
It is a commonly used catch phrase to say how 'Software is Eating The World' and how all companies are now software companies. It isn't just the software that is important though, it is the data which is being generated by these systems. At the extreme end of the spectrum, companies can generate or collect quite massive data sets, and this is often referred to as the realm of 'Big Data'.
No matter how much data you have, it is of no value if you don't have a way to analyse the data and visualise the results in a meaningful way that you can act upon.
You could develop additional custom software systems to process such data, but these often only provide one interpretation of the data and don't provide a way for people to do ad-hoc analysis and derive new results from the data.
For doing ad-hoc analysis, an increasingly popular approach is to make use of an interactive code based environment such as Jupyter Notebooks. This is a web-based application that allows you to create and share documents that contain live code, equations, visualisations and explanatory text.
Getting the Jupyter Notebook software installed on your own laptop isn't too difficult, but working in a local environment can be limiting. By running Jupyter Notebooks in a hosted environment such as OpenShift, you can benefit from increased resources, but also the ability to easily hook into distributed backend data processing environments, also hosted in OpenShift, based on systems such as Apache Spark or ipyparallel.
OpenShift being a system suitable for delivering applications at scale, also makes it an ideal platform for use in the delivery of Jupyter Notebooks in a classroom based teaching environment using the JupyterHub software.
As a quick demonstration of how easy it is to run a single Jupyter Notebook instance on OpenShift, in this blog post I will step you through deploying a Jupyter Notebook instance which is pre-populated with a set of notebooks, and with Python packages required by the notebooks automatically installed.
