
Red Hat OpenShift Virtualization 4.19는 데이터베이스와 같이 I/O 집약적인 워크로드의 성능과 속도를 크게 개선합니다. Multiple IOThreads for Red Hat OpenShift Virtualization은 가상 머신(VM) 디스크 I/O가 호스트의 여러 작업자 스레드에 분산되도록 하여 이러한 작업자 스레드가 VM 내부의 디스크 대기열에 매핑될 수 있는 새로운 기능입니다. 이를 통해 VM은 멀티스트림 I/O에 vCPU와 호스트 CPU를 모두 효율적으로 사용하여 성능을 개선할 수 있습니다.
이 문서는 제 동료인 Jenifer Abrams가 작성한 기능 소개의 후속 문서로, I/O 처리량 개선을 위해 VM을 튜닝하는 데 도움을 드리고자 성능 결과를 제공합니다.
테스트를 위해 Linux VM에서 fio를 합성 I/O 워크로드로 사용했습니다. 현재 애플리케이션과 Microsoft Windows에서 테스트하기 위한 다른 작업도 진행 중입니다.
KVM에서 이 기능을 구현하는 방법에 대한 자세한 내용은 IOThread Virtqueue Mapping에 대한 문서와 Red Hat Enterprise Linux(RHEL) 환경에서 실행되는 VM의 데이터베이스 워크로드 성능 개선을 입증하는 보조 문서를 참조하세요.
테스트 설명
다음과 같은 두 가지 구성에서 I/O 처리량을 테스트했습니다.
- 로컬 스토리지 오퍼레이터(Local Storage Operator, LSO)에서 프로비저닝한 논리 볼륨 관리자를 사용하는 로컬 스토리지가 있는 클러스터
- OpenShift Data Foundation(ODF)을 사용하는 별도의 클러스터
이 두 구성은 매우 다르므로 비교할 수 없습니다.
테스트는 포드(기준)와 VM에서 진행되었습니다. VM에는 16개의 코어와 8GB의 RAM을 할당했습니다. 그리고 VM이 1개인 512GB의 테스트 파일과 VM이 2개인 256GB의 테스트 파일을 사용했습니다. 모든 테스트에서 직접 I/O를 사용했습니다. VM에는 블록 모드에서 ext4로 포맷된 퍼시스턴트 볼륨 클레임(PVC)을 사용했고 포드에는 마찬가지로 ext4로 포맷된 파일 시스템 모드 PVC를 사용했습니다. 모든 테스트는 libaio I/O 엔진을 사용하여 실행했습니다.
다음 매트릭스를 테스트했습니다.
매개 변수 | 설정 |
스토리지 볼륨 유형 | 로컬(LSO), ODF |
포드/VM 수 | 1, 2 |
I/O 스레드 수(VM만 해당) | 없음(기준), 1, 2, 3, 4, 6, 8, 12, 16 |
I/O 오퍼레이션 | 순차 및 랜덤 읽기/쓰기 |
I/O 블록 크기(바이트) | 2K, 4K, 32K, 1M |
동시 작업 | 1, 4, 16 |
I/O iodepth(iodepth) | 1, 4, 16 |
ClusterBuster를 사용하여 테스트를 오케스트레이션했습니다. VM은 CentOS Stream 9를 사용했으며, 포드도 CentOS Stream을 컨테이너 이미지 기반으로 사용했습니다.
로컬 스토리지
로컬 스토리지 클러스터는 Dell R740xd 노드로 구성된 5노드(마스터 3개 + 작업자 2개) 클러스터로, 2개의 Intel Xeon Gold 6130 CPU를 포함했으며 각각 코어 16개와 스레드 2개(CPU 32개)로 구성되어 총 코어는 32개, 총 CPU는 64개였습니다. 각 노드에는 192GB RAM이 포함되었습니다. I/O 하위 시스템은 기본 설정된 RAID0 스트라이핑 멀티플 디바이스(MD) 구성으로 구성된 Dell 브랜드의 Kioxya CM6 MU 1.6TB NVMe 드라이브 4개로 구성되었습니다. 퍼시스턴트 볼륨 클레임은 lvmcluster 오퍼레이터를 사용하여 이 MD에서 생성되었습니다. 아쉽게도 이 정도의 소박한 구성이 최선이었습니다. 더 빠른 I/O 시스템을 사용하면 멀티플 I/O 스레드를 통해 훨씬 더 높은 개선 효과를 볼 가능성이 매우 높습니다.
