

특히 대규모 모델을 위한 최신 AI 학습 환경은 컴퓨팅 규모와 엄격한 데이터 개인 정보 보호를 동시에 요구합니다. 기존 머신 러닝(ML)은 학습 데이터를 중앙 집중화해야 하므로 데이터 개인 정보 보호, 보안 및 데이터 효율성/볼륨 측면에서 상당한 어려움이 있습니다.
이러한 문제는 멀티클라우드, 하이브리드 클라우드 및 엣지 환경의 이기종 글로벌 인프라에서 더욱 심화되므로 조직은 데이터 개인 정보 보호를 유지하면서 기존 분산 데이터 세트를 사용하여 모델을 학습해야 합니다.
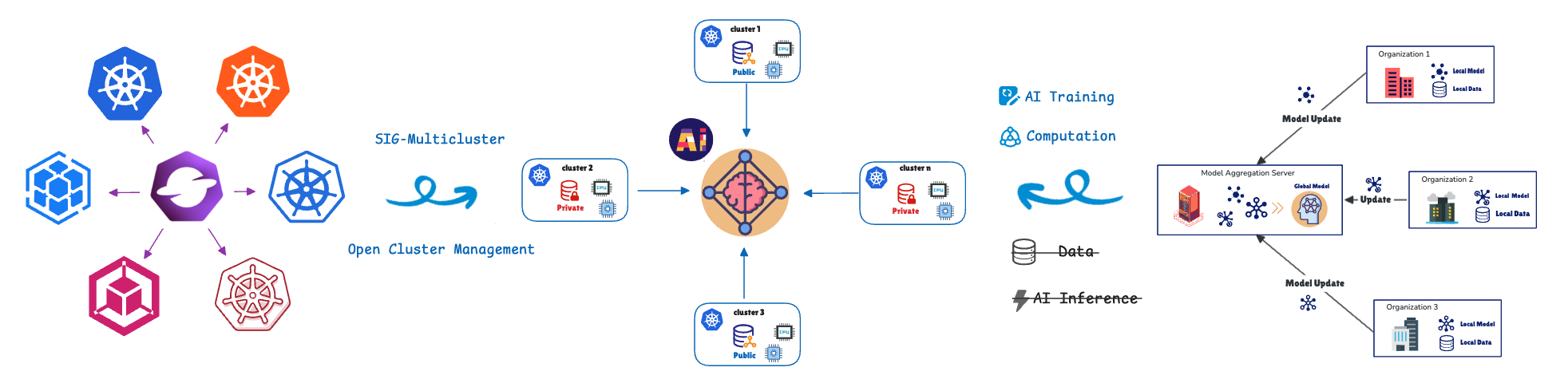
연합 학습(FL)은 모델 학습을 데이터 위치로 이동하여 이러한 문제를 해결합니다. 원격 클러스터 또는 장치(협력자/클라이언트)는 개인 데이터를 사용하여 로컬에서 모델을 학습하고 모델 업데이트(원시 데이터 제외)만 중앙 서버(집계기)로 다시 공유합니다. 이를 통해 엔드 투 엔드 데이터 개인 정보 보호가 가능합니다. 이러한 접근 방식은 첨단 운전자 보조 시스템(ADAS)과 차선 이탈 경고, 어댑티브 크루즈 컨트롤 및 운전자 피로 모니터링과 같은 자율 주행(AD) 기능이 있는 소프트웨어 정의 차량(SDV), 산업 자동화, 소매, 의료 분야에서 볼 수 있는 개인 정보 보호에 민감하거나 데이터 로드가 높은 시나리오에 매우 중요합니다.
이러한 분산 컴퓨팅 장치를 관리하고 오케스트레이션하기 위해 Red Hat은 Open Cluster Management(OCM)의 연합 학습 CRD(Custom Resource Definition)를 활용합니다.
OCM: 분산 운영의 기반
OCM은 쿠버네티스 멀티클러스터 오케스트레이션 플랫폼이자 오픈 소스 CNCF 샌드박스 프로젝트입니다.
OCM은 허브-스포크(hub-spoke) 아키텍처와 풀 기반(pull-based) 모델을 사용합니다.
- 허브 클러스터: 오케스트레이션을 담당하는 중앙 제어 플레인(OCM 제어 플레인) 역할을 수행합니다.
- 관리형(스포크) 클러스터: 워크로드가 배포되는 원격 클러스터입니다.
