
At some point during the OpenShift deployment phase, a question about project onboarding comes up, "How can a new customer or tenant be onboarded so they can deploy their own workload onto the cluster(s)?" While there are different ways from a process perspective (Service Now, Jira, etc.), I focus on the Kubernetes objects that must be created on each cluster.
In A Guide to GitOps and Argo CD with RABC, I described setting up GitOps RBAC rules so tenants can work with their (and only their) projects.
This article demonstrates another possibility for deploying per tenant and per cluster:
- Namespace(s) including labels.
- Local project admin group (in case groups are not managed otherwise, like LDAP Group Sync).
- Argo CD AppProject, which limits allowed repos, clusters, permissions, etc.
- Resource Quotas for a project.
- Limit Ranges for a project.
- Default Network Policies, which are:
- Allow traffic in the same Namespace.
- OpenShift Monitoring and API Server.
- OpenShift Ingress.
- Egress deny All.
- Custom Network Policies.
The idea is to fully automate the creation of Kubernetes objects by configuring a Helm values-file in a specific folder structure that an ApplicationSet observes.
Each Kubernetes object can be enabled or disabled to provide more flexibility. For example, if you do not want to work with Limit Ranges, you can disable (or completely remove the whole YAML block), and they will not be created. The same setting is available for any other object.
CAUTION: The configuration of a values-files can be quite confusing. Therefore, I have created an example called project T-Shirt size (see below). The T-Shirts are defined in the global-values-file. Settings can still be overwritten per project if required.
As in my previous article, the Argo CD AppProject object limits a tenant/project accordingly.
I will use a Helm Chart to create any required object. The reasons why I prefer Helm templating are:
- Better repeatability.
- Allows creating easy configuration for most important items (disable/enable objects).
- Allows you to create more complex configurations if needed (disable/enable objects).
- Templating works better than patching in this case, since you do not need to deal with hundreds of overlays or patching configurations, but simply create a values-file and define everything there.
Still, you can use other options like Kustomize to achieve the same goal. In the end, it is up to you what you prefer.
Use case
I will demonstrate the following use case:
- I have two applications, my-main-app and my-second-app, that should be onboarded onto the cluster.
- my-main-app is using two Namespaces, my-main-app-project-1 and my-main-app-project-2. Maybe Mona uses this for frontend and backend parts of the application.
- Mona is the admin for both applications.
- Peter can only manage my-main-app.
- Mona and Peter request new projects (multiple) for the cluster, which will be prepared by the cluster-admin who will create a new folder and generate a values-file (Helm) for that project and the target cluster.
- The cluster-admin synchronizes the project onboarding application in GitOps, which will create all required objects (Namespace, ResourceQuota, Network Policies, etc.).
- Mona and Peter can then use an application-scoped GitOps instance (a second instance) to deploy their application accordingly using the allowed namespace, repositories, etc. (limited by GitOps RBAC rules).
CAUTION: When you install openshift-gitops (Argo CD), a centralized cluster-scoped GitOps instance, a wide range of privileges is created. Developers should not use this instance to onboard their applications. Instead, an application-scoped GitOps instance should be created.
NOTE: I am working with only one cluster to make it easier for me. But different clusters can be used, all managed by a central GitOps instance.
Prerequisites and assumptions
- Users on the cluster: To test everything, Mona and Peter must be able to authenticate. I used simple htpasswd authentication on my cluster.
- Second Argo CD instance (application-scoped GitOps instance): You should not use the main openshift-gitops instance to deploy a tenant workload onto the cluster. Instead, create an application-scoped GitOps instance.
- Example application: https://github.com/tjungbauer/book-import/
- Developers must know and follow the GitOps approach. This is a process thing and common practice. If it is not in Git, it does not exist.
Correlation
The following diagram depicts the relationship between the different objects and GitOps instances.

NOTE: The cluster-admins (platform team) are responsible for all objects created here. Mona and Peter can log into the application-scoped GitOps instance (the second Argo CD instance) and then create and sync their Applications.
Directory structure
ApplicationSets automatically creates multiple Argo CD Applications based on a so-called Generator. In my case, I am using the Git Generator, which walks through a defined folder, reads the configuration files (here, Helm values-files), and uses the parameters to generate the Argo CD Application.
The folder structure looks like the following:
▶├──tenant-projects
│ ├──my-main-app
│ │ └──cluster-local
│ │ └──values.yaml
│ ├──my-second-app
│ │ └──cluster-local
│ │ └──values.yaml
│ └──values-global.yaml
Any tenant is a separate folder, and any tenant can have one or more Namespaces (Projects). I am using the application's name as the separator, for example, my-main-app. Below the application folder, a folder for each cluster is created to distinguish the configuration for different clusters, for example, cluster-local. Finally, this folder contains a large values.yaml that defines everything required for the project onboarding.
