

서문
Red Hat OpenShift의 가상 머신(VM)에 대한 재해 복구(DR) 전략은 예기치 않은 운영 중단 시 비즈니스 연속성을 유지하는 데 필수적입니다. 조직이 중요 워크로드를 쿠버네티스 플랫폼으로 마이그레이션함에 따라 이러한 워크로드를 빠르고 안정적으로 복구하는 능력은 필수적인 운영 요구 사항이 되었습니다.
임시 스테이트리스(stateless) VM이 클라우드 네이티브 환경에서 보편화되었지만 대부분의 엔터프라이즈 VM 워크로드는 스테이트풀(Stateful)로 유지됩니다. 이러한 VM에는 다시 시작 또는 마이그레이션 중에 다시 연결할 수 있는 퍼시스턴트 블록 스토리지가 필요합니다. 결과적으로 스테이트풀 VM을 위한 DR은 일반적으로 스테이트리스 컨테이너 기반 애플리케이션에 중점을 둔 이전의 쿠버네티스 DR 패턴(Spizzoli, 2024)에서 다룬 문제와는 매우 다른 과제를 수반합니다.
이 블로그 포스트에서는 스테이트풀 VM의 고유한 요구 사항을 다룹니다. 먼저 클러스터 및 스토리지 아키텍처 선택이 페일오버 실현 가능성, 복제 동작, RPO/RTO 목표에 어떤 영향을 미치는지 살펴봅니다. 그런 다음 Red Hat Advanced Cluster Management, Helm, Kustomize 및 GitOps 파이프라인과 같은 쿠버네티스 네이티브 툴링이 워크로드 배치 및 복구를 제어하는 방식을 보여주는 오케스트레이션 계층을 자세히 살펴봅니다. 마지막으로, 블록 스토리지와 쿠버네티스 매니페스트를 둘 다 복제하는 고급 스토리지 플랫폼이 복구 프로세스를 간소화하고 애플리케이션 수준 자동화를 통해 인프라를 연결하는 방법을 살펴봅니다.
보편적인 용어 정의
본론으로 들어가기 전에 몇 가지 중요한 용어를 정의해 보겠습니다.
재해:
여기에서 '재해'라는 용어는 '사이트 접속 불가'를 의미합니다. DR은 어느 경우든 비즈니스 서비스 중단을 최소화하는 것입니다. 따라서 사이트에 접속할 수 없는 경우 가능한 한 신속하고 효율적으로 대체 사이트에서 서비스를 복원하기 위한 DR 계획을 구현해야 합니다.
참고: 사이트에 접속할 수 없는 경우에만 DR 계획을 수립하는 것이 아니라 주요 구성 요소에 장애가 발생하여 해당 구성 요소를 복원하는 동안 개별 비즈니스 서비스를 대체 사이트로 이동해야 하는 경우 개별 비즈니스 서비스에 대한 DR 계획을 수립하는 것이 일반적입니다.
구성 요소 장애:
구성 요소 장애는 조직의 일부 비즈니스 애플리케이션에 영향을 미치는 하나 이상의 하위 시스템 장애입니다. 이 장애 모드에서는 기본 사이트의 대체 시스템으로 처리를 전환해야 합니다. 또는 비즈니스 애플리케이션의 처리를 보조 사이트로 전환하기 위해 개별 DR 계획을 수립해야 할 수 있습니다.
복구 지점 목표(Recovery point objective, RPO):
RPO는 재해 또는 장애 이벤트에서 복구된 후 조직이 허용할 수 있는 수준을 넘어선 데이터 손실이 발생하기 전에 손실이 허용되는 최대 데이터 양(시간으로 측정됨)으로 정의됩니다.
복구 시간 목표(Recovery Time Objective, RTO):
RTO는 조직에서 최대한으로 허용할 수 있는 서비스 이용 불가 시간으로 정의됩니다. 다양한 아키텍처 선택이 RTO에 영향을 미치겠지만, 이러한 고려 사항은 이 블로그 포스트에서 자세히 다루지 않습니다.