Adding Support for Jupyter Notebooks
To make it easy to deploy Jupyter Notebooks from the OpenShift web console, the first thing we are going to do is load in an image stream definition. This is a definition which tells OpenShift where an existing Docker-formatted image can be found for running a Jupyter Notebook instance. The image stream definition also specifies metadata which helps OpenShift categorise any images. Using the information OpenShift can then add Jupyter Notebook as a choice in the catalog of applications available for installation from the web console.
If you are using the command line, you can add the image stream definition to a project by running the command:
oc create -f https://raw.githubusercontent.com/getwarped/s2i-minimal-notebook/master/image-streams.json
This will result in the creation of an image stream called s2i-minimal-notebook in the current project. If you wanted to provide the option of running a Jupyter Notebook to all users, you could instead load the definition into the special openshift project rather than the current project.
To load the image stream definition from the web console, you can instead select Add to project from the web console, then Import YAML/JSON, and cut and paste the definition from the above URL location into the web console and select Create.
Deploying the Jupyter Notebook
Having loaded the image stream definitions, Jupyter Notebook will now be able to be selected from the catalog of applications that can be installed from the web console.
In the web console, select Add to project from the overview page for a project. The catalog of installable applications should be displayed.
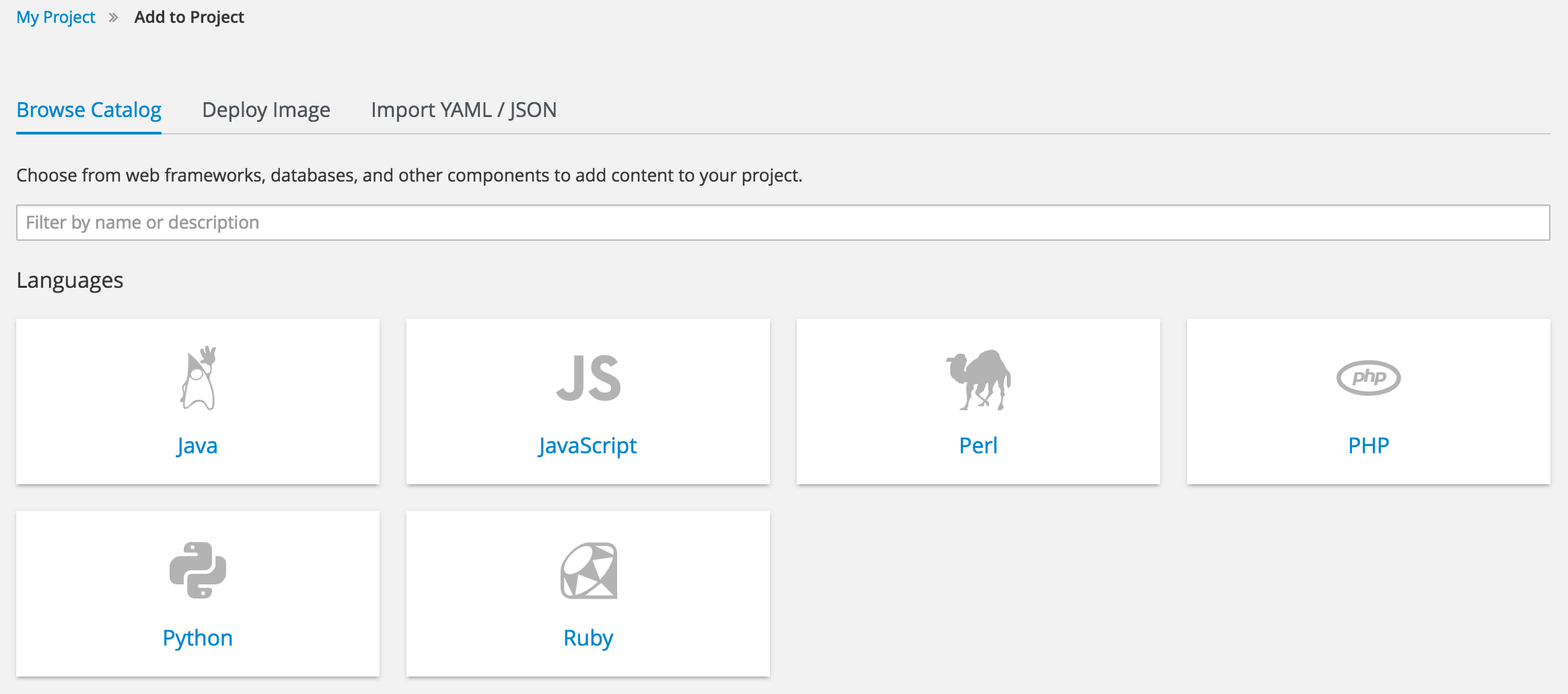
Select the Python category.
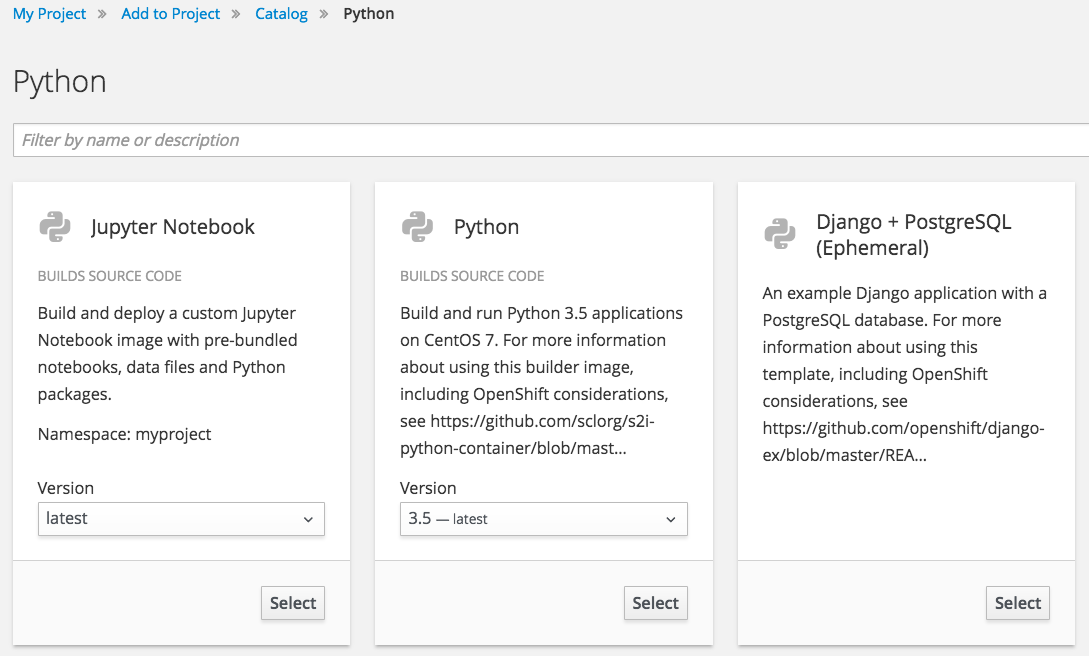
Click on Select for Jupyter Notebook.
