

Have you ever wondered how AI-powered applications like chatbots, code assistants and more respond so quickly? Or perhaps you’ve experienced the frustration of waiting for a large language model (LLM) to generate a response, wondering what’s taking so long. Well, behind the scenes, there’s an open source project aimed at making inference, or responses from models, more efficient.
vLLM, originally developed at UC Berkeley, is specifically designed to address the speed and memory challenges that come with running large AI models. It supports quantization, tool calling and a smorgasbord of popular LLM architectures (Llama, Mistral, Granite, DeepSeek—you name it). Let’s learn the innovations behind the project, why over 40k developers have starred the project on GitHub and how to get started with vLLM today!
What is vLLM and why you should care
As detailed in our vLLM introductory article, serving an LLM requires an incredible amount of calculations to be performed to generate each word of their response. This is unlike other traditional workloads, and can be often expensive, slow and memory intensive. For those wanting to run LLMs in production, this includes challenges such as:
- Memory hoarding: Traditional LLM frameworks allocate GPU memory inefficiently, wasting expensive resources and forcing organizations to purchase more hardware than needed. Unfortunately, these systems often pre-allocate large memory chunks regardless of actual usage, resulting in poor utilization rates
- Latency: More users interacting with an LLM means slower response times because of batch processing bottlenecks. Conventional systems create queues that grow longer as traffic increases, leading to frustrating wait times and degraded user experiences
- Scaling: Expanding LLM deployments requires near-linear increases in costly GPU resources, making economic growth challenging for most organizations. Larger models often exceed single-GPU memory and flop capacity, requiring complex distributed setups that introduce additional overhead and technical complexity
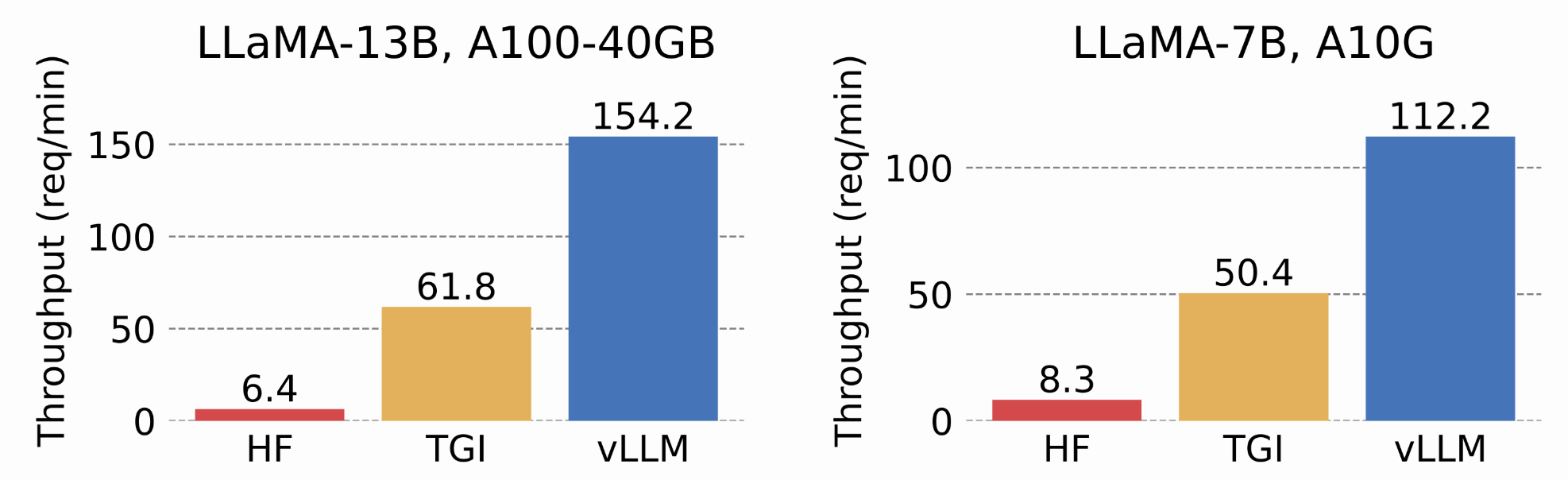
With the need for LLM serving to be affordable and efficient, vLLM arose from a research paper called, “Efficient Memory Management for Large Language Model Serving with Paged Attention," from September of 2023, which aimed to solve some of these issues through eliminating memory fragmentation, optimizing batch execution and distributing inference. The results? Up to 24x throughput improvements compared to similar systems such as HuggingFace Transformers and Text Generation Inference (TGI), with much less KV cache waste.
How does vLLM work?