The following ApplicationSet uses the files in tenant-projects/**/values.yaml to fetch the parameters. It generates an Application named "-" and uses the Helm Chart Project Onboarding as the source, providing two values-files:
- values-global.yaml: Defines global values, currently the Namespace of the application-scoped GitOps instance, and a list of environments.
- values.yaml of the appropriate folder.
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: onboarding-tenant-workload
namespace: openshift-gitops
spec:
goTemplate: true # <1>
syncPolicy:
preserveResourcesOnDeletion: true # <2>
generators:
- git:
files:
- path: tenant-projects/**/values.yaml # <3>
repoURL: 'https://github.com/tjungbauer/openshift-cluster-bootstrap'
revision: main
template:
metadata:
name: '{{ index .path.segments 1 | normalize }}-{{ .path.basename }}' # <4>
spec:
info:
- name: Description
value: Onboarding Workload to the cluster
destination:
namespace: default
name: '{{ .environment }}' # <5>
project: default
source:
helm:
valueFiles: # <6>
- '/{{ .path.path }}/values.yaml'
- /tenant-projects/values-global.yaml
path: clusters/all/project-onboarding
repoURL: 'https://github.com/tjungbauer/openshift-cluster-bootstrap' # <7>
targetRevision: main
<1> goTemplate is set to true, to enable functions like "normalize".
<2> Applications, created by this ApplicationSet, shall remain even if the ApplicationSet gets deleted.
<3> The path that shall be observed by this ApplicationSet. ** will return all files and directories recursively.
<4> The name that shall be used to generate an Application. The parameter generated out of the folder-name (==app name) and the basename (clustername).
<5> The target cluster to which the tenant workflow shall be deployed. This setting is coming from the values-file.
<6> A list of values files, that shall be used.
<7> The repo URL and path which shall be read.
The Helm Chart found at clusters/all/project-onboarding is only a wrapper that will use the actual Helm Chart helper-proj-onboarding as a dependency. This is where all the magic happens. The wrapper chart is used only to let the ApplicationSet search the GitHub repository and find all the required values-files, which I did not want to attach directly to the actual Helm Chart.
Values file: values-global.yaml
This values-file defines global parameters. The following are the minimum that shall be defined in this file:
global:
# Namespace of application scoped GitOps instance, that is responsible to deploy workload onto the clusters
application_gitops_namespace: gitops-application # <1>
# cluster environments. A list of clusters that are known in Argo CD
# name and url must be equal to what is defined in Argo CD
envs: # <2>
- name: in-cluster
url: https://kubernetes.default.svc
- name: prod-cluster
url: https://production.cluster
<1> The name of the second Argo CD instance (the application-scoped GitOps instance).
<2> The list of clusters as known in Argo CD.
Values file: values.yaml
The individual values files are separated by:
- The tenants/projects.
- The clusters.
This file defines everything required for project onboarding. The example file is quite huge, and probably not everything is needed for every onboarding scenario. You can find a full example in my GitHub repository: values.yaml
Basic parameters
The basic parameters define settings that are either used by the ApplicationSet, define anchors that are used multiple times, or simply define values at the beginning of the file.
The following settings are currently used:
- oidc_groups: Name of the group allowed to work with the Argo CD project. This group might be created by the Helm Chart or must be known (i.e., it is automatically synchronized).
- environment: Defines the name of the cluster as known in Argo CD. in-cluster is the default (local) cluster that Argo CD will create.
NOTE: Environment is defined in each values.yaml and must be one of the clusters defined in the values-global file.
# Group that is allowed in RBAC. This group can either be created using this Helm Chart (will be named as <namespace>-admin) or must be known (for example synced via LDAP Group Sync)
oidc_groups: &oidc-group my-main-app-project-1-admins
# Environment to which these values are valid, this should be the cluster name as visible in Argo CD
# In best case the same is equal to the folder we are currntly in, but this is optional.
environment: &environment in-cluster
Parameters passed to helper-proj-onboarding
Most parameters are handed over to the Chart helper-proj-onboarding. This is indicated by:
# Parameters handed over to Sub-Chart helper-proj-onboarding
helper-proj-onboarding:
All parameters below are used by the Sub Chart.