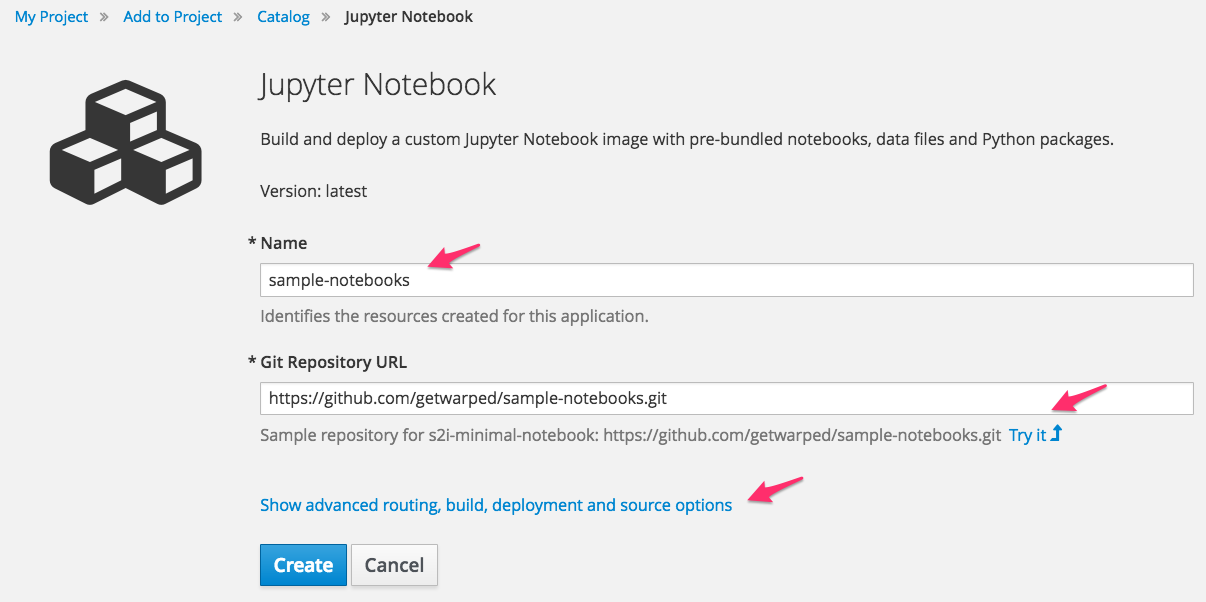
Enter sample-notebooks in the Name field and click on Try it to populate the Git Repository Url with the sample repository.
Before you press Create first select on Show advanced routing, build, deployment and source options. Scroll down to Deployment Configuration.
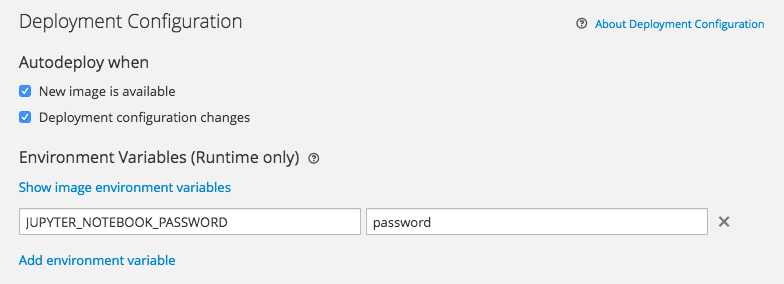
Add a runtime environment variable with name JUPYTER_NOTEBOOK_PASSWORD. Fill in the value with a password to be used for the Jupyter Notebook instance. Also select Secure route under Routing if you want to ensure a secure connection is used when communicating with the Jupyter Notebook application.