Let’s briefly touch on the techniques used by vLLM in order to improve performance and efficiently utilize GPU resources:
Smarter memory management with PagedAttention
Introduced by the original research paper, LLM serving is highly bottlenecked by memory, and the PagedAttention algorithm used by vLLM helps better manage attention keys and values used to generate next tokens, often referred to as KV cache.
Instead of keeping everything loaded at once in contiguous memory spaces, it divides memory into manageable chunks (like pages in a book) and only accesses what it needs when necessary. This approach is similar to how your computer handles virtual memory and paging, but now applied specifically to language models!
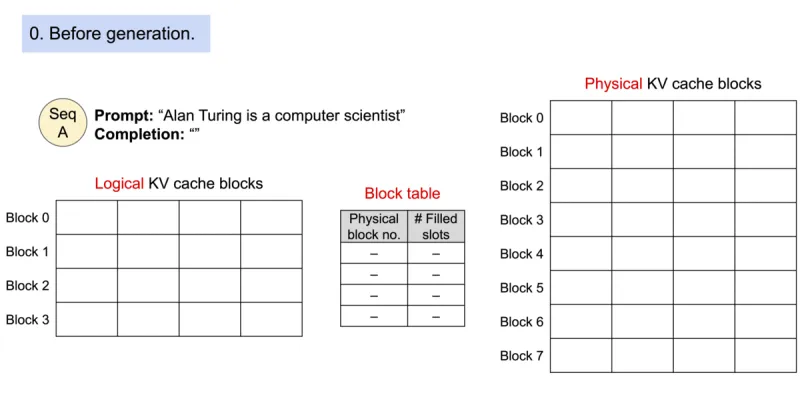
With PagedAttention, the KV cache is stored in non-contiguous blocks, helps target wasted memory and enables bigger batch sizes. Before vLLM, each request received a pre-allocated chunk of memory (whether it uses it or not), with vLLM memory is requested dynamically, so they only use what they actually need.
Continuous batching for requests
Existing inference engines treat batch processing like an old-school assembly line—stop, process a batch, move on, repeat. This leads to frustrating delays when new requests arrive mid-process. With vLLM, requests are bundled together so they can be processed more efficiently. Similar to how a restaurant server will take orders from several tables at once instead of making separate trips to the kitchen each time.

Unlike traditional static batching which waits for all sequences in a batch to finish (which is inefficient due to variable output lengths and leads to GPU underutilization), continuous batching dynamically replaces completed sequences with new ones at each iteration. This approach allows new requests to fill GPU slots immediately, resulting in higher throughput, reduced latency and more efficient GPU utilization.
Hardware optimization and beyond
With GPU resources being expensive to own and run, maximizing efficiency directly translates to cost savings. For this reason, vLLM includes optimizations while serving models, such as optimized CUDA kernels to maximize performance on specific hardware. In addition, we’ve learned that quantized models can accelerate inference and still retain incredible accuracy (~99%) with 3.5x model size compression and speedups of 2.4x for single-stream scenarios.
Getting started with vLLM
Now, let’s take a look at how to get started using vLLM in order to serve a model and make requests to the LLM. While the installation instructions may vary depending on your device architecture and CPU or GPU hardware, you can install vLLM using pip for the pre-built binary to access the vllm command line interface (CLI).
pip install vllm
With the CLI installed, which model should you use? Well, learn here which models are supported by vLLM, but below is a basic command to serve the Granite 3.1 model from Hugging Face, specifically a quantized model, which is approximately three times smaller than the initial model but can retain accuracy.
vllm serve "neuralmagic/granite-3.1-8b-instruct-quantized.w4a16"
Finally, vLLM provides an HTTP server that implements an OpenAI-compatible API server, so let’s make a call to the server using curl.
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "neuralmagic/granite-3.1-8b-instruct-quantized.w4a16",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'Fantastic! There are plenty of examples demonstrating how to use vLLM on the documentation pages, but this shows you how easy it is to get started with the library. With integrations into Hugging Face, LangChain/LlamaIndex and deployment frameworks such as Docker, Kubernetes, KServe and much more, it’s a versatile choice for deploying LLMs. Plus, it’s Apache 2.0-licensed and has a strong open source community on GitHub and Slack.
The takeaway
While the technical implementations in vLLM may seem abstract, they translate to very real and important outcomes—more natural conversations with AI assistants, reduced latency and GPU load when prompting language models and a production-ready inference and serving engine. Thanks to PagedAttention, continuous batching and optimized GPU execution, vLLM delivers speed, scalability and memory efficiency to help make AI more accessible, the open source way. Be sure to star the project on GitHub!
제품 체험판
Red Hat Enterprise Linux AI | 제품 체험판
저자 소개
Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
유사한 검색 결과
과거의 운영 방식에서 벗어나 IT의 미래 구축
추론에서 에이전트까지: Red Hat AI 3.4를 통해 기업의 AI 확장
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래