Namespaces
One or more Namespaces can be created for a tenant. It defines a name, additional_settings (additional labels), and tenant labels. As with any object, a Namespace can be enabled or disabled. Be aware that simply disabling a Namespace does not mean that GitOps will automatically delete all objects (not with the syncOptions setting that the ApplicationSet defines). If a project is decommissioned, the prune option must be selected during the Sync.
The following defines the block that might be used to create a new Namespace object:
# List of namespaces this tenant shall manage.
# A tenant or project may consist of multiple namespace
namespaces:
# Name of the first Namespace
- name: &name my-main-app-project-1
# Is this Namespace enabled or not
enabled: true
# Additional labels for Podsecurity and Monitoring for the Namespace
additional_settings:
# Pod Security Standards
# https://kubernetes.io/docs/concepts/security/pod-security-standards/#restricted
# Possible values: Privileged, Baseline, Restricted
# Privileged: Unrestricted policy, providing the widest possible level of permissions. This policy allows for known privilege escalations.
# Baseline: Minimally restrictive policy which prevents known privilege escalations. Allows the default (minimally specified) Pod configuration.
# Restricted: Heavily restricted policy, following current Pod hardening best practices.
# Policy violations will trigger the addition of an audit annotation to the event recorded in the audit log, but are otherwise allowed.
podsecurity_audit: restricted
# Policy violations will trigger a user-facing warning, but are otherwise allowed.
podsecurity_warn: restricted
# Policy violations will cause the pod to be rejected.
podsecurity_enforce: restricted
cluster_monitoring: true
# List of Labels that should be added to the Namespace
labels:
my_additional_label: my_label
another_label: another_label
Manage local Project-Admin Group
It is possible to create a local Group of project admins. This can be used if no other mechanism exists, such as LDAP Group Sync.
In this example, a local Admin Group will be generated (name -admins) with two users assigned to that Group. The RoleBinding will use the role admin per default. If you are using your own Role, you can define it here.
NOTE: You should always define a local_admin_group block, even if some other option manages the Group object. It will at least create a RoleBinding and assigns the ClusterRole to the group_name.
# Create a local Group with Admin users and the required rolebinding
# If other systems, like LDAP Group sync is used, you will probaably not need this and can either disable it or remove the whole block.
local_admin_group:
enabled: true
# group_name: my_group_name # <1>
# optional parameter, default would be "admin"
clusterrole: admin # <2>
# List of users
users: # <3>
- mona
- peter
<1> Optional: name of the group. If not set, it will be automatically generated based on the Namespace name.
<2> Optional: Name of the ClusterRole. If not set, it will automatically use admin.
<3> List of users assigned to the group. If not set, a RoleBinding will be generated only.
Argo CD RBAC
Projects inside Argo CD (not to be confused with Kubernetes Projects) help you to logically group applications together. In this example, I create an Argo CD project for every Namespace a tenant manages. This will allow Mona or Peter to manage the Application via Argo CD. Such objects are defined by the AppProject object, which is explained in the Argo CD documentation.
These projects you allow to:
- Restrict allowed sources (i.e., Git repositories).
- Restrict destination clusters and namespaces.
- Restrict which objects are allowed to be deployed.
- Define project roles to provide application RBAC (bound to OIDC groups and/or JWT tokens).
- Define timeframes when Application synchronization is allowed or not.
The example defines the following block. All parameters should be set here since no default values will be set for most of them.
# Creation of Argo CD Project
argocd_rbac_setup:
# This is required to build the rbac rules correctly. Theoretically, you can create multiple RBAC rules, but usually you create one per project/tenant
argocd_project_1:
enabled: true # <1>
# Name of the AppProject is set to the tenants Namespace. Which means, each Namespace will get it's own AppProject
name: *name # <2>
# List of allowed repositories. If the tenant tries to use a different repo, Argo CD will deny it. * can be used to allow all.
sourceRepos: # <4>
- 'https://github.com/tjungbauer/book-import/'
rbac: # <5>
# Name of the RBAC rule
- name: write
# Description of the RBAC rule
description: "Group to deploy on DEV environment"
# List of OCP groups that is allowed to manage objects in this project
oidc_groups: # <6>
- *oidc-group
# Project policies
# This will limit a project to specific actions
# Parameters:
# - action: Mandatory, either get, create, update, delete, sync or override
# - permissions: allow or deny (Default: deny)
# - resource: i.e applications (Default: applications)
# - object: Which kind of objects can be managed, default "*" (all) inside the namespace
policies: # <7>
- action: get # get, create, update, delete, sync, override
permission: allow # allow or deny
object: '*' # which kind of objects can be managed, default "*" (all) inside the namespace
- action: create
permission: allow
- action: update
permission: allow
- action: delete
permission: allow
- action: sync
permission: allow
- action: override
permission: allow
# Sync Windows - when application can be synced or not. Typically used to prevent automatic synchronization during specific time frames
