




This article describes recent work done at NERSC in collaboration with Red Hat to modify Podman (the pod manager tool) to run at a large scale, a key requirement for high-performance computing (HPC). Podman is an open source tool for developing, managing, and running containers on Linux systems. For more details about this work, please see our paper which will be published in the CANOPIE-HPC Supercomputing 2022 proceedings.
[ Download the eBook Podman in Action ]
In our demo video, we walk through pulling an image onto Perlmutter from the NERSC registry, generating a squashed version of the image using podman-hpc, and running the EXAALT benchmark at large scale (900 nodes, 3600 GPUs) via our podman-exec wrapper. NERSC's flagship supercomputing system is Perlmutter, currently number 7 on the Top 500 list. It has a GPU partition with over 6000 NVIDIA A100 GPUs and a CPU partition with over 6000 AMD Milan CPUs. All of the work described in this blog post has been performed on Perlmutter.
NERSC, the National Energy Research Scientific Computing center, is the US Department of Energy's production mission computing facility that serves the DOE Office of Science, which funds a wide range of fundamental and applied research. In the first half of 2022, more than 700 unique users used Shifter, the current container solution at NERSC, and general user interest in containers is growing.
Although NERSC has demonstrated near bare metal performance with Shifter at large scales, several shortcomings have motivated us to explore Podman. The primary factor is that Shifter does not provide any build utilities. Users must build containers on their own local system and ship their images to NERSC via a registry. Another obstacle is that Shifter provides security by limiting the running container to the privileges of the user who launched it. Finally, Shifter is mostly an "in-house" solution, so users must learn a new technology, and NERSC staff have the additional burden of maintaining this software.
Podman provides a solution to all of these major pain points. Podman is an OCI-compliant framework that adheres to a set of community standards. It will feel familiar to users who have used other OCI-compliant tools like Docker. It also has a large user and developer community with more than 15k stars on GitHub as of October 2022. The major innovation that has drawn us to Podman is rootless containers. Rootless containers elegantly constrain privileges by using a subuid/subgid map to enable the container to run in the user namespace but with what feels like full root privileges. Podman also provides container build functionality that will allow users to build images directly on the Perlmutter login nodes, removing a major roadblock in their development workflows.
Enabling Podman at a large scale on Perlmutter with near-native performance required us to address site integration, scalability, and performance. Additionally, we have developed two wrapper scripts to achieve two modes of operation: Podman container-per-process and podman-exec. Podman container-per-process mode describes the situation in which many processes are running on the node (usually in an MPI application), with one individual container running for each process. The podman-exec mode describes the situation in which there is a single container running per node, even if there are multiple MPI processes.
We ran several benchmarks with podman-hpc on Perlmutter to measure the performance of bare metal implementations: Shifter, Podman container-per-process, and podman-exec mode. The EXAALT benchmark runs the LAMMPS molecular dynamics application, the Pynamic benchmark simulates Python package imports and function invocations, and the DeepCAM benchmark is a climate data segmentation deep learning application. In general, the benchmarks suggest comparable performance between bare metal, Shifter, and podman-exec cases. The startup overhead incurred in Podman container-per-process can be seen in the results of both Pynamic and DeepCAM. In general, podman-exec was our best performing configuration, so this is the mode on which we will focus our future development efforts.