OpenShift Data Foundation
OpenShift Data Foundation(ODF) 클러스터는 Dell PowerEdge R7625 노드로 구성된 6노드(마스터 3개 + 작업자 3개) 클러스터로, 2개의 AMD EPYC 9534 CPU를 포함했으며 각각 코어 64개와 스레드 2개(CPU 128개)로 구성되어 총 코어는 128개, 총 CPU는 256개였습니다. 각 노드에는 512GB의 RAM이 포함됩니다. I/O 하위 시스템은 노드당 2개의 5.8TB NVMe 드라이브로 구성되었으며 25GbE 기본 포드 네트워크를 통해 3방향 복제가 가능했습니다. 이 테스트에서는 더 빠른 네트워크에 액세스할 수는 없었지만 최신 네트워크 하드웨어를 사용하면 성능이 더 개선되었을 것입니다.
결과 요약
이 테스트에서는 특정 I/O 백엔드가 있는 멀티플 I/O 스레드를 평가하며, 이는 전형적인 활용 사례와는 다를 수 있습니다. 스토리지 특성의 차이는 I/O 스레드 수 선택에 큰 영향을 미칠 수 있습니다.
다음은 테스트 결과입니다.
- 최대 I/O 처리량: 로컬 스토리지의 경우 최대 처리량은 로컬 스토리지의 작업 수 또는 iodepth에 관계없이 포드와 VM 모두에서 읽기 약 7.3GB/초, 쓰기 약 6.7GB초였습니다. 이는 하드웨어에서 기대할 수 있는 것보다 훨씬 낮은 결과입니다. 장치(각각 4x PCIe gen4)는 읽기 6.9GB/초, 쓰기 4.2MB/초로 측정되었습니다. 그 원인을 조사하지는 않았지만 테스트에는 오래된 하드웨어가 사용되었습니다. 최고 성능은 단일 드라이브 성능보다 확실히 더 우수하므로 스트라이핑이 효과가 있었음을 알 수 있습니다. ODF의 경우 읽기 5GB/초, 쓰기 2GB/초가 최고 성적이었습니다.
- 대규모 블록 I/O(1MB)는 시스템에서 이미 성능을 제한했기 때문에 거의 개선되지 않았습니다.
- I/O 스레드 수에 대한 최적의 선택은 워크로드와 스토리지 특성에 따라 다릅니다. 예상대로 I/O 동시성이 크지 않은 워크로드는 이점이 거의 없었습니다.
- 로컬 스토리지: I/O 동시성이 큰 VM의 경우 일반적으로 4~8에서 시작하면 좋습니다. 특히 I/O 크기가 작고 동시성이 큰 워크로드의 경우 스레드 수가 많을수록 결과가 좋을 수 있습니다.
- ODF: 2개 이상의 I/O 스레드는 큰 이점이 없었으며, 대부분의 경우 전혀 필요하지 않았습니다. 이는 포드 네트워크가 비교적 느리기 때문일 수 있습니다. 네트워킹 속도가 더 빠르면 결과가 다를 가능성이 큽니다.
- 적어도 이 테스트에서는 멀티플 I/O 스레드가 심층적인 비동기식 I/O인 경우보다 동시 작업이 여럿일 때 개선된 결과를 제공하는 데 더 효과적이었습니다.
- 기반 총 최대 I/O 처리량(위에서 언급)에 도달할 때까지 1개와 2개의 동시 VM 간에 동작에는 거의 차이가 없었습니다.
- 멀티플 I/O 스레드는 작업 수가 더 적거나 I/O iodepth가 낮을 때 포드와의 격차를 완전히 좁히지 못했습니다. I/O iodepth가 높은 소규모 오퍼레이션의 경우 VM은 실제로 쓰기 오퍼레이션에서 상당한 차이로 포드보다 성능이 뛰어났습니다.