# but can be used to limit the allowed syncs as well.
syncWindows: # <8>
- applications:
- '*'
clusters:
- *environment # the cluster we care currently configuring
namespaces:
- *name # the namespace of this application
timezone: 'Europe/Amsterdam' # timezone, default Europe/Amsterdam
duration: 1h # duration, for example "30m" or "1h" (default 1h)
kind: allow # allow or deny (default allow)
manualSync: true # is manual sync allowed ot not (default true)
schedule: '* * * * *' # cronjob like schedule: Min, Hour, Day, Month, Weekday (default '55 0 1 12 *' )
<1> Enabled true/false.
<2> Name of the AppProject object; for better cross-reference, I am using the name of the namespace here.
<3> List of allowed source repositories.
<4> List of RBAC rules with name and description. While it is possible to create multiple rules, I usually work with one definition per Namespace. However, when you have various groups with a fine granular permission matrix, you might need to define more.
<5> List of OpenShift Groups that are allowed for this project. The group name must be known or is generated by the Helm chart.
<6> Policies, containing the parameters: action (get, create, update, delete, sync, or override), permissions (deny, allow), resources (i.e., applications (==default value)) and object (default = *).
<7> Definition of sync windows (timeframe when synchronization is allowed or disallowed). It defines the application, environment, namespace, timezone, timeframe, and whether a manual synchronization is allowed.
ResourceQuota
A ResourceQuota object defines limits per resource for a project. It can limit the quantity of objects (i.e., the maximum number of Pods) and the amount of compute resources that can be requested and used (i.e., CPU and memory).
The following defines several settings for a ResourceQuota. Only the ones that are defined will be created. Any undefined value means no quota exists; thus, no limit is configured for that specific object/compute resource. This makes sure that you define useful values for the quotas that fit into your individual environment.
NOTE: Only hard limits are set currently, but not scopes.
# Configure ResourceQuotas
# Here are a lot of examples, typically, you do not need all of these. cpu/memory is a good start for most use cases.
resourceQuotas:
# Enable Quotas or not. You can either disable it or remove the whole block
enabled: true
# limits of Pods, CPU, Memory, storage, secrets... etc. etc.
# Byte values will be replace: gi -> Gi, mi -> Mi
pods: 4 # <1>
cpu: 4
memory: 4Gi
ephemeral_storage: 4Gi
replicationcontrollers: 20
resourcequotas: 20
services: 100
secrets: 100
configmaps: 100
persistentvolumeclaims: 10
limits:
cpu: 4
memory: 4gi # lower case will be automatically replaced
ephemeral_storage: 4mi # lower case will be automatically replaced
requests:
cpu: 1
memory: 2Gi
storage: 50Gi
ephemeral_storage: 2Gi
# add here a list of your storage classes you would like to limit as well.
storageclasses:
# for example: Storageclass "bronze" has a request limit and a limit ov max. PVCs.
bronze.storageclass.storage.k8s.io/requests.storage: "10Gi"
bronze.storageclass.storage.k8s.io/persistentvolumeclaims: "10"
<1> List of hard limits currently supported by the Helm Chart. You only need to define the limits that you actually want to set.
Limit ranges
A limit range can restrict the consumption of a resource inside a project. Setting specific resource limits for a pod, container, image, image stream, or persistent volume claim (PVC) is possible.
Currently, the Helm Chart supports Container, Pods, and PVCs. Setting LimitRanges and convincing developers to set resources accordingly in their Kubernetes objects is recommended.
However, this is sometimes not the case. If you want to set a LimitRange, you can define the following block in the values-file:
# Limit Ranges, are optional, if not set here, then the default (very small ones) are used
limitRanges:
# Enable Quotas or not. You can either disable it or remove the whole block
enabled: true
pod: # <1>
max:
cpu: 4
memory: 4Gi
min:
cpu: 500m
memory: 500Mi
container: # <2>
max:
cpu: 4
memory: 4Gi
min:
cpu: 500m
memory: 500Mi
default:
cpu: 1
memory: 4Gi
defaultRequest:
cpu: 1
memory: 2Gi
pvc: # <3>
min:
storage: 1Gi
max:
storage: 20Gi
<1> LimitRanges for Pods.
<2> LimitRanges for Containers.
<3> LimitRanges for PVCs.
As for ResourceQuotas, only defined settings will be created. For example, if nothing is set for pod.max.cpu, then this value will be ignored.