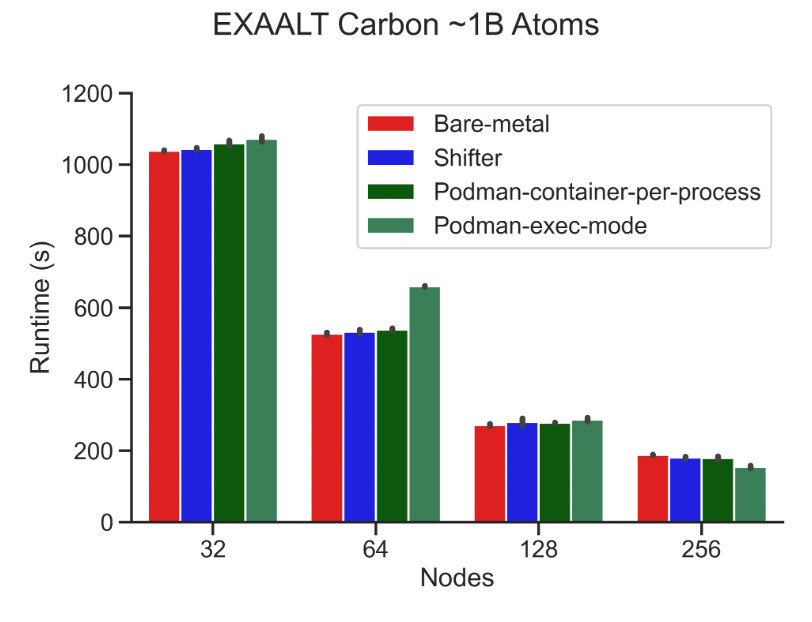
Results from our strong-scaling EXAALT benchmark at 32, 64, 128, and 256 nodes. The average of two bare metal run results are shown in red, Shifter run results are shown in blue, Podman container-per-process run results are shown in dark green, and podman-exec mode results are shown in light green with corresponding error bars.
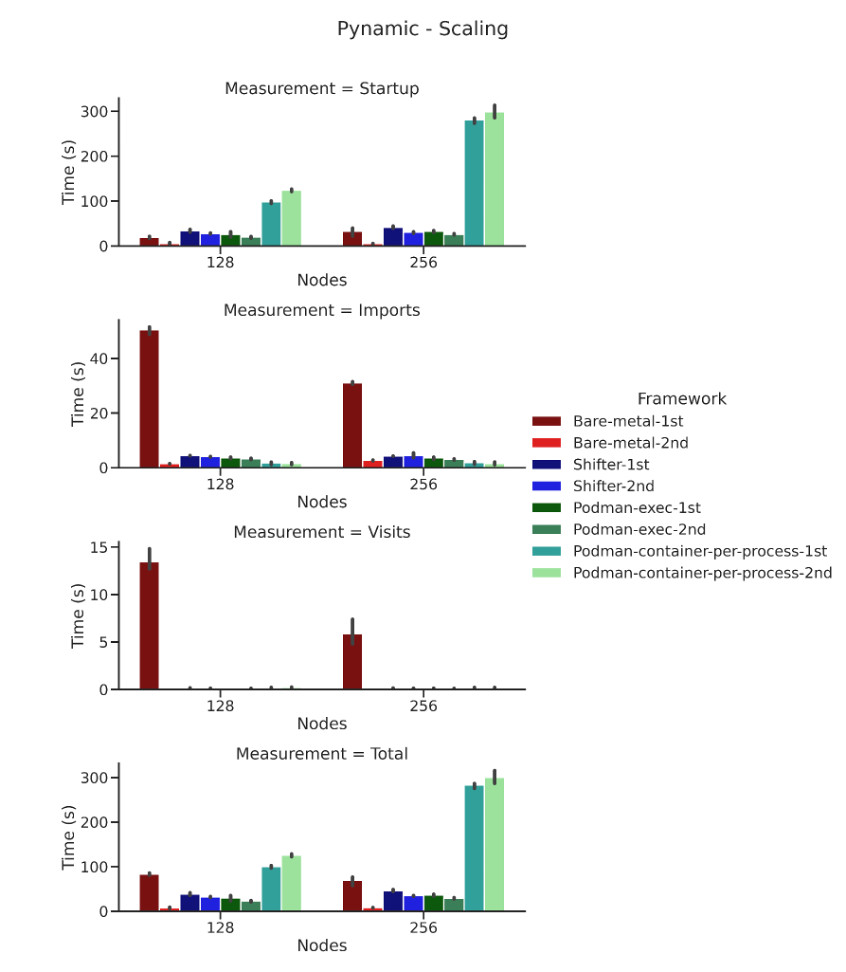
The results of the Pynamic benchmark for bare metal (red), Shifter (blue), podman-exec mode (green), and Podman container-per-process mode (light-green) over two job sizes (128 and 256 nodes) using 64 tasks per node. All configurations were run three times.
