.
Pre-Requisites
- Access to an OpenShift/Kubernetes cluster
- User need following permissions: edit, cluster-monitoring-edit, cluster-monitoring-view
- Permission to list, get, patch Subscriptions, OperatorGroups, InstallPlans resources
- Workstation with oc, helm binaries installed
Procedure
Take a look at each individual script in the shell-scripts/ directory to understand where and how each component is deployed. rhocp-keda-scaler/ will be used as the root directory throughout the steps that follow.
To deploy the entire solution with one command, run sh shell-scripts/install.sh. Likewise to cleanup all deployed resources, run sh shell-scripts/cleanup.sh.
Install AMQ Broker Operator, Custom Resources
sh ./shell-scripts/install-amq.sh
Deploy AMQ Clients -- Producer, Consumer
sh shell-scripts/install-amq-clients.sh
Install Red Hat OpenShift Custom Metrics Operator
sh shell-scripts/install-keda-operator.sh
Deploy operator custom resources for apps autoscaling
These resources are deployed in the same namespace as our target apps.
sh shell-scripts/install-keda-crs.sh
Cleanup
To cleanup everything in one sweep, run sh shell-scripts/cleanup.sh. Otherwise execute the scripts in this order.
sh shell-scripts/cleanup-keda-crs.sh
sh shell-scripts/cleanup-keda-operator.sh
sh shell-scripts/cleanup-amq-clients.sh
sh shell-scripts/cleanup-amq.sh
Summary
In this article we’ve learned 3 different methods of natively automating horizontal pod autoscaling. The cronjob-scaler chart demonstrates how to scale apps using date & time, hpa-cpu-memory-scaler chart shows how to scale apps based on Pods CPU & Memory utilization; while the third option takes this a step further by scaling pods based on a Prometheus query results. We’ve also learned basic concepts of helm such as control flow loops (if else, range, when), helm variables, usage of builtin objects, named templates and template functions.
Sources
Products Docs and Articles
- https://docs.openshift.com/container-platform/4.10/welcome/index.html
- https://en.wikipedia.org/wiki/Cron
- https://docs.openshift.com/container-platform/4.10/nodes/pods/nodes-pods-autoscaling.html
- https://docs.openshift.com/container-platform/4.10/nodes/pods/nodes-pods-autoscaling-custom.html
- https://docs.openshift.com/container-platform/4.10/nodes/jobs/nodes-nodes-jobs.html#nodes-nodes-jobs-about_nodes-nodes-jobs
- https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/
- https://crontab.guru/
Apps Scaler Repositories
- cronjob-scaler: https://github.com/luqmanbarry/rhocp-3-ways-apps-autoscaling/tree/master/cronjob-scaler
- hpa-cpu-memory-scaler: https://github.com/luqmanbarry/rhocp-3-ways-apps-autoscaling/tree/master/hpa-cpu-memory-scaler
- rhocp-keda-scaler: https://github.com/luqmanbarry/rhocp-3-ways-apps-autoscaling/tree/master/rhocp-keda-scaler
저자 소개

유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
AI의 다음 변곡점: 에이전트를 엔터프라이즈 슈퍼유저로 전환
Technically Speaking | Taming AI agents with observability
Scaling For Complexity With Container Adoption | Code Comments
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래