메트로 DR과 지역 DR:
DR은 메트로 DR과 지역 DR이라는 두 가지 유형으로 구분됩니다.
- 메트로 DR은 데이터센터가 충분히 가까운 곳에 있고 네트워크 성능이 동기식 데이터 복제를 허용하는 상황에 적합합니다. 동기식 복제는 데이터 손실이 발생하지 않아 RPO 0을 달성할 수 있다는 장점이 있습니다.
- 지역 DR은 데이터센터가 너무 멀리 떨어져 있어 동기식 복제를 지원할 수 없어서 비동기식 복제를 사용해야 하는 상황에 적합합니다. 비동기식 복제에서는 데이터 손실이 발생할 것이 거의 확실합니다. 이 블로그 포스트의 작성 취지에서는 손실되는 데이터 양은 중요하지 않습니다.
참고: 스토리지 인프라가 동기식 복제를 지원하지 않는 경우 메트로 DR에 지역 DR 아키텍처가 사용됩니다.
너무 많은 다시 시작으로 인한 과부하(Restart storm):
'다시 시작 과부하'는 동시에 다시 시작하려는 VM의 수가 너무 많아 하이퍼바이저와 지원 인프라가 이를 감당할 수 없어 VM을 다시 시작할 수 없거나 VM 다시 시작에 허용되는 것보다 훨씬 더 오랜 시간이 걸리는 경우 발생하는 이벤트입니다. 이는 비악성 서비스 거부(Denial of Service, DoS) 공격으로 설명될 수도 있습니다.
비즈니스 연속성에 대한 아키텍처 접근 방식
비즈니스 연속성과 DR을 실현하는 방법에는 여러 가지가 있습니다. 