
Introduction
In the OpenShift 3.9 GPU blog, we leveraged machine learning frameworks on OpenShift for image recognition. And in the How To Use GPUs with DevicePlugin in OpenShift 3.10 blog, we installed and configured an OpenShift cluster with GPU support. In this installment, we will create a more sophisticated workload on the cluster - accelerating databases using GPUs.
One of the key parts of any machine learning algorithm is the data (often referred to as the data lake/warehouse, stored as structured, semi-structured or unstructured data).
A major part of machine learning pipelines is the preparation, cleaning, and exploration of this data. Specifically removing NAs (missing values), transformations, normalization, subsetting, sorting, and a lot of plotting.
This blog will focus on the data preparation phase, showing how we can use a GPU to accelerate queries in PostgreSQL (the data warehouse). It then uses R for plotting the data.
Environment Overview
- Red Hat Enterprise Linux 7.5, CentOS PostgreSQL 10 image
- OpenShift Container Platform 3.10 Cluster running on AWS
- Container Runtime: crio-1.10.5
- Container Tools: podman-0.6.1, buildah-1.1, skopeo-0.1.30
- Master node: m4.xlarge
- Infra node: m4.xlarge
- Compute node: p3.2xlarge (One NVIDIA Tesla V100 GPU, 8vCPUs and 61GB RAM)
The yaml and configuration files used for this blog can be found at https://github.com/redhat-performance/openshift-psap/tree/master/blog/gpu/pg-strom
We have created a git repository that includes artifacts to be used throughout the blog. We will refer to them as pg-strom/<file> from now on.
# git clone https://github.com/redhat-performance/openshift-psap
We will use centos/postgresql-10-centos7 as a base image and enable GPU accelerated queries with PG-Strom. PG-Strom is an extension module of PostgreSQL that enables accelerated SQL workloads for data analytics or batch processing.
Building a custom image with buildah
The building of the new image will be done with buildah, which facilitates building OCI container images and is an alternative to “docker build”. Skopeo is a tool that facilitates inspection, pulling and pushing container images to a registry. Install buildah and skopeo now.
# yum -y install buildah skopeo
Buildah uses simple bash scripts for building and sample demos can be accessed here: Buildah Demos. The buildah script used in this blog can be found at pg-strom/buildah-pg.sh. The script mounts a container, installs required software and commits the container for later use. Simply invoking the script will generate a GPU-enabled PostgreSQL container.
# <dir>/pg-strom/buildah-pg.sh
Let’s check if we have a complete image committed locally:
# podman images | grep pgstrom
localhost/pgstrom latest 7ca1854e4176 5 days ago 517MB
The container can optionally be pushed to a registry. Skopeo can inspect the image without pulling it from a registry:
# skopeo inspect <registry>/<repo>/pgstrom{
"Name": "<registry>/<repo>/pgstrom",
"Tag": "latest",
"Digest": "sha256:b71e9bca91e23a21e7579c01d38522b76dc05f83c59",
"RepoTags": [
"latest"
],
"Created": "2018-07-13T10:26:49.604378011Z",
...
Prepare the PostgreSQL server
Another new feature in OpenShift 3.10 is support for HugePages. HugePages are a memory access performance optimization technique commonly used with databases (like PostgreSQL, C and java applications. We will use HugePages for the database memory. Let’s install some tools for easier management and create the needed mounts.
# yum -y install libhugetlbfs-utils
# hugeadm --create-global-mounts
Lets allocate a fair amount of hugepages on our nodes and check the nodes if the changes
were accepted.
For this we will use tuned, which is a daemon for monitoring and adaptive tuning of system devices. We can create a profile that is in its simplest form a configuration file with several sections to tune system controls and parameters. Besides that one can supply bash scripts to implement more complicated tunings to a system.
The following configuration file pg-strom/pgstrom.conf can be placed in /etc/tuned/pgstrom to be recognizable as a profile to tuned. Tuned has the concept of profile inheritance. Here we set “include=openshift-node” as the parent profile for our custom pgstrom (child) profile.
# tuned
[main]
summary=Configuration for pgstrom
include=openshift-node
[vm]
transparent_hugepages=never
[sysctl]
vm.nr_hugepages=16384
Now load the new tuned profile based on the openshift-node profile. Per default each OpenShift node (compute, control-plane, … ) has its own tuning profile based on the responsibilities it has.
# tuned-adm profile pgstrom
Check the node for HugePages.
# oc describe node | grep Capacity -A13
Capacity:
cpu: 8
hugepages-1Gi: 0
hugepages-2Mi: 32Gi
memory: 62710868Ki
nvidia.com/gpu: 1
pods: 250
Allocatable:
cpu: 8
hugepages-1Gi: 0
hugepages-2Mi: 32Gi
memory: 29054036Ki
nvidia.com/gpu: 1
pods: 250
Persistent Volume with Local Storage
We want our data to be saved persistent (as opposed to stored ephemerally, in the container, which would not persist). For this we will use a new feature in OpenShift 3.10 called Local Volumes. The essential part here is the new local-storage-provisioner, which monitors a specific path on the host and creates a PV (persistent volume) for each mount point found in this path.