Default Network Policies
NOTE: By default, the project admin role can modify Network Policies. This means they can change, create, or delete them. Creating a special Role in OpenShift that does not provide this privilege is recommended if Network Policies shall be managed at a central place and not by the project admins themselves.
Network Policies limit the allowed traffic for each Namespace and should be set from the beginning. They are individual for every project, but some default policies should be considered.
The five default policies that the Helm Chart would create if you do not disable them are:
- Allow Ingress traffic from OpenShift Router (aka allow external traffic to reach your application).
- Allow OpenShift Monitoring to fetch metrics.
- Allow communication inside one Namespace (pod to pod in the same Namespace).
- Allow Kube-API server to interact with the objects.
- Deny egress traffic to prevent any egress traffic at all.
The Helm chart will set them automatically unless otherwise defined in the values-file.
The following example would disable the "deny egress all" policy, which means that egress traffic to any destination is allowed.
# For example: I would like to disable "deny all egress" (which means the Pods can reach any external destination).
default_policies:
# disable_allow_from_ingress: false
# disable_allow_from_monitoring: false
# disable_allow_from_same_namespace: false
# disable_allow_kube_apiserver: false
disable_deny_all_egress: true # This default policy will not be created, while the others will be.
Additional Network Policies
It is possible to define additional Network Policies using the Helm Chart. At first look, these objects look quite complex (also on the second look). However, you can define a list of policies by defining a Name, podSelector, and Ingress or Egress Rules, which can have a podSelector as well, or a NamespaceSelector or simply an IP-Block and define a list of protocols and ports.
The example values-file defines two policies: netpol1 and netpol2.
NOTE: Working with Network Policies from the beginning of your Container journey is recommended. Adding them later might be very complex because nobody knows which sources or destinations shall be allowed.
NOTE: By default, the project admin role can modify Network Policies. This means it can change, create, or delete them. Creating a special Role that does not provide this privilege in OpenShift is recommended if Network Policies are managed centrally.
# Additional custom Network Policies
# I created this to be able to create Policies using a Helm chart. It might look complex but it is actually quite straight forward.
#
# 1. Defaine a PodsSelect (or use all pods see example 2)
# 2. Define Ingress rules with selectors and ports or IP addresses
# 3. Optionally define egress Rules
networkpolicies:
# List of NetworkPolicies to create with name and switch if active or not
- name: netpol1
active: true
# The PodSelect based on matchLabels. Could be empty as well
podSelector:
matchLabels:
app: myapplication
app2: myapplication2
# Incoming Rules, based on Port and Selectors (Pod and Namespace)
ingressRules:
- selectors:
- podSelector:
matchLabels:
app: myapplication
version: '1.0'
- namespaceSelector:
matchLabels:
testnamespace: "true"
ports:
- protocol: TCP
port: 443
# Outgoing Rules, based on Port and Selectors
egressRules:
- selectors: []
ports:
- port: 2
protocol: UDP
- ports:
- port: 443
protocol: TCP
selectors:
- podSelector:
matchLabels:
app: myapplication
version: '1.0'
# 2nd example
- name: netpol2
active: true
podSelector: {}
# Incoming Rules, based on ipBlock and Selectors
ingressRules:
- selectors:
- podSelector: {}
- namespaceSelector:
matchLabels:
testnamespace: "testnamespace"
- ipBlock:
cidr: 127.0.0.1/24
except:
- 127.0.0.2/32
ports:
- protocol: TCP
port: 443
Bring everything together
Mona and Peter requested the new Namespaces my-main-app-project-1 and my-main-app-project-2 for their project my-main-app. They defined the name, which group shall have access, and the quota and network policies they will require. Maybe they ordered such a project via some tooling, like Jira.
The cluster administrator created a new folder and a values-file that defines all required parameters.
NOTE: A full example can be found in my GitHub repository: values.yaml
The ApplicationSet will automatically fetch the new folder and create the Application inside Argo CD.
GitOps uses the Helm Chart and would like to create all requested objects.