이 주제에 대한 일반적인 논의를 위해 먼저 클라우드 네이티브 컴퓨팅 재단(Cloud Native Computing Foundation, CNCF)의 Cloud Native Disaster Recovery for Stateful Workloads(스테이트풀 워크로드를 위한 클라우드 네이티브 재해 복구, Spizzoli, 2024) 백서를 읽어볼 것을 추천합니다. DR에 대한 전형적인 접근 방식은 일반적으로 다음 다이어그램과 같이 네 가지로 구분됩니다(각 접근 방식에 대한 자세한 설명은 백서 참조).
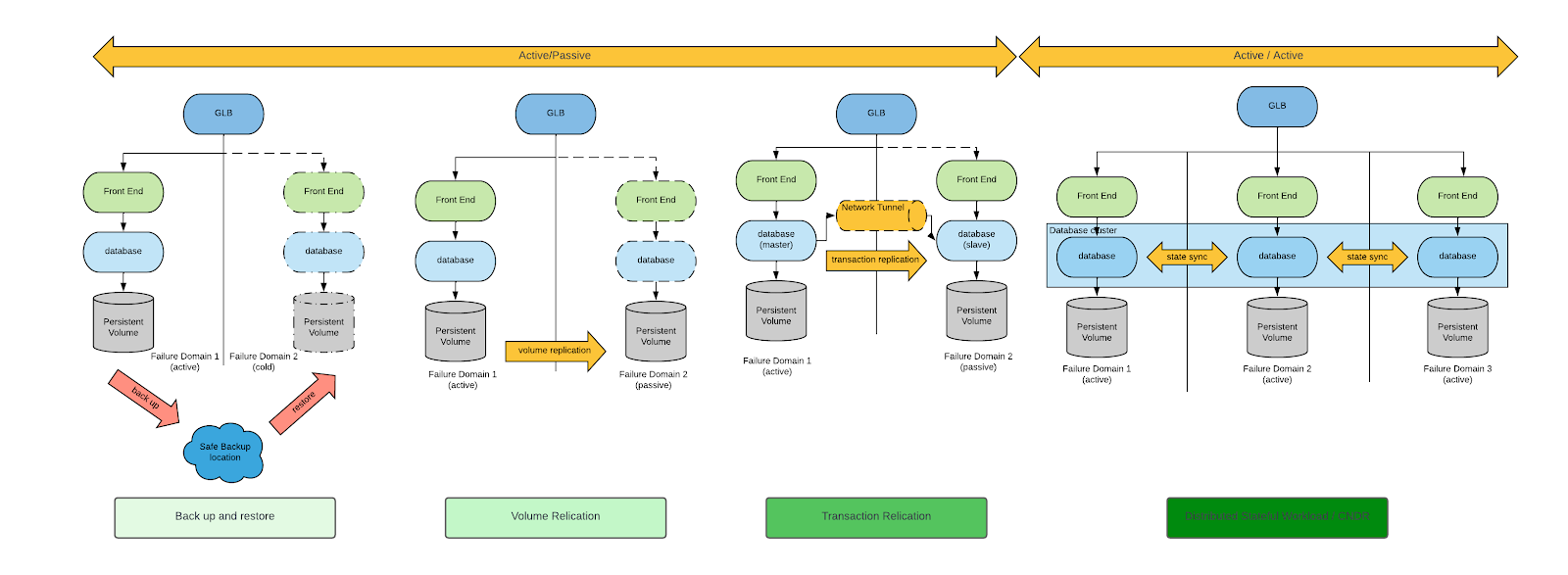
VM에 대한 DR 요구 사항을 고려할 때 적절한 DR 패턴은 백업 및 복원과 볼륨 복제뿐입니다.
백업 및 복원과 볼륨 복제는 모두 실행 가능한 접근 방식이지만, 볼륨 복제 기반 DR 접근 방식은 RPO와 RTO 둘 다 최소화합니다. 따라서 여기서는 볼륨 복제 기반 DR 접근 방식을 집중적으로 살펴봅니다.
분석 범위를 좁혀서 DR에 대한 두 가지 아키텍처 접근 방식에 대해 논의할 것입니다. 이는 볼륨 복제 유형에 따른 아키텍처로 구분됩니다.
- 단방향 복제
- 대칭 복제 또는 양방향 복제
단방향 복제
단방향 복제를 사용하면 볼륨이 하나의 데이터센터에서 다른 데이터센터로 복제되지만 그 반대 방향으로는 복제되지 않습니다. 복제 방향은 스토리지 어레이를 통해 제어되며 볼륨 복제는 동기식 또는 비동기식일 수 있습니다. 스토리지 어레이 기능과 두 데이터센터 간 대기 시간에 따라 두 복제 방식 중 하나를 선택하게 됩니다. 비동기식 복제는 서로 간의 대기 시간이 길고 동일한 지리적 지역 내에 있을 가능성이 높지만 동일한 대도시권에 속하지는 않는 데이터센터에 적합합니다.
아키텍처 측면에서 단방향 복제는 다음 그림과 유사합니다.