수치로 알아보기
다음은 로컬 스토리지 기반 시스템에서 멀티플 I/O 스레드를 사용할 때의 전체 I/O 처리량입니다. 보시다시피, I/O 크기가 더 작고 빠른 I/O 시스템과의 병렬 처리가 많은 워크로드의 경우가 훨씬 유리할 수 있습니다. I/O 스레드 수를 다양하게 했을 때의 개선된 결과에 대한 더 다양한 조사 결과를 아래에서 참고하세요. 성능이 이미 기반 시스템 제한에 매우 근접했기 때문에 1MB 블록 크기에서는 약간의 개선만 관찰되었습니다. 훨씬 더 빠른 하드웨어를 사용하면 I/O 스레드를 추가했을 때 블록 크기가 큰 경우에도 결과를 개선할 수 있습니다.
I/O 스레드를 추가했을 때 VM 기준 대비 최대 개선 효과 | ||||||||||
(로컬 스토리지) | 작업 | iodepth | ||||||||
1 | 4 | 16 | ||||||||
size | op | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 18% | 31% | 30% | 30% | 103% | 192% | 151% | 432% | 494% |
randwrite | 81% | 59% | 24% | 153% | 199% | 187% | 458% | 433% | 353% | |
read | 67% | 58% | 25% | 64% | 71% | 103% | 252% | 241% | 287% | |
write | 103% | 64% | 0% | 143% | 99% | 84% | 410% | 250% | 203% | |
총계 2048 | 67% | 53% | 20% | 97% | 118% | 141% | 318% | 339% | 334% | |
4096 | randread | 18% | 34% | 28% | 33% | 101% | 208% | 156% | 432% | 492% |
randwrite | 95% | 69% | 20% | 149% | 200% | 187% | 471% | 543% | 481% | |
read | 26% | 53% | 27% | 24% | 46% | 66% | 142% | 155% | 165% | |
write | 103% | 69% | 0% | 144% | 86% | 48% | 438% | 256% | 161% | |
총계 4096 | 60% | 56% | 19% | 87% | 108% | 127% | 302% | 346% | 325% | |
32768 | randread | 16% | 23% | 26% | 23% | 71% | 124% | 99% | 160% | 129% |
randwrite | 75% | 71% | 28% | 108% | 132% | 116% | 203% | 123% | 115% | |
read | 21% | 57% | 25% | 21% | 42% | 32% | 77% | 54% | 32% | |
write | 79% | 64% | 26% | 104% | 59% | 24% | 195% | 45% | 27% | |
총계 32768 | 48% | 53% | 26% | 64% | 76% | 74% | 143% | 96% | 76% | |
1048576 | randread | 5% | 2% | 0% | 9% | 0% | 0% | 17% | 0% | 0% |
randwrite | 10% | 0% | 1% | 6% | 0% | 2% | 9% | 0% | 2% | |
read | 12% | 18% | 0% | 9% | 0% | 0% | 16% | 0% | 0% | |
write | 19% | 0% | 0% | 7% | 0% | 0% | 9% | 0% | 0% | |
총계 1048576 | 11% | 5% | 0% | 8% | 0% | 1% | 13% | 0% | 0% | |
다음은 최대 16개의 I/O 스레드로 얻을 수 있는 최상의 결과의 90%를 달성하는 데 필요한 I/O 스레드 수입니다. 예를 들어 오퍼레이션, 블록 크기, 작업, iodepth의 특정 조합을 사용하여 테스트에서 달성한 최상의 결과가 1GB/초였다면, 여기서 메트릭은 900MB/초를 달성하는 데 필요한 최소 스레드 수가 될 것입니다. 이렇게 하면 스레드 수를 낮게 설정하면서 양호한 성능을 유지할 수 있습니다.
최고 성능의 90%를 달성하기 위한 최소 iothread 수 | ||||||||||
(로컬 스토리지) | 작업 | iodepth | ||||||||
1 | 4 | 16 | ||||||||
크기 | op | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
write | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
총계 2048 | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4096 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
write | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
총계 4096 | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32768 | randread | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
randwrite | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
read | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
write | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
총계 32768 | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1048576 | randread | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
randwrite | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
read | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
write | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
총계 1048576 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
상세 결과
측정된 각 테스트 사례에 대해 다음과 같은 성능 지수를 계산했습니다.
