Introduction
When running a containerized application on OpenShift, you may want to connect to the running container to run some troubleshooting tools or check the status of a program. You can easily do that with the oc exec or or rsh commands, but there are some use cases, such as latency-sensitive applications, and applications running a busy loop with a real time priority, where you should not do that, and use an alternative instead.
What happens when we run oc exec
The oc exec (or kubectl exec) usage is well described in several resources, such as the Kubernetes documentation for kubectl exec and the OpenShift developer documentation for oc exec. The following diagram shows what happens under the hood, with the connection flow between the different components:

- First, the oc client connects to the OpenShift API server, running on one of the control plane nodes.
- The API server will connect to the kubelet on the worker node running the container.
- The kubelet will send the call to the container runtime, CRI-O in the case of OpenShift, which will then open the connection to the running container via the Linux kernel.
The above described process allows us to connect to any running container from our workstation, as long as we have network connectivity to the OpenShift API server. It is a very convenient way, but there is one use case where this is bound to create issues.
Limitations and corner cases
There are cases where a containerized application will have a requirement for maximum throughput and minimum latency. Some of these examples include High-Performance Computing, AI or Telco 5G applications. These applications typically require some custom system tuning to remove all potential sources of interrupts from the application, such as hardware interrupts from devices or kernel threads. Such interrupts could cause a spike in latency, which would be unacceptable for the application.
The combination of all the following requirements for one of these latency-sensitive applications can lead to an issue when we try to enter the running container using oc exec:
- The container runs on the real-time Linux kernel, as offered by OpenShift for low latency tuning.
- It uses a real-time process priority, with an unlimited time slice. You can use a performance profile to create this configuration.
- The application runs as a busy-loop thread, taking up 100% of the CPU time and never yielding the CPU back to the kernel. Applications using the Data Plane Development Kit (DPDK) are a good example of this behavior.
- The application threads are pinned to specific CPUs, and the container is assigned a Guaranteed QoS class so its CPUs are never shared with other containers.
The following diagram describes the potential issue that could happen when we try to enter the running container using oc exec:
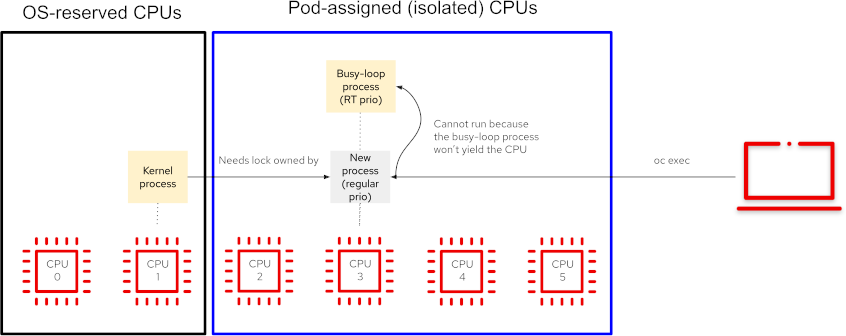
- When oc exec starts a new process on the container, it does so with a regular process priority, on any of the CPUs assigned exclusively to the container.
- That means the newly spawned process could land on the same CPU as the busy-loop application running with a RT priority.
- If that happens, it may create one of the following two issues:
- The new process will never get any CPU time, since the RT application is not giving the CPU back. Then, if the regular process holds a kernel lock for some reason, and that lock is required by a critical kernel thread, it can cause a complete system hang due to a deadlock.
- Alternatively, if the operating system gives some CPU time to the new process, it will steal that CPU time from the busy-loop thread, causing a latency spike and potentially preventing the real-time application from completing its task on time.
The key to this issue is the fact that, when we enter the pod using oc exec, the new process is only allowed to run on the same set of guaranteed CPUs as the container, without an option to choose on which CPU to run. If the new process is scheduled to run on the same CPU as the busy-loop RT process, there is a risk that it will impact its latency requirements, and in the worst case scenario cause a kernel hang.
Alternatives to oc exec
Under the above mentioned configuration, connecting to the container using oc exec poses a potential risk. Thus, we need an alternative that allows us to access the container while running on a separate CPU set. For this purpose, we can use the nsenter utility, included by default with Red Hat Enterprise Linux and Red Hat OpenShift.
Nsenter allows us to enter one or more of the namespaces where a container is running. When run from the worker node running the container, we can effectively “get inside” the container without using oc exec. Since the tool is executed from the worker node shell (entered via oc debug node or SSH), it will be running on the set of CPUs reserved for the operating system and services, so it will not affect the workload running on the container. This prevents the risk for a latency spike in the application, or a low priority process starvation. The following diagram shows how this would work.