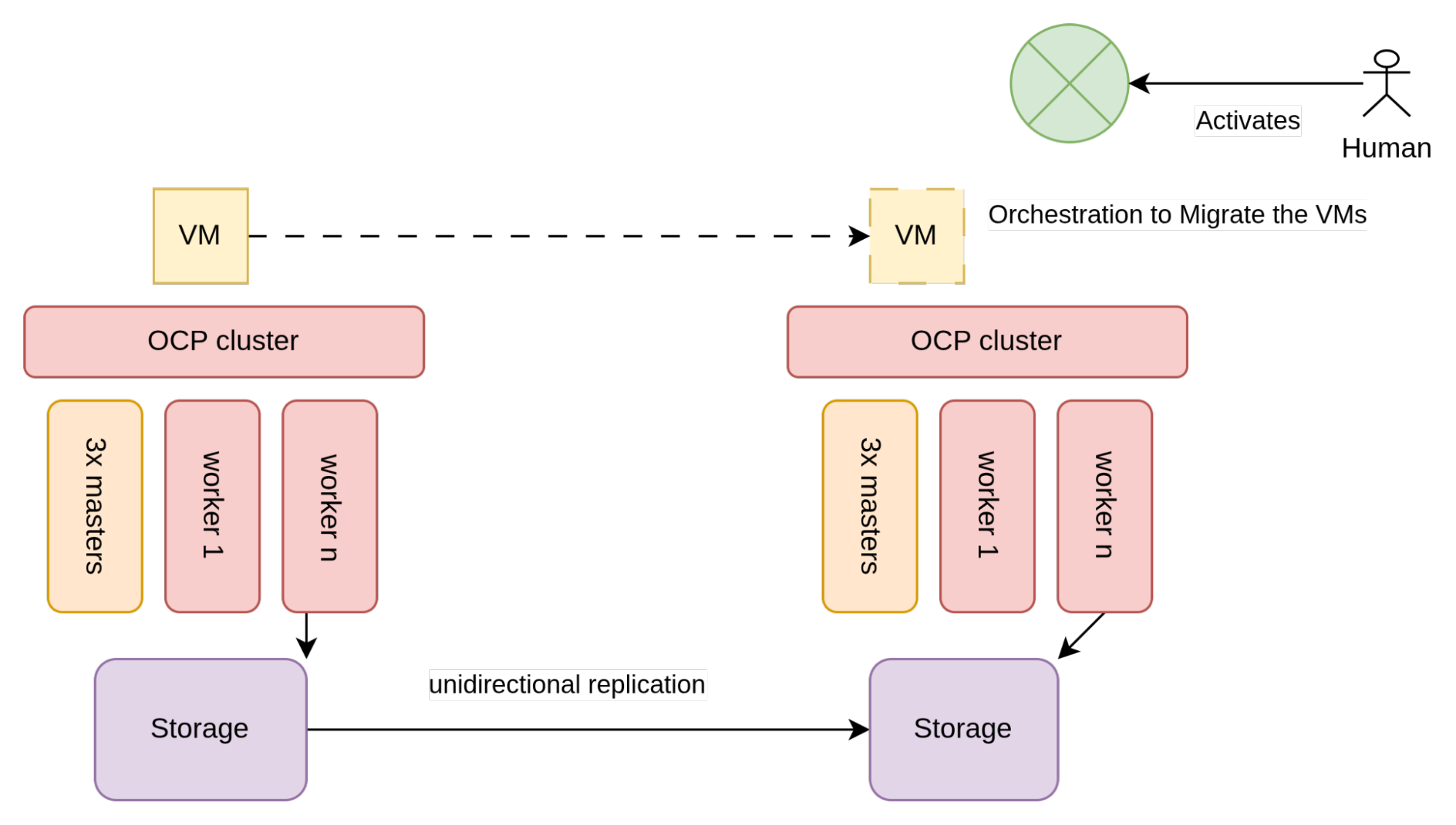
그림 2와 같이 VM(일반적으로 SAN 어레이)에서 사용하는 스토리지는 단방향 복제를 허용하도록 구성됩니다.
각 데이터센터에는 두 개의 서로 다른 OpenShift 클러스터가 있으며, 각각 로컬 스토리지 어레이에 연결되어 있습니다. 클러스터는 서로를 인식하지 못하므로 이 아키텍처를 구현하는 데 있어 유일한 제약 조건은 스토리지 벤더, 특히 단방향 복제를 사용하기 위해 충족해야 하는 요구 사항에 따라 달라집니다.
단방향 볼륨 복제의 고려 사항
볼륨 복제는 쿠버네티스 CSI 사양에서 표준화되어 있지 않습니다. 따라서 스토리지 벤더는 이 기능을 지원하기 위해 독자적인 사용자 정의 리소스 정의(CRD)를 개발했습니다. 일반적으로 이 기능을 제공하는 벤더의 성숙도는 3단계로 구분됩니다.