These PVs can be grouped into named group PVs like SSD or HDD and can be claimed in a namespace. This claim can then be used by a pod as a volume.
How to setup a PV with local volume can be read here: Configuring Local Volumes and how a pod can consume this PV with a PersistentVolumeClaim can be read here: Using Persistent Volume.
For this blog I have created a HDD PV group with a single disk that holds the PostgreSQL data.
# ls /mnt/local-storage/hdd/
disk1
OpenShift will create a PV for disk1, we will claim this PV and mount it into the pod. Have a look at the pg-strom/pgstrom.yml to see how to mount a claim.
After setup of the data store, we can deploy the pgstrom pod with the following pg-strom/pgstrom.yml. Start the pod and check the logs, the container will initializes the PostgreSQL data store (initdb).
# oc create -f pgstrom.yml
# oc logs pgstrom
---------------------------- snip ---------------------------------------
Starting server...
UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
UTC [1] LOG: listening on IPv6 address "::", port 5432
UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
UTC [1] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
UTC [1] LOG: redirecting log output to logging collector process
UTC [1] HINT: Future log output will appear in directory "log".
To enable the extension we have to alter the postgresql.conf (which is stored in the PV that was mounted in to the pod) and add some tweaks for GPU acceleration. Edit /var/lib/pgsql/data/userdata/postgresql.conf inside the pod and set:
# oc rsh pgstrom /bin/bash
$ vi /var/lib/pgsql/data/userdata/postgresql.conf
------------------------- snip -----------------------------------------
## postgresql.conf
huge_pages = on
# Initial buffers and mem too small, increase it to work in mem
# and not in storage
shared_buffers = 30GB
work_mem = 30GB
# PG-Strom internally uses several background workers,
# Default of 8 is too small, increase it
max_worker_processes = 100
max_parallel_workers = 100
# PG-Strom module must be loaded on startup
shared_preload_libraries = '/usr/pgsql-10/lib/pg_strom.so,pg_prewarm'
------------------------- snip -----------------------------------------
After editing the configuration file, restart the pod to enable the new feature.
# oc replace --force -f pgstrom.yml
Inside the pod we can check if the server is listening
# oc exec pgstrom pg_isready
/var/run/postgresql:5432 - accepting connections
The buildah script has also installed postgresql-odbc that is used to connect from our workstation to the database server. But first let’s create the test database on which we will do some initial test queries.
# oc exec -it pgstrom /bin/bash
$ cd /var/lib/pgsql/pg-strom/test
$ make init_regression_testdb
# Grab some coffee, this takes some time
Accessing the DB Server from R
For the next part we will use R and the RStudio to create a notebook similar to a Jupyter notebook to access the database and plot some numbers from our queries.
Install R, RStudio and the R package RPostgreSQL according to your distribution on your workstation.
I have added a simple notebook pg-strom/pgstrom.Rmd for reference. Here is a running notebook in RStudio running SQL queries against the PostgreSQL server.
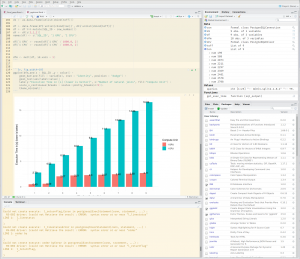
The first step is to connect to the database via the db driver package.
require(RPostgreSQL)drv <- dbDriver("PostgreSQL")
con <- dbConnect(drv,
user="postgres",
password="postgres",
host=".com",
# This is the database we created in the step before
dbname="contrib_regression_pg_strom")
Now we can issue SQL queries against the database. As a first step lets enable PG-Strom extension.
dbGetQuery(con, "SET pg_strom.enabled=on")
We can now run accelerated queries against the database, let’s start with a simple NATURAL JOIN over two tables and let the database EXPLAIN and ANALYZE what it is doing in this specific query.
dbGetQuery(con, "EXPLAIN ANALYZE SELECT cat, count(*), avg(ax) FROM t0 NATURAL JOIN t1 GROUP BY CAT")
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
GroupAggregate (cost=18097.45..18130.73 rows=1024 width=24) (actual time=299.065..300.648 rows=1025 loops=1)
Group Key: t0.cat
-> Sort (cost=18097.45..18100.01 rows=1024 width=48) (actual time=299.053..299.480 rows=1025 loops=1)
Sort Key: t0.cat
Sort Method: quicksort Memory: 193kB
-> Custom Scan (GpuPreAgg) (cost=18025.77..18046.25 rows=1024 width=48) (actual time=295.002..295.546 rows=1025 loops=1)
Reduction: Local
Combined GpuJoin: enabled
-> Custom Scan (GpuJoin) on t0 (cost=19089.39..26894.61 rows=995000 width=16) (never executed)
Outer Scan: t0 (cost=0.00..20310.00 rows=1000000 width=12) (actual time=62.944..106.492 rows=1000000 loops=1)
Depth 1: GpuHashJoin (plan nrows: 1000000...995000, actual nrows: 1000000...994991)
HashKeys: t0.aid
JoinQuals: (t0.aid = t1.aid)
KDS-Hash (size plan: 11.54MB, exec: 7125.12KB)
-> Seq Scan on t1 (cost=0.00..2031.00 rows=100000 width=12) (actual time=0.012..49.225 rows=100000 loops=1)
Planning time: 0.424 ms
Execution time: 476.807 ms
PostgreSQL builds a tree structure of plan nodes representing the different actions taken. We can see that parts of the execution tree is being accelerated by the GPU (GpuPreAgg, GpuJon, GpuHashJoin) and we get as a result the planning and execution time.