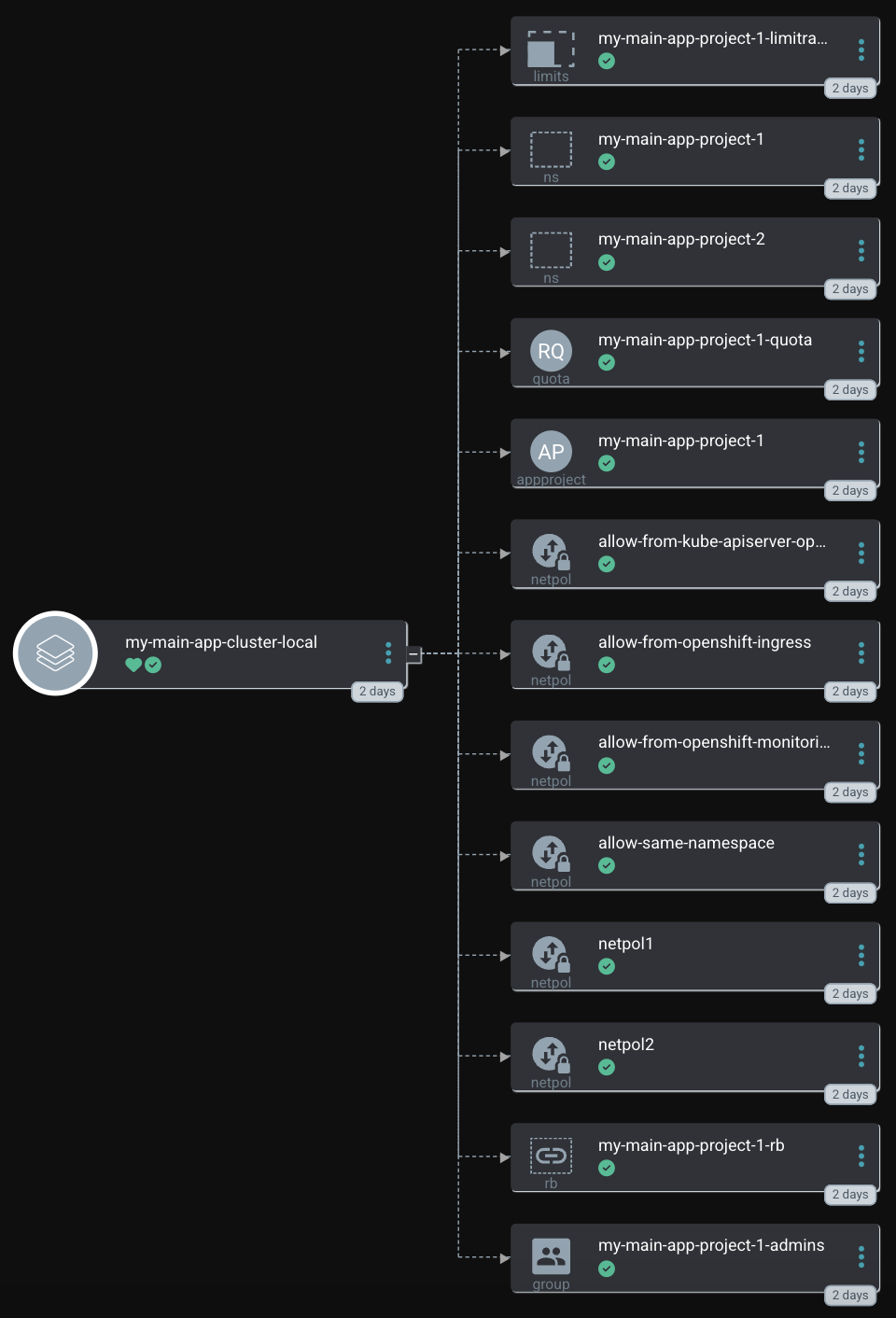
Once synchronized, Mona can log into the application-scoped GitOps instance, create the Applications she requires, and sync her workload onto the cluster. She is limited by the AppProject and can only use the allowed Namespaces, clusters, repositories, etc.

But isn't this quite complex?
Yes, defining everything in one file can be quite complex. Generating this file can be automated with Ansible, for example. Moreover, not everything must be used. For example, if you do not want to work with Quota or LimitRanges, just disable them or remove the block in the values-file. However, there is another method.
Project T-Shirt sizes
While working on this article and collecting feedback, a discussion about the possibility of defining T-Shirt sizes for a project started. Wouldn't it be good to define T-Shirt sizes with default settings and then use these definitions to create a new tenant? Still, the possibility to change settings for specific projects should be allowed.
I added this feature, and the configurations for each project are now simplified.
Values File: values-global.yaml with T-Shirt sized projects
The first change was done in the global values-files. The global settings allowed_source_repos and tshirt_sizes have been added. It now looks like the following:
---
global:
# Namespace of application scoped GitOps instance, that is responsible to deploy workload onto the clusters
application_gitops_namespace: gitops-application
# cluster environments. A list of clusters that are known in Argo CD
# name and url must be equal to what is defined in Argo CD
envs:
- name: in-cluster
url: https://kubernetes.default.svc
- name: prod-cluster
url: https://production.cluster
# Repositories projects are allowed to use. These are configured on a global level and used if not specified in a _T-Shirt_ project.