- CSI 수준에서 볼륨 복제 기능을 사용할 수 있거나, 스토리지 어레이 API를 직접 호출하지 않고는 적절한 DR 오케스트레이션을 생성할 수 없는 방식으로 제한적으로 사용 가능
- CSI 수준에서 볼륨 복제 기능 사용 가능
- 볼륨 복제 기능을 사용할 수 있으며 벤더도 네임스페이스 메타데이터(즉, 네임스페이스에 있는 VM 및 기타 매니페스트)의 복원을 관리함
이러한 다양한 성숙도 수준을 고려할 때 지역 DR 준비를 위해 벤더에 구애받지 않는 DR 복구 프로세스를 작성하는 것은 간단하지 않습니다. 적절한 DR 오케스트레이션을 생성하기 위해 작성해야 하는 양은 스토리지 벤더에 따라 다릅니다.
OpenShift 노드 장애, 스토리지 어레이 장애(구성 요소 장애), 전체 데이터센터 장애(실제 DR 시나리오) 등 다양한 장애 모드에서 이 아키텍처의 동작을 살펴보겠습니다.
OpenShift 노드 장애
노드(구성 요소)에 장애가 발생하는 경우 OpenShift Virtualization 스케줄러는 클러스터에서 다음으로 가장 적절한 노드에서 VM을 자동으로 다시 시작합니다. 이 시나리오에서는 추가 작업이 필요하지 않습니다.
스토리지 어레이 장애
스토리지 어레이에 장애가 발생하는 경우 해당 스토리지 어레이를 사용하는 모든 VM에서도 장애가 발생합니다. 이 시나리오에서는 DR 프로세스를 실행해야 합니다. (관련 단계는 '재해 복구 프로세스' 섹션을 참조하세요.)
데이터센터 장애
데이터센터에 장애가 발생하는 경우 DR 프로세스를 실행하여 장애의 영향을 받지 않는 데이터센터에서 모든 VM을 다시 시작해야 합니다. 자동화는 여기서 핵심적인 역할을 합니다. 그러나 프로세스는 일반적으로 주요 인시던트 관리 프레임워크 내에서 사람 담당자가 시작합니다. 다음 섹션에서 관련 단계를 전반적으로 살펴볼 수 있습니다.
재해 복구 프로세스
DR 절차는 매우 복잡할 수 있지만 요약하자면 DR 프로세스에서는 다음을 고려해야 합니다.
- 동일한 애플리케이션에 속한 VM은 일관된 방식으로 볼륨을 복제해야 합니다. 이는 일반적으로 해당 VM의 볼륨이 동일한 정합성 그룹에 포함되어 있음을 의미합니다.
- 정합성 그룹의 볼륨을 복제해야 하는지 여부와 복제 방향을 제어할 수 있어야 합니다. 정상적인 상황에서는 볼륨이 액티브 사이트에서 패시브 사이트로 복제됩니다. 페일오버 중에는 볼륨이 복제되지 않습니다. 페일백을 준비하는 동안 패시브 사이트에서 액티브 사이트로 볼륨이 복제됩니다. 페일백 중에는 볼륨이 복제되지 않습니다.
- 다른 데이터센터에서 VM을 다시 시작하고 복제된 스토리지 볼륨에 연결할 수 있어야 합니다.
- 다시 시작 과부하를 방지하기 위해 VM 다시 시작을 제한해야 할 수 있습니다. 또한 일반적으로 가장 중요한 애플리케이션이 먼저 시작되거나 데이터베이스와 같은 종속 구성 요소가 이를 사용하는 서비스보다 먼저 시작되도록 VM 다시 시작 시퀀스의 우선순위를 지정하는 것이 권장됩니다.
비용 고려 사항
OpenShift 클러스터가 구성된 방식에 따라 웜 또는 핫 DR 사이트로 간주될 수 있습니다. 핫 사이트는 전체 서브스크립션이 필요하지만 웜 사이트는 그렇지 않습니다(잠재적으로 일부 비용 절감 가능).