Let’s turn off the extension an rerun the SQL statement. Again from our notebook we can issue the following.
dbGetQuery(con, "SET pg_strom.enabled=off")
dbGetQuery(con, "EXPLAIN ANALYZE SELECT cat, count(*), avg(ax) FROM t0 NATURAL JOIN t1 GROUP BY CAT")
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=27455.10..27488.38 rows=1024 width=24) (actual time=2819.862..2823.624 rows=1025 loops=1)
Group Key: t0.cat
-> Sort (cost=27455.10..27460.22 rows=2048 width=48) (actual time=2819.847..2821.153 rows=3075 loops=1)
Sort Key: t0.cat
Sort Method: quicksort Memory: 529kB
-> Gather (cost=27127.42..27342.46 rows=2048 width=48) (actual time=2806.990..2809.907 rows=3075 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial HashAggregate (cost=26127.42..26137.66 rows=1024 width=48) (actual time=2804.084..2804.723 rows=1025 loops=3)
Group Key: t0.cat
-> Hash Join (cost=3281.00..23018.05 rows=414583 width=16) (actual time=306.307..2281.754 rows=331664 loops=3)
Hash Cond: (t0.aid = t1.aid)
-> Parallel Seq Scan on t0 (cost=0.00..14476.67 rows=416667 width=12) (actual time=0.027..622.406 rows=333333 loops=3)
-> Hash (cost=2031.00..2031.00 rows=100000 width=12) (actual time=305.785. -> Seq Scan on t1 (cost=0.00..2031.00 rows=100000 width=12) (actual time=0.012..182.335 rows=100000 loops=3)
Planning time: 0.201 ms
Execution time: 2824.216 ms
We can see that no GPU methods appear and the query is run on a CPU. The execution time increased from ~477 ms to 2824 ms - almost a 6x speedup.
Let’s take this as a starting point and create a benchmark for natural joins for ten tables (t0-t9) adding one table at a time run on a CPU and on a GPU. I have implemented a small function to extract the execution time from the output and saving the results in a R data frame for easier handling and plotting (see the notebook for more details).
Now run the queries against the CPU and GPU.
dbGetQuery(con, "SET pg_strom.enabled=on")ton <- list()
ton <- c(ton, get_exec_time(dbGetQuery(con, "EXPLAIN ANALYZE SELECT cat, count(*), avg(ax) FROM t0 NATURAL JOIN t1 GROUP BY CAT")))
ton <- c(ton, get_exec_time(dbGetQuery(con, "EXPLAIN ANALYZE SELECT cat, count(*), avg(ax) FROM t0 NATURAL JOIN t1 NATURAL JOIN t2 GROUP BY CAT")))
ton <- c(ton, get_exec_time(dbGetQuery(con, "EXPLAIN ANALYZE SELECT cat, count(*), avg(ax) FROM t0 NATURAL JOIN t1 NATURAL JOIN t2 NATURAL JOIN t3 GROUP BY CAT")))
ton <- c(ton, get_exec_time(dbGetQuery(con, "EXPLAIN ANALYZE SELECT cat, count(*), avg(ax) FROM t0 NATURAL JOIN t1 NATURAL JOIN t2 NATURAL JOIN t3 NATURAL JOIN t4 GROUP BY CAT")))
...
After extracting the execution times we are now able to plot the data in R, we are using here ggplot2, the most used graphing package in R.

The GPU accelerated queries level off at ~2.5 sec where the CPU queries increase by each new table added. We could go further and add more tables to show when the GPU execution time will increase but that is out of scope for this blog entry.
Running DBT-3 on PostgreSQL with PG-Strom
The DBT-3 benchmarks is an open source implementation of a decision support benchmark, where the data and workload are based on a specific database specification. The benchmark will be run with PG-Strom enabled and disabled similar to the test above.
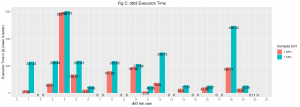
Most the queries are accelerated without any SQL query changes (Some of the queries did not run either on CPU or GPU so they were reported as 0).
Conclusion
PG-Strom is a nice drop-in for immediate acceleration at the SQL database level. The more number crunching operations one has in a query (avg, cnt, sqrt, …) the more benefit one will have from the GPU.
Furthermore there are several efforts going on to accelerate R with GPUs. In the near future one might have a complete GPU accelerated pipeline from database to analytics, plotting and statistical computing in R.
저자 소개
유사한 검색 결과
에이전틱 패러독스와 하이브리드 AI의 필요성
과거의 운영 방식에서 벗어나 IT의 미래 구축
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래