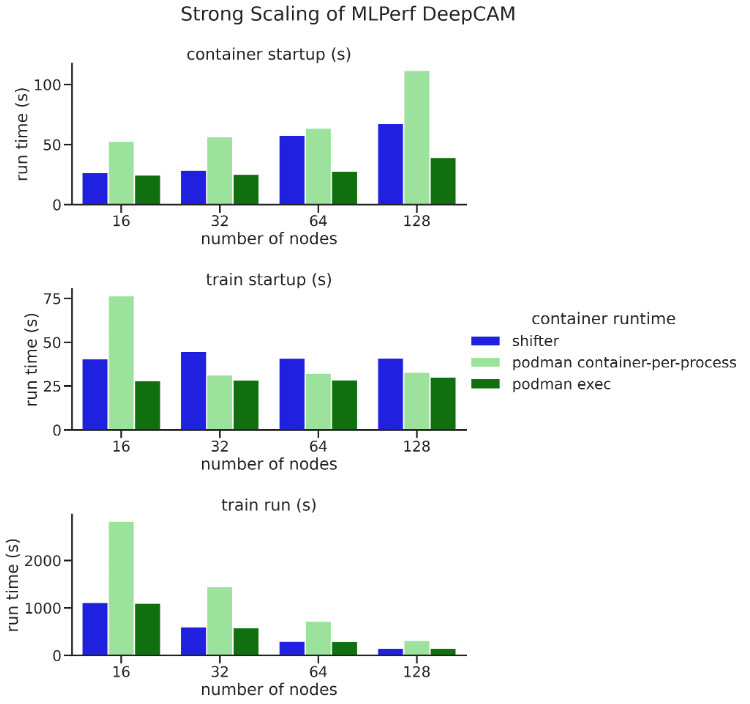
The results of the MLPerf DeepCAM strong scaling benchmark for Shifter (blue), Podman container-per-process (light green), and podman-exec mode (dark green) over a range of job sizes (16, 32, 64, and 128 Perlmutter GPU nodes). We separate the timing data into container startup, training startup, and training runtime.
[ Check out the latest Podman articles on Enable Sysadmin. ]
We are excited about the results we have seen so far, but we still have work to do before we can open Podman to all NERSC users. To improve the user experience, we aim to explore adding Slurm integration to remove some of the complexity of working with nested wrapper scripts, especially for the podman-exec case. We also aim to get our podman-hpc scripts and binaries into the Perlmutter boot images of all nodes, so staging these to each node will no longer be necessary. We hope to address some of the limitations of the OCI hook functionality (for example, the inability to set environment variables) with the OCI community. Finally, our goal is to get much of our work upstreamed into Podman itself so the larger Podman community can leverage our work.
This originally appeared on Opensource.com and is republished with permission.
저자 소개
Laurie Stephey is a Scientific Data Architect in the Data Analytics and Services group. She works on NERSC's container infrastructure and Python teams, she serves as a project liaison for the DIII-D and KSTAR fusion science teams, and she is also interested in scientific workflows and NERSC center data analysis.
Laurie earned her Ph.D. from the University of Wisconsin-Madison in 2017 in magnetic confinement fusion studying edge physics in the HSX and W7-X stellarators. In 2009, she earned her B.A. in Physics from Rollins College in Orlando, Florida.
Andrew J. Younge is the R&D Manager of the Scalable Computer Architectures department at Sandia National Laboratories. His research interests include high performance computing, virtualization & containers, distributed systems, and energy efficient computing.
Dan Fulton earned his PhD from the University of California, Irvine, in computational plasma physics in 2015. He continued his plasma computation research as a scientist at Tri Alpha Energy (now TAE Technologies) from 2015-2018, and then made a leap to the Future innovation team at Adidas, where he developed software tools to aid in the engineering and design of 3D printed footwear components. He also introduced and deployed JupyterHub to Adidas Future. In 2021, Dan joined the NERSC Data & Analytics Services team at Berkeley National Lab as a Scientific Data Architect, with an ambition to bring lessons from private sector innovation to back to benefit the scientific research community.
유사한 검색 결과
Red Hat Enterprise Linux의 이미지 모드를 지금 바로 사용해야 하는 4가지 이유
강력한 보안, 즉시 사용 가능, 추가 비용 없이 제공: 컨테이너 보안의 진화
Container Roundup | Compiler
The Containers_Derby | Command Line Heroes
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래