
New to Red Hat Enterprise Linux 7.5, Virtual Data Optimizer (VDO) is a device mapper module which adds data reduction capabilities to the Linux block storage stack. VDO uses inline compression and data deduplication techniques to transparently shrink data as it is being written to storage media.
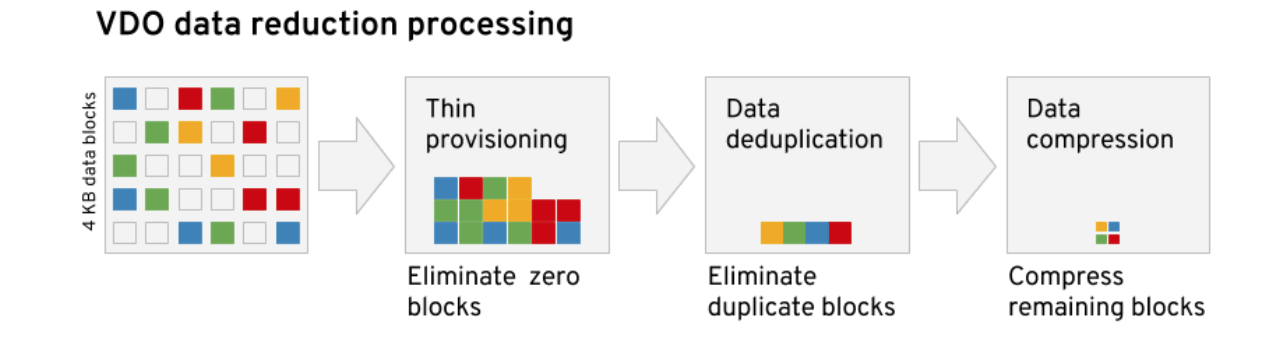
VDO combines three techniques — zero-block elimination, data deduplication, and data compression — to reduce data footprint. The first of these, zero-block elimination, works by eliminating blocks of data consisting entirely of zeros while the second technique, data deduplication, eliminates identical copies of blocks of data that have already been stored. Finally, data compression is applied, which reduces the size of the unique blocks of data stored. By utilizing these techniques, VDO can dramatically increase
the efficiency for both storage and network bandwidth utilization.
Why does VDO matter?
VDO can be used to save storage space and reduce costs. Because it’s a feature of Red Hat Enterprise Linux (RHEL), it can be used anywhere RHEL is deployed; similar savings can be seen in both traditional data center and cloud-based deployments.
In the traditional data center, this means you can repurpose storage resources you already have and make more efficient use of future equipment. Enterprise data replication can also benefit from this efficiency since less data on storage means less data to replicate.
In the cloud, VDO allows you to cut storage costs as well. Depending on your deployment needs, this can translate to lower costs per compute instance, lower costs for cloud-based external block storage, and reduced costs for long-term retention of data snapshots. In addition, reduced footprint on premises or in the cloud translates to reduced bandwidth requirements to copy the data to or from the cloud or even between clouds.
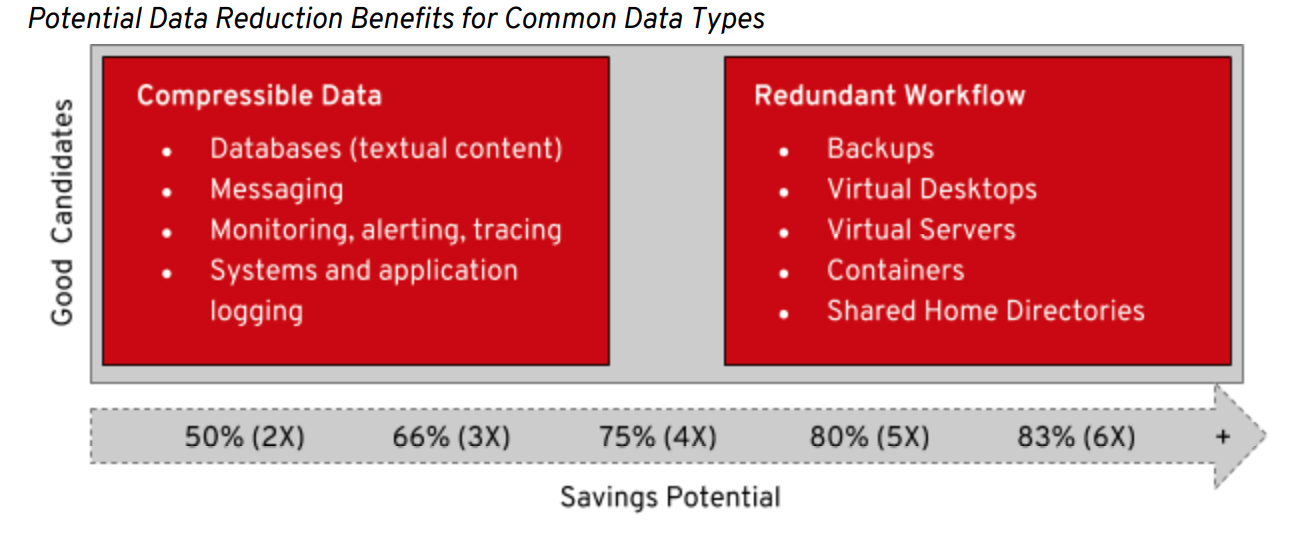
The amount of data reduction you will see with VDO will vary depending on the type of data being stored and the workflow that creates and stores the data. Already compressed data types such as video or audio files will not benefit from this technology, but online backups, virtual machine, and container deployments will see substantial benefits. It is not uncommon for users to report 6:1 data reduction rates in mixed container and VM environments using deduplication and compression technologies such as those provided by VDO. Several good candidates for data reduction with VDO are listed below.
