
Tools like sed (stream editor) and grep (global regular expression print) are powerful ways to save time and make your work faster. Before diving deep into the use cases, I would like to briefly explain regular expressions (regexes), which are necessary for the text manipulation that we will do later.
What are regular expressions? When we deal with log files, text files, or a piece of code, we
need to understand that all of these consist of characters. When the length of the file is large, it becomes a necessity to filter out certain patterns in order to make your debugging easier. You will find examples of regular expressions throughout these use cases.
Group 1: Server data
Let’s say you have a file that has an occurrence of a string:

Now, how do you filter out site1’s details (the above file is a simple example), so that you can only grab the necessary info and manipulate the entries?
Clearly, we can see there is a common pattern ("Cloud deployment") throughout the file. So, now we can use filtering techniques to grab info from the file using grep. I remember this as "get regex n print."
Use case 1
If I want the servers from different regions, I can use grep as follows:

Use case 2
Now, say that you know want to filter out the servers on the basis of IP. You can do the same using:

Use case 3
Now, take a look at the first grep command image. Even though you knew your system’s subnet range, the command printed the occurrence of 10.1 throughout the file.
How can you solve this type of use case? We can handle this issue using regex-based advanced filtering, like this:
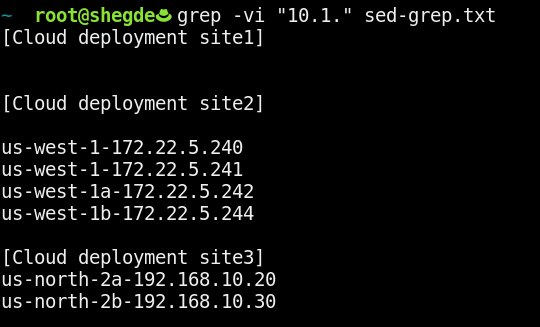
This example is just a possible usage of grep. Again, as this is a relatively small file, you can get what you want using what’s shown above. The -v switch reverses the search criteria, meaning that grep searches the file sed-grep.txt and prints out all of the details, excluding the <search-pattern> (10.1. in this case).
Use case 4
Say that you want to replace the IP addresses and move all of the servers in those regions to a different subnet. You can use sed for this use case.
From the man page, sed uses the format:
sed [options] commands [file-to-edit]
Our command for this use case might look like this:
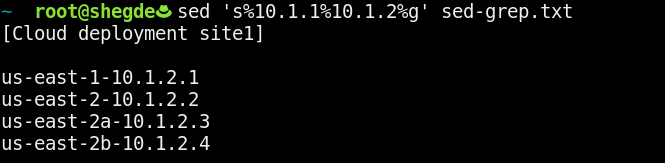
This command breaks down as follows:
- The
sstands for substitute. - The
%is a delimiter (we can use any characters here). - The
<search pattern>appears after the first%. - The
<replace pattern>appears after the second%. - The
gstands for global replace (meaning throughout the file).
Or:
s%<search-pattern>%<replace-pattern>%g
Use case 5
You can even change the servers’ regions in the file:

Use case 6
This use case is more advanced. We’ll only remove comments (#) from a file using sed:
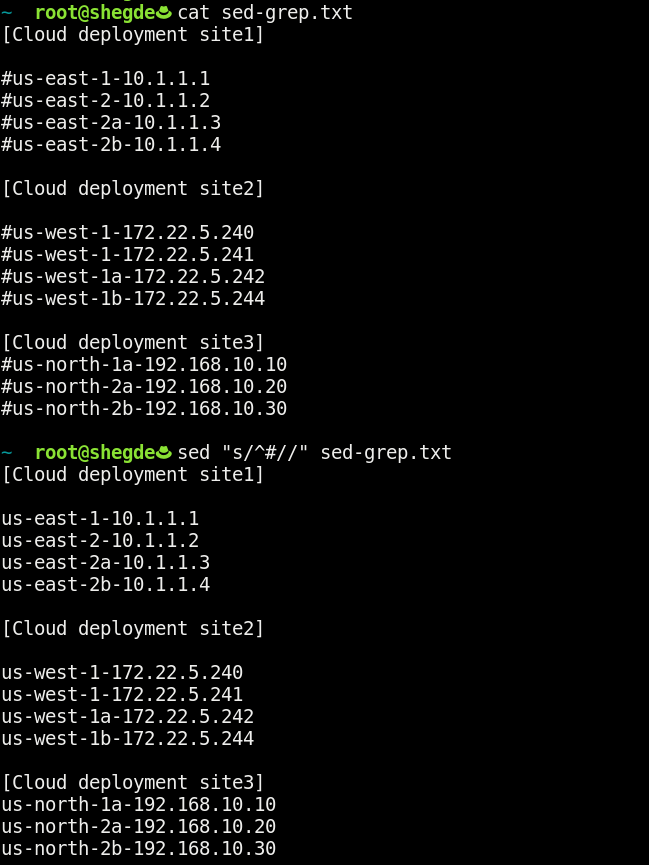
This command says that if # appears as a line’s first character, to replace that line with blank space. As a result, this command does the job of removing the comments from the file.
Group 2: /etc/passwd
Let’s look at some more use cases, this time involving /etc/passwd.
Use case 1
Assume you want to grab the users from the file /etc/passwd file. You can use sed as follows:
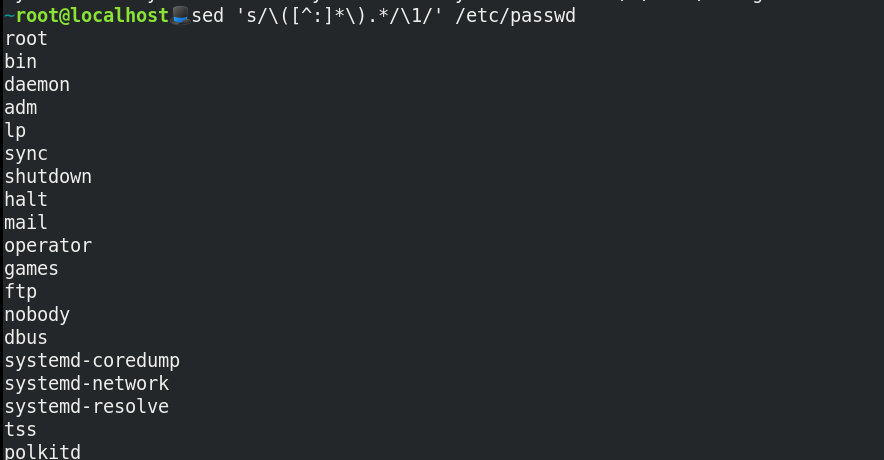
Use case 2
What if you only want to grab the first 10 users from /etc/passwd? You can use sed and awk for this purpose (please bear with me here):
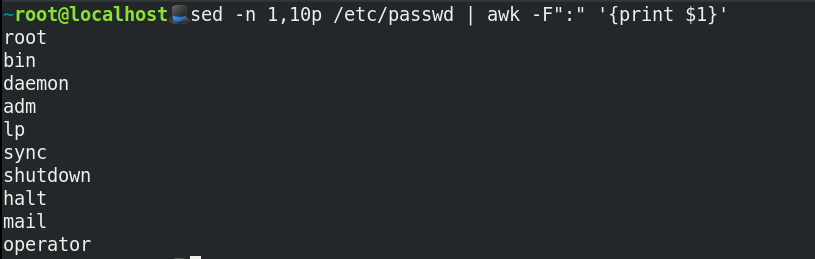
This command breaks down as:
sed -nmeans don’t print everything.pprints the lines one to 10.awkhere uses:as a field separator and prints the first column.
Use case 3
Delete a particular range of lines in text files using sed:

SELinux use case
Here is an example sed command for manipulating SELinux:

Conclusion
This is my attempt to give you readers just a sneak peek of the possibilities of using sed and grep. You can do many text manipulations using these commands. Refer to different options using the man page to learn more.
[Want to try out Red Hat Enterprise Linux? Download it now for free.]
저자 소개
I work as a Solutions Engineer at Red Hat and my day-to-day work involves OpenShift and Ansible. I'm highly passionate about open source software, cloud, security, and networking technologies.
유사한 검색 결과
Red Hat Enterprise Linux, 양자 컴퓨팅 시대를 대비한 SSH 보안 역량 강화
Red Hat Device Edge, 이제 NVIDIA Jetson Orin에서 사용 가능
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래