- I/O 처리량 측정
- 최상의 VM 성능(직접 보고하지 않음)
- 최상의 VM 성능의 90%를 달성하기 위한 최소 iothread 수
- 최상의 VM 성능과 포드 성능의 비율
- 기준 VM 성능 대비 최상의 VM 성능 개선율
최상의 성능을 위한 스레드 수는 보고하지 않겠습니다. 대부분의 경우 그 차이가 I/O 성능 보고 시 나타나는 일반적인 편차에도 못 미칠 정도로 매우 작았기 때문입니다.
특성이 매우 다른 로컬 스토리지와 ODF에 대한 결과 요약은 별도로 제공합니다.
아래의 모든 성능 그래프는 포드(포드), I/O 스레드가 없는 기준 VM(0), X축의 지정된 I/O 스레드 수에 대한 결과를 보여줍니다.
로컬 스토리지
기본 성능을 살펴보면 적어도 몇몇 경우에는 멀티플 I/O 스레드를 사용하는 것이 상당한 이점을 제공한다는 것을 알 수 있습니다. 예를 들어 작업이 16개이고 iodepth가 1인 비동기 I/O이며 로컬 스토리지인 경우 I/O 스레드를 추가적으로 사용하면 다음과 같이 몇 배 더 나은 개선 효과를 볼 수 있습니다.
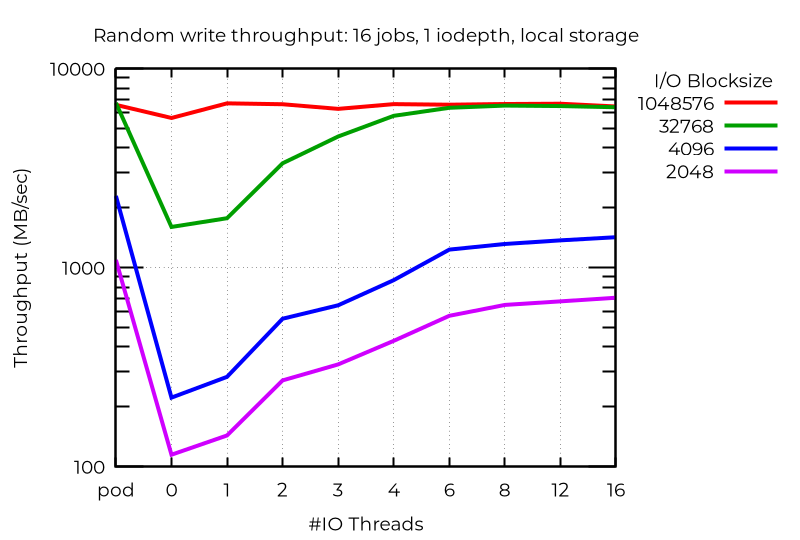
단일 스트림 I/O를 사용하는 경우에도 추가 I/O 스레드를 사용하는 것이 유리할 수 있습니다. 당연히 두 개 이상은 도움이 되지 않습니다.

추가 I/O 스레드로 인해 실제로 성능이 저하되는 비정상적인 경우가 있습니다. 이 경우 블록이 작은 심층 비동기식 I/O를 사용하면 전용 I/O 스레드를 사용하지 않는 VM에서 실제로 최상의 성능(포드보다 우수)을 얻을 수 있습니다. 아직까지는 왜 이러한 현상이 발생하는지 알 수 없습니다.