# Can be overwritten for projects in their specific values-file
allowed_source_repos: # <1>
- "https://myrepo"
- "https://the-second-repo"
tshirt_sizes: # <2>
- name: XL
quota:
pods: 100
limits:
cpu: 4
memory: 4Gi
requests:
cpu: 1
memory: 2Gi
- name: L
quota:
limits:
cpu: 2
memory: 2Gi
requests:
cpu: 1
memory: 1Gi
- name: S
quota: # <3>
limits:
cpu: 1
memory: 1Gi
requests:
cpu: 500m
memory: 1Gi
limitRanges: # <4>
container:
default:
cpu: 1
memory: 4Gi
defaultRequest:
cpu: 1
memory: 2Gi
<1> Repositories that are allowed inside the AppProject. It can be overwritten for individual projects.
<2> T-Shirt sizes for projects. Currently defined: XL, L, S.
<3> Default Quota settings for the S-Size.
<4> Default LimitRanges for the S-Size.
Values file: values.yaml with T-Shirt-sized projects
Like the global values-file, the values-file for the individual project on the specific cluster is slightly changed.
It can now define the parameter project_size, which must be one of the sizes defined in the global values-file. LimitRanges, ResourceQuota, and the list of allowed repositories set here will overwrite the default settings (only the values set here will overwrite the defaults). The management of NetworkPolicies (default or custom) stays the same. For the Argo CD RBAC definition, default values are used, but it would still be possible to define the whole block as described above (but keep it simple).
# Group that is allowed in RBAC. This group can either be created using this Helm Chart (will be named as <namespace>-admin) or must be known (for example synced via LDAP Group Sync)
oidc_groups: &oidc-group my-tshirt-size-app-admins
# Environment to which these values are valid, this should be the cluster name as defined in the values-global.yaml
# In best case the same is equal to the folder we are currntly in, but this is optional.
environment: &environment in-cluster
# Parameters handed over to Sub-Chart helper-proj-onboarding
helper-proj-onboarding:
environment: *environment
# List of namespaces this tenant shall manage.
# A tenant or project may consist of multiple namespace
namespaces:
# Name of the first Namespace
- name: &name my-tshirt-size-app
# Is this Namespace enabled or not
enabled: true
project_size: "S" # <1>
# Override specific quota settings individually
resourceQuotas: # <2>
limits:
cpu: 10
local_admin_group: # <3>
enabled: true
# group_name: my_group_name
# optional parameter, default would be "admin"
clusterrole: admin
# List of users
users:
- mona
- peter
# Allowed repositories for this project, overwrites the default settings.
# allowed_source_repos: # <4>
# - "https://my-personal-repo"
# - "https://my-second-personal-repo"
# Network Policies ... these are a bit more complex, when you want to keep them fully configurable.
# Maybe the following is too much to manage, anyway, let's start
# 5 default network policies will be created everytime, unless you overwrite them here
# You can remove this whole block to have the policies created or you can select specific policies
# which shall be disabled.
# The 5 policies are:
# - Allow Ingress traffic from the OpenShift Router
# - Allow OpenShift Monitoring to access and fetch metrics
# - Allow inner namespace communication (pod to pod of the same Namespace)
# - Allow Kube API Server
# - Forbid ANY Egress traffic
# For example: I would like to disable "deny all egress" (which means the Pods can reach any external destination).
default_policies: # <5>
# disable_allow_from_ingress: false
# disable_allow_from_monitoring: false
# disable_allow_from_same_namespace: false
# disable_allow_kube_apiserver: false
disable_deny_all_egress: true # This default policy will not be created, while the others will be.
# Overwrite LimitRanges per project
limitRanges: # <6>
enabled: true
container:
max:
cpu: 4
memory: 10Gi
min:
cpu: 1
memory: 100Mi
<1> T-Shirt size as defined in the global values-files.
<2> Overwrite specific values for ResourceQuota.
<3> Define Group administrator.
<4> Overwrite the allowed repository list.
<5> Default NetworkPolicies, that might be disabled.
<6> Overwrite specific values for LimitRanges.