When the configuration has been updated, select Create, and then click through to the Overview page for the project. When the deployment is complete, you will see:
Click on the URL for the Jupyter Notebook application. This should bring you to the login page for the Jupyter Notebook dashboard. Login using the password you specified in the deployment configuration. You should now be at the Jupyter Notebook dashboard.

Click on rht-stock-price-ipynb in the dashboard. This should launch a new browser window with the Jupyter Notebook interactive console.

What you see at this point is the saved output from when the notebook was created. To re-execute each cell in the notebook, click repeatedly on the play icon. This will cause the last years worth of stock price data for Red Hat to be downloaded and displayed.
Implementation Deep Dive
As shown, deploying a Jupyter Notebook instance is easy and is achieved using the standard OpenShift web console. There is no special purpose launcher application required that you have to install, as is the case with other systems available for deploying single Jupyter Notebook instances.
There is though a bit more going on under the covers here than may be apparent. Not only was a Jupyter Notebook instance deployed, it came bundled with a set of notebooks which were automatically pulled down from the specified Git repository URL. At the same time, the Python packages required by the notebook were also installed as part of preparing and deploying the Jupyter Notebook instance.
This method of deployment is not the only one possible. One could instead create an empty workspace if desired. This could be a transient workspace with everything thrown away when you are done, or could be backed by a persistent volume so your work is always being saved.
As there are different ways you could deploy Jupyter Notebooks in the OpenShift environment, and it is instructional to understand how everything works under the covers, I will follow up this blog post with a series of blog posts explaining how we go this far.
The subsequent blog posts in this series will be as follows.
Jupyter on OpenShift Part 2: Using Jupyter Project Images - Will show how the Jupyter Notebook images from the Jupyter Project can be deployed on OpenShift.
Jupyter on OpenShift Part 3: Creating a S2I Builder Image - Will show how the Jupyter Project images can be Source-to-Image (S2I) enabled, allowing them to be run against a Git repository to bundle notebooks and data files, as well as install required Python packages.
Jupyter on OpenShift Part 4: Adding a Persistent Workspace - Will show how to add a persistent volume and automatically transfer notebooks and data files into it so work is saved.
Jupyter on OpenShift Part 5: Ad-hoc Package Installation - Will show how to deal with ad-hoc package installation and moving the Python virtual environment into the persistent volume.
Jupyter on OpenShift Part 6: Running as an Assigned User ID - Will show how the S2I enabled image can be modified to allow it to run under the default security policy of OpenShift.
Jupyter on OpenShift Part 7: Adding the Image to the Catalog - Will show how to create the image stream definitions which allowed the Jupyter Notebook image to be listed in the application catalog of the web console.
Although the posts use Jupyter Notebooks as an example, they cover various techniques, and include tips, which are relevant to other use cases for OpenShift.
Future Blog Post Topics
After this initial series of posts I intend to use Jupyter Notebooks as a subject for additional posts. In subsequent series of posts I hope to cover topics such as:
- Adding support for action hooks into the S2I builder image for Jupyter Notebooks as a means to support notebook and server extensions, as well as other user customisations.
- The steps involved in creating a set of application templates to simplify building custom Jupyter Notebook images and deploying them.
- Building a S2I builder image for Jupyter Notebooks from scratch on top of the standard OpenShift Python S2I builder image.
- Porting and running the JupyterHub software on OpenShift, to support teaching using Jupyter Notebooks in a class room environment.
Hopefully you will follow along as I progress through these topics and be patient if the frequency of the posts slows down at times. Enjoy.
저자 소개
유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
AI의 다음 변곡점: 에이전트를 엔터프라이즈 슈퍼유저로 전환
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래