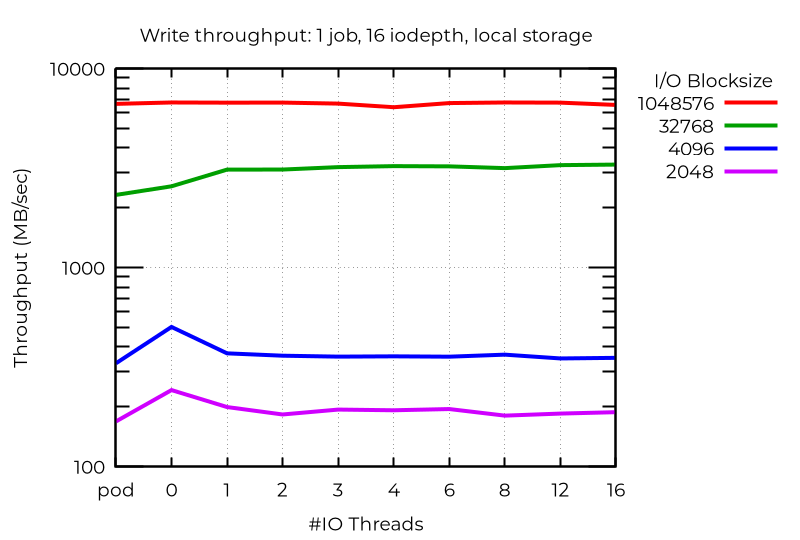
이러한 모든 결과를 통해 멀티플 I/O 스레드에서 최상의 성능을 얻으려면 특정 워크로드를 실험해야 한다는 것을 알 수 있습니다.
ODF 클러스터 결과
멀티플 I/O 스레드를 사용했을 때 소규모 블록 랜덤 쓰기가 크게 개선된 로컬 스토리지와 달리 ODF에서는 작업 수가 많은 경우에도 개선이 미미한 것으로 나타났습니다. 네트워킹 속도가 빠르거나 대기 시간이 짧을수록 결과가 더 좋을 가능성이 높습니다. 읽기 오퍼레이션, 특히 랜덤 읽기의 경우 약간의 효과가 나타났지만 쓰기와 더 적은 작업 수에서는 효과가 거의 보이지 않았습니다.
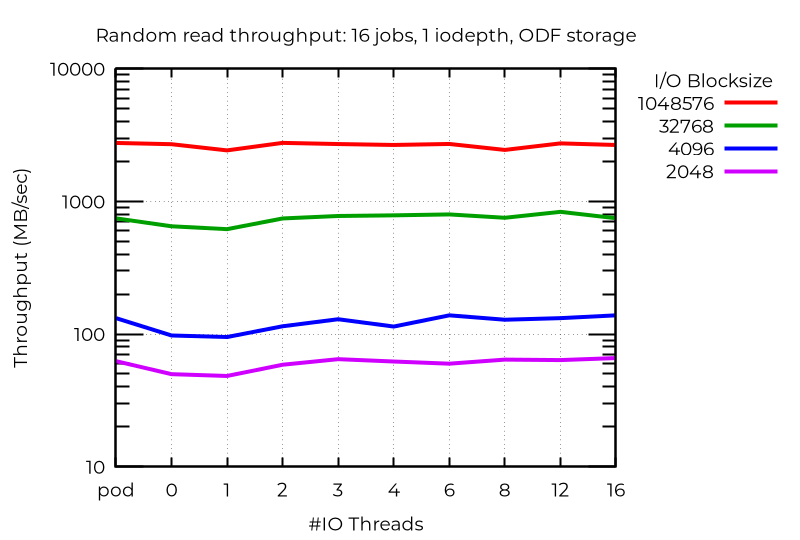
결론
OpenShift 4.19에 새롭게 도입되어 기대가 되고 있는 OpenShift Virtualization의 멀티플 I/O 스레드 기능은 동시 I/O가 있는 워크로드의 성능을 크게 개선할 수 있는 가능성을 제공합니다. 이번 테스트에서 사용된 로컬 NVMe 스토리지와 같은 빠른 I/O 시스템의 예가 그러합니다. 기반 베어 메탈 I/O를 완전히 구동하려면 더 많은 CPU가 필요하기 때문에 더 빠른 I/O 하위 시스템은 멀티플 I/O 스레드를 최대한 활용할 것으로 예상됩니다. I/O와 마찬가지로 I/O 시스템과 전체 워크로드의 차이는 성능에 큰 영향을 미칠 수 있습니다. 따라서 이 새로운 기능을 최대한 활용하기 위해 자체 워크로드를 테스트하는 것이 좋습니다. 이번 테스트 결과가 I/O 스레드를 알맞게 선택하는 데 도움이 되기를 바랍니다.
제품 체험판
Red Hat OpenShift Virtualization Engine | 제품 체험판
저자 소개
유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
OpenShift Virtualization 알아보기: 시작하는 데 도움이 되는 7가지 학습 리소스
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래