일반적으로 DR 사이트에서 실행 중인 활성 워크로드가 없으면 웜 사이트로 간주될 수 있습니다. 특히 퍼시스턴트 볼륨(PV), 퍼시스턴트 볼륨 클레임(PVC)은 물론, 재해 발생 시 시작될 준비가 되어 있으면서도 웜 사이트 지정을 유지하면서 실행되지 않는 VM까지 구성할 수 있습니다.
대칭 액티브/패시브
일반적으로 워크로드의 100%를 액티브 사이트에 두지는 않습니다. 대신, 조직은 운영 데이터센터와 보조 데이터센터 간에 워크로드를 최대 50:50의 비율로 분할하게 됩니다. 이는 재해 발생 시 모든 서비스가 동시에 중단되지 않도록 하기 위한 실용적인 접근 방식입니다. 또한 전반적인 복구 작업도 그에 따라 줄어듭니다.
운영 및 보조 데이터센터에 활성 VM을 분산할 때 각 데이터센터는 다른 데이터센터로 페일오버할 수 있도록 구성됩니다. 이러한 설정을 '대칭 액티브/패시브'라고도 합니다.
대칭 액티브/패시브는 OpenShift Virtualization 및 위에서 살펴본 아키텍처에서 작동합니다. 대칭 액티브/패시브를 사용하면 두 데이터센터가 모두 활성 상태로 간주되므로 모든 OpenShift 노드를 서브스크립션해야 합니다.
대칭 복제
대칭 복제를 사용하면 볼륨이 동기식으로, 양방향으로 복제됩니다. 결과적으로 두 데이터센터 모두 활성 볼륨을 보유할 수 있으며 해당 볼륨에 쓸 수 있습니다. 이를 위해서는 조직에 네트워크 대기 시간이 매우 짧은(예: 5ms 미만) 데이터센터 두 개가 있어야 합니다. 이는 일반적으로 두 데이터센터가 동일한 대도시권에 있는 경우 가능하므로 이 아키텍처를 메트로 DR이라고도 합니다. 이러한 상황에서는 다음 아키텍처를 사용할 수 있습니다.

이 아키텍처에서 VM에서 사용하는 스토리지(일반적으로 SAN 어레이)는 두 데이터센터 간에 대칭 복제를 수행하도록 구성됩니다.
그러면 두 데이터센터 간에 걸쳐 확장된 논리 스토리지 어레이가 생성됩니다. 대칭 복제를 사용하려면 네트워크 또는 사이트 장애 발생 시 '스플릿 브레인(split-brain)' 시나리오를 방지하기 위해 독립적인 중재자 역할을 하는 '감시 사이트'가 필요합니다.
감시 사이트는 쿼럼을 생성하고 단절된 스플릿 브레인 시나리오를 연결하는 데 사용되므로 두 개의 주요 데이터센터와 같이 (대기 시간 측면에서) 근접할 필요는 없습니다. 감시 사이트는 독립적인 가용 영역이어야 하고 애플리케이션 워크로드를 포함하지 않아야 하며 큰 용량을 필요로 하지 않지만, 데이터센터 운영 측면에서 다른 데이터센터와 동일한 서비스 품질(예: 물리/논리 보안, 전력 관리, 쿨링)을 유지해야 합니다.
스토리지가 데이터센터 간에 걸쳐 확장되면 OpenShift가 그 위에 확장됩니다. 고가용성 아키텍처에서 이를 구현하려면 OpenShift 컨트롤 플레인에 세 개의 가용 영역(사이트)이 필요합니다. 이는 쿠버네티스의 내부 etcd 데이터베이스에 신뢰할 수 있는 쿼럼을 유지 관리하기 위해 세 개 이상의 장애 도메인이 필요하기 때문입니다. 이는 일반적으로 컨트롤 플레인 노드 중 하나에 대한 스토리지 감시 사이트를 활용하여 구현됩니다.