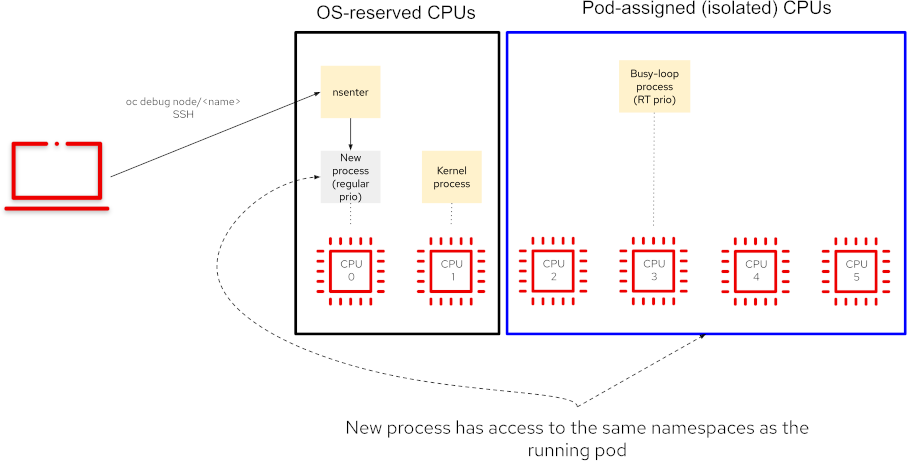
Using nsenter requires access to the worker node and some extra steps to enter the container namespace. Appendix A contains the whole process.
While this process is a way to overcome the limitations of oc exec with latency-sensitive applications, it is not a silver bullet, and oc exec is much more convenient for the general use case. The following table details the differences and requirements for each tool.
| oc exec | nsenter | |
|---|---|---|
| Access requirements | Any node with network connectivity to the cluster | Must be executed from the worker node running the container |
| Other required knowledge | Only need to know the pod/container name | Need to get low-level container ID information |
| Behavior on guaranteed QoS class pods | Same cpumask as container (runs on isolated cores), conflicts with latency-sensitive applications and potential hang when running busy-loop threads with RT priority | Same cpumask as OS processes (runs on reserved CPU cores or unused isolated cores), no conflict with latency-sensitive applications or CPUs running busy-loop threads with RT priority |
Summary and future steps
In general, running oc exec to connect to a running container is a safe and reliable mechanism. However, there are some corner cases where this may not be advisable. For those cases, using nsenter from the worker running the container is a valid, although more complex, alternative, that avoids placing the executed process in the same CPU set as the running container.
For the future, a better alternative would be to include additional functionality into the oc client, so it can be instructed to start the process in a separate CPU set.
Acknowledgements
- John Williams and Arkady Kavevsky, for their reviews and input on this post.
- Lazhar Halleb, for the initial idea that inspired the post.
- Grzegorz Halat, Juri Lelli and Daniel Bristot de Oliveira, for their help and knowledge transfer.
Appendix A: how to use nsenter to access a container namespaces
-
Get the CRI-O container ID:
$ oc describe pod <pod name> |grep -i container.*id
You will get the container ID in the following format:
Container ID: cri-o://567558dae179435d351deb71bb39d50c2f6e2387e732804f61d5a800e3c9b9ee
-
Enter the node running the pod:
$ oc debug node/<node name>
Once inside the debug pod:
$ chroot /host
As an alternative, we can run:
$ ssh core@<node IP>
And then:
$ sudo su
-
Find the PID for the pod's main process. This can be done in two ways:
If we know the process name, we can simply do:
# ps -ef|grep <process name>
And then get the process ID. Otherwise, we can use the container ID from step 1 and run:
# crictl inspect <container ID> |grep -i pid.*[0-9]
We will see something like the following:
"pid": 54526,
-
With the process ID, we can enter its namespace:
# nsenter -a -t <PID>
This will start a shell. We can run a command directly with:
# nsenter -a -t <PID> -- <command and arguments>
-
We can check using taskset that the CPU mask for the new process does not contain the isolated CPUs used by the pod.
저자 소개

유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
AI의 다음 변곡점: 에이전트를 엔터프라이즈 슈퍼유저로 전환
A composable industrial edge platform | Technically Speaking
Crack the Cloud_Open | Command Line Heroes
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래