Like the other project onboardings, the ApplicationSet will automatically fetch it:
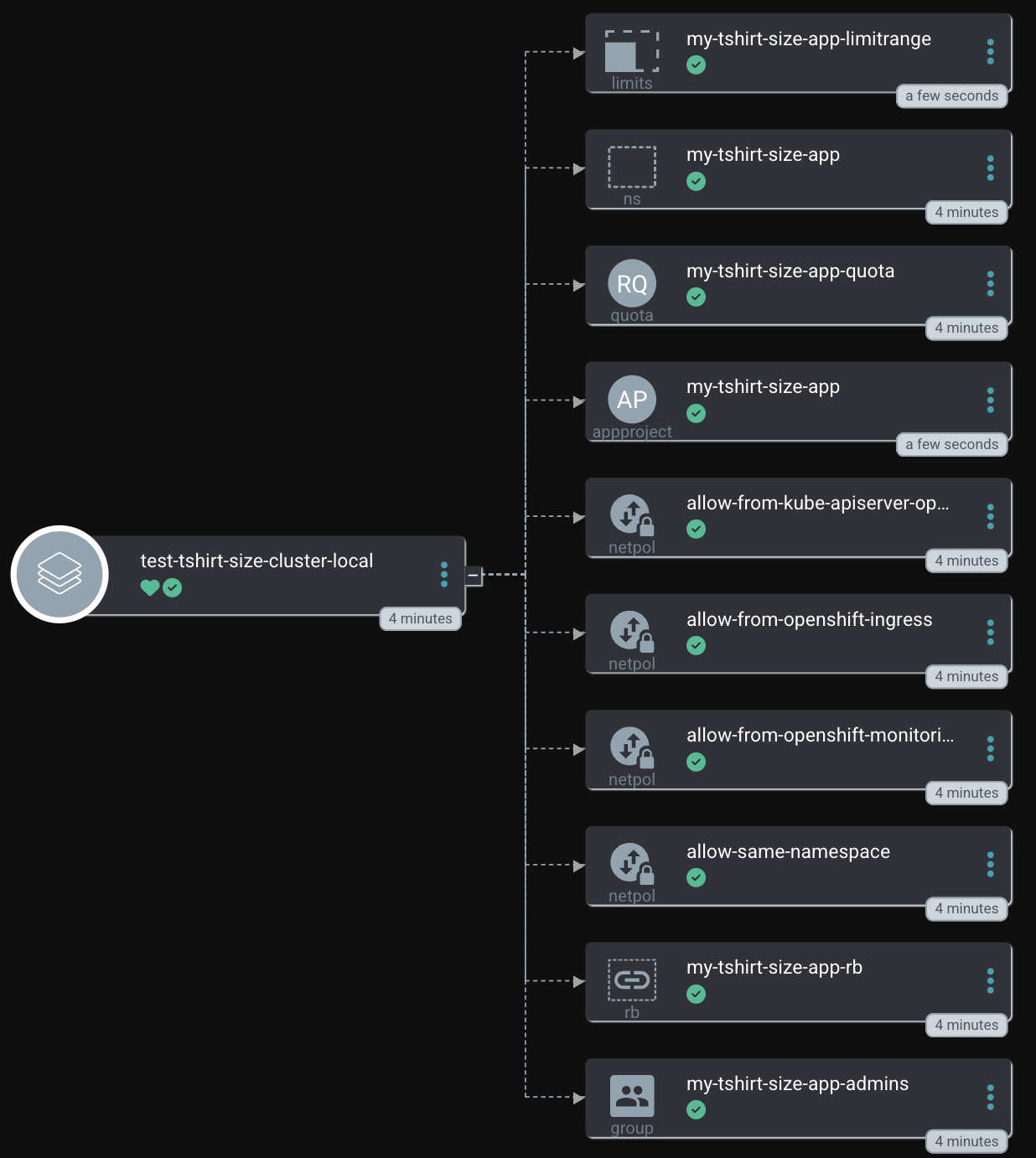
To use the power of labels, the actual T-Shirt size is added to the Namespace object:
apiVersion: v1
kind: Namespace
metadata:
labels:
[...]
namespace-size: S
name: my-tshirt-size-app
Summary
This article covers how to onboard new projects into OpenShift using a GitOps approach. It is one option of many. I prefer Helm Charts over plain YAML or Kustomize because they can be repeated anytime. However, Kustomize or YAML will also work. The most important part is not the actual tool but that all objects and any configurations are defined in Git, where a GitOps agent (in this case, Argo CD) can fetch them and sync them onto the cluster.
저자 소개
유사한 검색 결과
에이전틱 패러독스와 하이브리드 AI의 필요성
과거의 운영 방식에서 벗어나 IT의 미래 구축
Edge computing covered and diced | Technically Speaking
SREs on a plane | Technically Speaking
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래