대부분의 SAN(스토리지 영역 네트워크) 벤더는 스토리지 어레이에 대한 대칭 복제를 지원합니다. 그러나 모든 벤더가 CSI 수준에서 이러한 기능을 제공하는 것은 아닙니다. CSI 수준에서 대칭 복제를 지원하는 스토리지 벤더가 있고 필요한 전제 조건 및 구성이 충족되었다고 가정할 때, PVC가 생성되면 다중 경로 논리 유닛 번호(Logical Unit Number, LUN)가 프로비저닝됩니다. 이 LUN에는 두 데이터센터로 이동하는 경로가 포함되어 있으므로 모든 OpenShift 노드를 두 스토리지 어레이에 대한 연결을 활성화하도록 구성해야 합니다. 다중 경로 디바이스는 일반적으로 비대칭 논리 유닛 액세스(Asymmetric Logical Unit Access, ALUA) 구성(Pearson IT Certification, 2024) (즉, 액티브/패시브, 여기서 액티브 경로는 가장 가까운 어레이에 대한 경로임)으로 생성되거나 서로 다른 가중치를 가진 액티브/액티브 경로로 생성됩니다(이 경우 가장 가까운 어레이의 가중치가 높음).
일부 벤더는 광 채널 연결이 '균일'하지 않은 경우에도 이 아키텍처를 허용합니다. 즉, 한 사이트의 노드는 로컬 스토리지 어레이에만 연결할 수 있습니다. 이 경우 ALUA 구성은 물론 생성되지 않습니다.
이 클러스터 토폴로지는 구성 요소 장애와 재해로부터 보호하는 데 도움이 됩니다. 다양한 장애 모드에서 이 아키텍처의 동작을 살펴보겠습니다.
OpenShift 노드 장애
노드(구성 요소)에 장애가 발생하는 경우 OpenShift Virtualization 스케줄러는 클러스터에서 다음으로 가장 적절한 노드에서 VM을 자동으로 다시 시작합니다. 이 시나리오에서는 추가 작업이 필요하지 않습니다.
스토리지 어레이 장애
다중 경로 LUN은 두 스토리지 어레이 중 하나에서 장애가 발생하거나 유지 관리를 위해 오프라인 상태가 되는 경우 서비스 연속성을 제공하는 데 도움이 됩니다. 균일한 연결 시나리오에서는 다중 경로 LUN의 패시브 경로 또는 가중치가 낮은 경로를 사용하여 VM을 다른 어레이에 연결합니다. 이 장애는 VM에 대해 완전히 투명하므로 디스크 I/O 대기 시간이 약간 증가할 수 있습니다. 균일하지 않은 연결 시나리오에서는 VM을 연결된 노드로 마이그레이션해야 합니다.
데이터센터 장애
전체 데이터센터를 사용할 수 없게 되면 확장된 OpenShift는 이를 여러 노드에서 동시에 장애가 발생한 것으로 인식합니다. OpenShift는 OpenShift 노드 장애 섹션에 설명된 대로 VM을 다른 데이터센터 내의 노드에 스케줄링합니다.
워크로드를 마이그레이션할 수 있는 여유 공간이 충분하다고 가정한다면 모든 머신은 결국 다른 데이터센터에서 다시 시작됩니다. 다시 시작된 VM은 RPO가 정확히 0이며, RTO는 다음 시간의 합계입니다.
- OpenShift에서 노드가 준비되지 않은 상태에 있음을 인식하는 데 걸리는 시간
- 노드에 대한 펜싱 처리에 걸리는 시간
- VM을 다시 시작하는 데 걸리는 시간
- VM 부팅 프로세스를 완료하는 데 걸리는 시간
이 DR 메커니즘은 기본적으로 완전히 자율적이며 사람의 개입이 필요하지 않습니다. 이것이 항상 바람직한 것은 아닙니다. 다시 시작 과부하를 방지하기 위해, 다시 시작할 VM과 이 프로세스가 시작되는 시기를 제어하는 것이 바람직한 경우가 많습니다.
메트로 DR 고려 사항
다음은 이 접근 방식과 관련하여 고려해야 할 사항입니다.
