This is the fourth installment of the “How Full is my Cluster” series. Previously, we explored how Red Hat OpenShift manages scheduling and resource allocation, how to protect nodes from overcommitment and finally, some general considerations on how to create a capacity management plan.
Given that these articles were originally written more than a year ago, portions may have changed, but the general guidance is still valid. In particular, the recommendation around always specifying the memory and CPU requests for containers is still absolutely relevant as it helps Kubernetes’ scheduler make correct placement decisions.
While explaining these concepts to customers, one question inevitably arises: if there is a recommendation that every container specify a value for memory and CPU request, what is the suggested value?
In this article I will provide an approach to answering that question.
Determining the right size for pods.
Determining the proper values for pod resources is challenging. In an organization, it can be difficult to identify a team that has the proper insights regarding the resource requirements in production for a given application. There are several reasons for this impasse.
- In a pre-container world, this question was not as crucial. Applications run in VMs, and these VMs are usually oversized and not finely tuned to the application needs, thus creating resource waste.
- Proper applications resource management is relevant only in production and load test environments. Development teams, which are the best candidates for understanding the needs of their applications, are usually removed from those environments.
- Sometimes the application is not observable enough to allow for the proper estimation of the required resources. This occurs infrequently, but there are still situations where an Application Performance Management (APM) platform is not implemented.
- Even if the development team was empowered to see the relevant environments and the right observability tools were in place, it would still be difficult to correctly estimate the application resource needs because these needs change. The resource needs change over time because of changes in the load profile (for example increased adoption) and because new features are added/change affecting resource usage.
Enter the Vertical Pod Autoscaler
Fast forward to today, and translating the idea that the cluster should become aware of the necessary compute resources required into Kubernetes concepts, a controller can be used to perform this task on a set of a set of pods and provide its best recommendation for memory and cpu (and potentially other metrics).
This is what the Vertical Pod Autoscaler (VPA) does.
VPA is a controller that can be configured to observe a set of pods through the use of a Vertical Pod Autoscaler Custom Resource Definition (CRD). An example is shown below:
apiVersion: autoscaling.k8s.io/v1beta1
kind: VerticalPodAutoscaler
metadata:
name: vpa-updater-test
spec:
selector:
matchLabels:
app: vpa-updater
Notice how the label selector is used to select the set of pods that should be observed.
After a relatively short observation time, the VPA CRD will start to present a recommendation in the status field as follows:
status:
conditions:
- lastTransitionTime: 2018-12-28T20:15:11Z
status: "True"
type: RecommendationProvided
recommendation:
containerRecommendations:
- containerName: updater
lowerBound:
cpu: 25m
memory: 262144k
target:
cpu: 25m
memory: 262144k
uncappedTarget:
cpu: 25m
memory: 262144k
upperBound:
cpu: 3179m
memory: "6813174422"
| Field | Description |
| Lower bound | Minimal amount of resources that should be set for the container. |
| Upper bound | Maximum amount of resources that should be set (above which you are likely wasting resources). |
| Target | VPA’s recommendation based on the algorithm described here and considering additional constraints specified in the VPA CRD. The constraints are not shown in the above VPA example. They allows you to set minimum and maximum caps to VPA’s recommendation, see here for more details. |
| Uncapped target | VPA’s recommendation without considering any additional constraints. |
VPA can actually work in three different modes:
- Off: VPA just recommends its best estimate for resources in the status section of the VerticalPodAutoscaler CRD.
- Initial: VPA changes the container resource section to follow its estimate, when new pods are created.
- Auto: VPA adjusts the container resource spec of running pods, destroying them and recreating them (this process will honor the Pod Disruption Budget, if set).
Recommendation: as VPA is still maturing, always set VPA in Off (recommendation-only) mode for the workload for which you are looking to assess. Then, have a process in place for reviewing the provided recommendation and determine whether it should be applied to the application for the next release. Here is a representation of the recommended workflow:
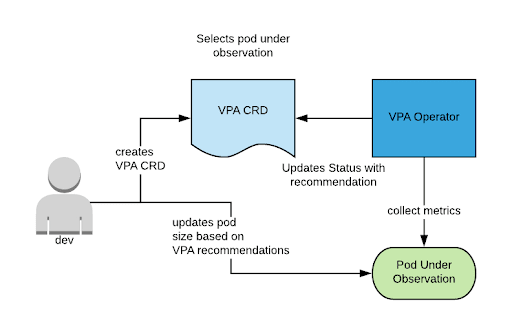
VPA Installation
An installer for VPA on Red Hat OpenShift is available using a Helm template and the instruction can be found here.
Conclusion
VPA is a tool that you can utilize to assess workload needs in terms of resource consumption of applications. Given that the project is still in the initial phases, I recommend using it as another assessment tool. As the VPA project matures from its beta status, it should gain features and stability where it can be safer to enable the automatic adjustment of container sizes at runtime.
저자 소개

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
MCP 카탈로그: Red Hat OpenShift AI에서의 탐색, 배포 및 연결하기
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래