How do I use VDO?
VDO operates at the Linux block layer. This allows it to deliver benefits to local storage as well as to distributed block, file, or object storage solutions.
VDO Deployment Models
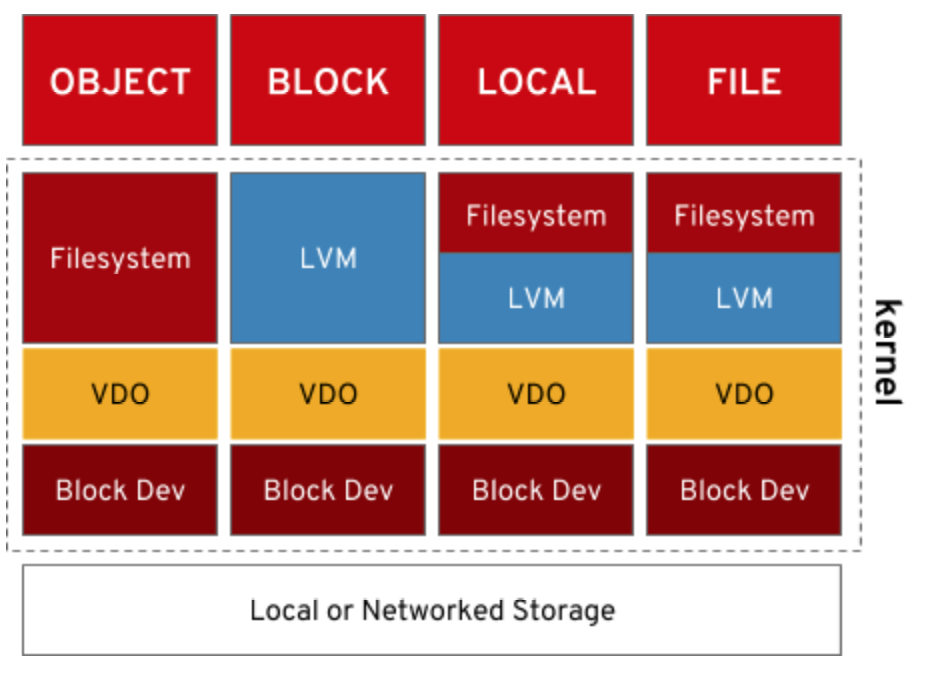
VDO sits on top of an existing block storage device which can be anything from a single local disk, to a RAID device, or even a LUN from an enterprise storage array. Features like encryption and software RAID live below VDO, while components such as LVM and file systems are layered on top of a VDO device.
Configuring VDO for this case is straightforward and can be done in RHEL 7.5 using the vdo command line utility, or by integrating the provided Ansible module in to your playbooks that perform storage configuration. A graphical interface for configuring VDO with Cockpit will be available in the coming months.
To configure VDO you need to know the following :
- The name of the underlying block device (device option)
- The name of the optimized block device that VDO will present (name option)
- The logical size you wish to present to storage layers above VDO (vdoLogicalSize
option)
If you don’t present this last parameter, VDO will create a volume that provides a 1:1 mapping between physical and logical blocks. You will be able to grow the physical and logical size of the volume later on using the vdo growPhysical and vdo growLogical commands.
As a simple example, we create a VDO volume on the device /dev/sdb with the name vdo1 and logical size of 10TB by running the vdo create command:
# vdo create --device=/dev/sdb --name=vdo1 --vdoLogicalSize=10T VDO instance 1 volume is ready at /dev/mapper/vdo1
The vdostats command can be used to verify that the volume was configured correctly. Since VDO provides thin provisioning, this tool should also be used to determine how much free physical space is left on the underlying storage device:
# vdostats Device 1K-blocks Used Available Use% Space saving% /dev/mapper/vdo1 117220824 4051080 113169744 3% N/A
On successful configuration, the output of vdostats shows the device name for your new VDO volume (Device) along with statistics that show the total number of blocks (1K-blocks), number of blocks in use (Used), number of blocks remaining (Available), percentage of the total blocks in use (Use%) and percentage of space savings (Space saving%).
You’re now ready to use your new VDO volume just as you would any other block storage for configuring logical volumes and file systems to operate on the device.
Access VDO today in Red Hat Enterprise Linux 7.5, now available in the Red Hat Customer Portal to all customers with an active Red Hat Enterprise Linux subscription. To access and download Red Hat Enterprise Linux 7.5, please visit: https://access.redhat.com/products/red-hat-enterprise-linux.
저자 소개
Louis Imershein is a Product Manager at Red Hat where his focus is on improving the Red Hat Enterprise Linux software developer experience. He has an extensive background in software development, architecture, quality assurance, technical support, and product management on a wide range of OS, management, security, and storage software projects. Louis joined Red Hat as part of the acquisition of Permabit Technology Corporation, where he was VP of Product.
유사한 검색 결과
에이전틱 AI가 요구하는 새로운 인프라 스택: AMD와 Red Hat의 솔루션 제공
과거의 운영 방식에서 벗어나 IT의 미래 구축
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래