- VM은 일반적으로 VLAN에 연결되므로 데이터센터 간에 유동적일 수 있으려면 VLAN도 메트로 데이터센터 간에 확장되어야 합니다. 이는 경우에 따라 바람직하지 않을 수 있습니다.
- 감시 사이트 관리 네트워크(OpenShift 노드 네트워크)는 메트로 데이터센터의 관리 네트워크와 동일한 L2 서브넷에 없는 경우가 많습니다.
- OpenShift 컨트롤 플레인과 스토리지 어레이 컨트롤 플레인이 두 개의 단일 장애 지점(SPOF)이기 때문에 이를 완전한 DR 솔루션으로 간주하지 않는 견해도 있습니다. 이 SPOF는 물리적 관점에서 볼 때 논리적인 의미에서 의도되었으며, 물론 중복성이 있습니다. 그러나 이론적으로는 OpenShift 또는 스토리지 어레이 중 하나에 대한 한 번의 잘못된 명령으로 전체 환경이 삭제될 수 있는 것이 사실입니다. 이러한 이유로 이 아키텍처는 가장 중요한 워크로드를 위해 더 전통적인 지역 DR 아키텍처에 데이지 체인 방식으로 연결되기도 합니다.
- DR 상황에서 OpenShift는 아무런 지시 없이도 재해의 영향을 받은 데이터센터의 모든 VM을 동시에 정상 데이터센터로 자동으로 다시 스케줄링합니다. 이로 인해 다시 시작 과부하라는 현상이 발생할 수 있습니다. 페일오버되는 애플리케이션과 해당 시기를 제어하여 이러한 위험을 완화할 수 있는 다양한 쿠버네티스 기능이 있습니다. 다시 시작 과부하의 개념은 이어지는 섹션에서 설명합니다.
비용 고려 사항
대칭 복제를 사용하는 경우 두 사이트 모두 하나의 액티브 OpenShift 클러스터에 속하므로 둘 다 완전히 할당되어야 합니다. 단방향 복제의 경우 각 사이트는 100% 오버프로비저닝되어 다른 사이트의 100% 페일오버를 허용해야 합니다.
결론
단방향 복제 아키텍처와 대칭 복제 아키텍처 중에서 무엇을 선택하는지에 따라 OpenShift Virtualization 기반의 전체 DR 전략이 결정됩니다. 각 모델에는 운영 복잡성, 인프라 비용, RPO/RTO 보장, 자동화 가능성 측면에서 고유한장단점이 있습니다. 이중 클러스터 설계를 선택하든 확장 클러스터 설계를 선택하든, 기반 아키텍처는 비즈니스 연속성 기대치 및 인프라 제약 조건에 부합해야 합니다. 이러한 기반을 구축한 후에 2부에서는 인프라에서 오케스트레이션으로 초점을 전환하여 스토리지를 넘어 재해 상황에서 VM을 배치, 다시 시작, 제어하는 방법을 살펴봅니다.
제품 체험판
Red Hat OpenShift Virtualization Engine | 제품 체험판
저자 소개
Bryon is a skilled infrastructure and software engineering specialist with deep expertise in AI/ML, Kubernetes, OpenShift, cloud-native architecture, and enterprise networking. With a strong background in storage technologies, infrastructure, and virtualisation, Bryon works across domains including system administration, AI model deployment, and platform engineering. He is proficient in C#, Golang and Python, experienced in container orchestration, and actively contributes to Red Hat-based solutions. Passionate about education and enablement, Bryon frequently develops technical workshops and training programs, particularly in AI/ML and DevOps. He is also a practising musician, blending his technical acumen with creative expression.
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
유사한 검색 결과
자동화 그 이상의 가치: AI 기반 보안 취약점 급증에 따라 기술 전문가의 지원이 필요한 이유
Red Hat Enterprise Linux, 양자 컴퓨팅 시대를 대비한 SSH 보안 역량 강화
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래