관리형 클러스터는 허브에서 원하는 상태를 가져오고 허브에 상태를 다시 보고합니다. OCM은 워크로드 예약을 위해 ManifestWork 및 Placement와 같은 API를 제공합니다. 다음에서 연합 학습(federated learning) API의 자세한 내용을 살펴보세요.
이제 OCM의 분산 클러스터 관리 설계가 FL 기여자 배포 및 관리 요구 사항과 어떻게 밀접하게 연관되는지 살펴보겠습니다.
네이티브 통합: FL 오케스트레이터로서의 OCM
1. 아키텍처 일치
OCM과 FL은 기본 구조가 일치하므로 효과적입니다. OCM은 허브-스포크 아키텍처와 풀 기반 프로토콜이라는 기본 설계가 FL과 동일하므로 FL을 기본적으로 지원합니다.

OCM 구성 요소 | FL 구성 요소 | 기능 |
OCM 허브 컨트롤 플레인 | 애그리게이터/서버 | 상태를 오케스트레이션하고 모델 업데이트를 집계합니다. |
관리형 클러스터 | 협업자/클라이언트 | 원하는 상태/글로벌 모델을 가져오고 로컬에서 학습하며 업데이트를 푸시합니다. |
2. 멀티 액터 클라이언트 선택을 위한 유연한 배치
OCM의 핵심적인 운영 이점은 유연한 클러스터 간 스케줄링 기능을 활용하여 FL 설정에서 클라이언트 선택을 자동화할 수 있다는 것입니다. 이 기능은 OCM Placement API를 사용하여 정교한 다중 기준 정책을 구현함으로써 효율성과 개인 정보 보호 규정 준수를 동시에 제공합니다.
Placement API를 통해 다음과 같은 요소를 기반으로 클라이언트를 통합적으로 선택할 수 있습니다.
- 데이터 로컬리티(개인 정보 보호 기준): FL 워크로드는 필요한 개인 데이터가 있다고 주장하는 관리형 클러스터에서만 예약됩니다.
- 리소스 최적화(효율성 기준): OCM 스케줄링 전략은 여러 요소를 결합하여 평가할 수 있는 유연한 정책을 제공합니다. 데이터 존재 유무뿐만 아니라 CPU/메모리 가용성과 같은 공지된 속성을 기반으로 클러스터를 선택합니다.
3. OCM 애드온 등록을 통한 협업자와 애그리게이터 간의 보안 통신
FL 애드온 협업자는 관리형 클러스터에 배포되며 OCM의 애드온 등록 메커니즘을 활용하여 허브의 애그리게이터와 보호되고 암호화된 통신을 설정합니다. 등록 시 각 협업자 애드온은 OCM 허브에서 인증서를 자동으로 가져옵니다. 이러한 인증서는 FL 중에 교환되는 모든 모델 업데이트를 인증 및 암호화하여 여러 클러스터에서 기밀성, 무결성 및 개인 정보 보호를 보장합니다.
이 프로세스는 적절한 리소스가 있는 클러스터에만 AI 학습 작업을 효율적으로 할당하여 데이터 로컬리티와 리소스 용량에 따라 통합된 클라이언트 선택을 제공합니다.
FL 학습 라이프사이클: OCM 기반 스케줄링
여러 클러스터에서 FL의 학습 라이프사이클을 관리하기 위해 전용 Federated Learning Controller가 개발되었습니다. 이 컨트롤러는 CRD를 사용하여 워크플로를 정의하고 Flower 및 OpenFL과 같은 널리 사용되는 FL 런타임을 지원하며 확장 가능합니다.


OCM 관리 워크플로는 정의된 단계를 거칩니다.
단계 | OCM/FL 단계 | 설명 |
0 | 필수 조건 | 연합 학습 애드온이 설치되어 있습니다. FL 애플리케이션은 쿠버네티스 배포 가능 컨테이너로 사용할 수 있습니다. |
1 | FederatedLearning CR | 허브에 사용자 정의 리소스가 생성되어 프레임워크(예: Flower), 학습 라운드 수(각 라운드는 클라이언트가 로컬에서 학습하고 집계를 위해 업데이트를 반환하는 전체 주기 1회), 필요한 사용 가능한 학습 기여자 수 및 모델 스토리지 구성(예: PersistentVolumeClaim(PVC) 경로 지정)을 정의합니다. |
2, 3, 4 | 대기 및 스케줄링 | 리소스 상태는 “Waiting”입니다. 서버(애그리게이터)가 허브에서 초기화되고 OCM 컨트롤러는 배치를 사용하여 클라이언트(협력자)를 예약합니다. |
5, 6 | 실행 중 | 상태가 “Running”으로 변경됩니다. 클라이언트는 글로벌 모델을 가져오고 개인 데이터에 대해 로컬에서 모델을 학습한 다음 모델 업데이트를 모델 집계기에 다시 동기화합니다. 학습 라운드 매개변수는 이 단계가 반복되는 빈도를 결정합니다. |
7 | 완료 | 상태가 'Completed'에 도달합니다. Jupyter Notebook을 배포하여 집계된 전체 데이터 세트에 대해 모델의 성능을 검증하는 방식으로 검증을 수행할 수 있습니다(예: 모든 MNIST(Modified National Institute of Standards and Technology) 숫자를 예측하는지 확인). |
Red Hat Advanced Cluster Management: FL 환경을 위한 엔터프라이즈 제어 및 운영 가치
OCM에서 제공하는 핵심 API 및 아키텍처는 Red Hat Advanced Cluster Management for Kubernetes의 기반이 됩니다. Red Hat Advanced Cluster Management는 이기종 인프라 전반에서 동종 FL 플랫폼(Red Hat OpenShift)에 대한 라이프사이클 관리를 제공합니다. Red Hat Advanced Cluster Management에서 FL 컨트롤러를 실행하면 OCM만으로는 제공할 수 없는 추가적인 이점을 얻을 수 있습니다. Red Hat Advanced Cluster Management는 멀티클러스터 환경 전반에서 중앙 집중식 가시성, 정책 기반 거버넌스 및 라이프사이클 관리를 제공하여 분산된 FL 환경의 관리 효율성을 크게 향상시킵니다.
1. 관찰 기능
Red Hat Advanced Cluster Management는 분산된 FL 워크플로 전반에서 통합된 관찰 기능을 제공하므로 운영자는 단일하고 일관된 인터페이스에서 학습 진행률, 클러스터 상태 및 클러스터 간 조정을 모니터링할 수 있습니다.
2. 향상된 연결성 및 보안
FL CRD는 TLS 지원 채널을 통해 애그리게이터와 클라이언트 간의 보호된 통신을 지원합니다. 또한 NodePort 외에도 LoadBalancer, Route 및 기타 Ingress 유형을 포함한 유연한 네트워킹 옵션을 제공하여 이기종 환경에서 보호되고 조정 가능한 연결을 제공합니다.
3. Red Hat Advanced Cluster Management 및 Red Hat OpenShift AI를 사용한 엔드 투 엔드 ML 라이프사이클 통합
기업은 Red Hat Advanced Cluster Management와 OpenShift AI를 활용하여 통합 플랫폼 내에서 모델 프로토타입 제작 및 분산 학습에서 검증 및 프로덕션 배포에 이르는 완전한 FL 워크플로우를 구축할 수 있습니다.
마무리
FL은 모델 학습을 데이터로 직접 이동하여 AI를 혁신하고 컴퓨팅 규모, 데이터 전송 및 엄격한 개인 정보 보호 요구 사항 간의 마찰을 효과적으로 해결합니다. 여기서는 Red Hat Advanced Cluster Management가 복잡한 분산형 쿠버네티스 환경을 관리하는 데 필요한 오케스트레이션, 보호 및 관찰 기능을 제공하는 방법을 중점적으로 설명했습니다.
지금 Red Hat에 문의하여 연합 학습으로 조직의 역량을 강화하는 방법을 알아보세요.
리소스
적응형 엔터프라이즈: AI 준비성은 곧 위기 대응력
저자 소개
Andreas Spanner leads Red Hat’s Cloud Strategy & Digital Transformation efforts across Australia and New Zealand. Spanner has worked on a wide range of initiatives across different industries in Europe, North America and APAC including full-scale ERP migrations, HR, finance and accounting, manufacturing, supply chain logistics transformations and scalable core banking strategies to support regional business growth strategies. He has an engineering degree from the University of Ravensburg, Germany.
Meng Yan is a Senior Software Engineer at Red Hat, specializing in event-driven architectures for multi-cluster management at scale. His research interests focus on agentic AI systems and intelligent automation for software engineering, as well as AI/ML applications in distributed environments such as federated learning and multi-cluster inference.
유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
추론에서 에이전트까지: Red Hat AI 3.4를 통해 기업의 AI 확장
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래