
Experienced sysadmins will usually customize their Linux systems to suit their needs and to create a consistent environment. But what if you are working in an environment where you do not have the authority to make permanent changes? Or you are just helping someone from another department? Sometimes the other server may be running a different "flavor" of Linux or even a different type of Unix.
Here are some quick and dirty tricks that can be useful in some practical situations.
[ Readers also liked: More stupid Bash tricks: Variables, find, file descriptors, and remote operations ]
Know the rules and know when to break rules
Variables should have clear names to make them easy to understand, to be self-documented, and to keep our mental health. I suppose everybody agrees with that.
But sometimes, you are pressed to troubleshoot a production issue in the middle of the night, and you want to move fast.
Other times you also need to save some typing because you know you will need to run some long commands multiple times. In a normal situation, you would create aliases and put them in your login profiles. However, we are talking about an unfamiliar environment here, when you are focusing on resolving the incident.
The classic case of "too many network connections going wild"
You're paged at 2 AM because "something" isn't working. Everything worked normally until this night.
Starting with some variation of the ss command (or netstat, if you are a little older, like me), you notice hundreds of connections in a TIME-WAIT and CLOSE-WAIT in your main server.
Note: In the animation below, we use the ss -4a command to list all the IPv4 connections. But we are more interested in the ones that are in WAIT state:
You can see that all those connections seem to point to port 50505 in at least two servers. The destination IP and port are in Field #6. See the image below.
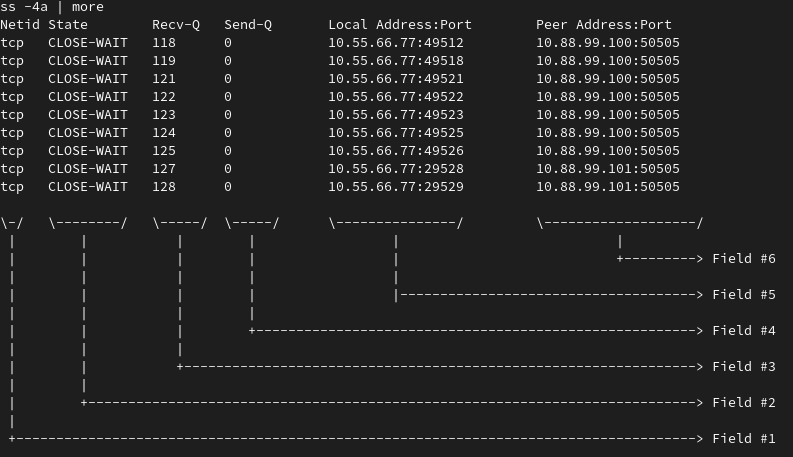
Now you want to find out how many connections are pending for each target IP.
We can accomplish this by tweaking the ss command that we used previously:
The sequence of steps is the following:
- We start reviewing the header and first 10 lines using the command
ss -4a | grep WAIT | head - Then we
pipethat toawk, which in this case is used to print field #6 (we are assuming that spaces are the default separator). - After that, we
sortthe previous output because next, we want to have a count of the distinct destination servers involved. - Finally, we use
uniq -cto present the count of unique lines. As we are in the final step for this task, we need to remove theheadcommand we have been using while we were constructing the output.
At this point in the investigation, you can start to make some correlations, such as, "The other two destinations are affected, so the root cause is either at the cluster level or network/firewall related."
There are certainly ways to customize the output of ss to show only the column you are interested in. But it may be something that you may not want to search at 2 AM. This was just one example, and in many other situations, you will have other commands with multiple options.
Here, the idea is to show a quick way to work with the output that is probably familiar to you, from some commands that you already used (but you do not need or want to memorize ALL the possible ways to configure their output).
The classic case of "low free disk space"
Another example from real life: You are troubleshooting an issue and find out that one file system is at 100 percent of its capacity.
There may be many subdirectories and files in production, so you may have to come up with some way to classify the "worst directories" because the problem (or solution) could be in one or more.
In the next example, I will show a very simple scenario to illustrate the point.
The sequence of steps is:
- We go to the file system where the disk space is low (I used my home directory as an example).
- Then, we use the command
df -k *to show the sizes of directories in kilobytes. - That requires some classification for us to find the big ones, but just
sortis not enough because, by default, this command will not treat the numbers as values but just characters. - We add
-nto thesortcommand, which now shows us the biggest directories. - In case we have to navigate to many other directories, creating an
aliasmight be useful.
[ Learn the basics of using Kubernetes in this free cheat sheet. ]
Wrap up
There are commands that are useful in different situations, such as grep, awk, sort. Knowing some basic options and combining them can be very effective when you need to manipulate and simplify output from other commands or when processing text files.
These commands exist in almost every Unix variation, old or new, which makes it beneficial to have them in your bag of tricks. You never know when these tools will save your life (wink).
저자 소개
Roberto Nozaki (RHCSA/RHCE/RHCA) is an Automation Principal Consultant at Red Hat Canada where he specializes in IT automation with Ansible. He has experience in the financial, retail, and telecommunications sectors, having performed different roles in his career, from programming in mainframe environments to delivering IBM/Tivoli and Netcool products as a pre-sales and post-sales consultant.
Roberto has been a computer and software programming enthusiast for over 35 years. He is currently interested in hacking what he considers to be the ultimate hardware and software: our bodies and our minds.
Roberto lives in Toronto, and when he is not studying and working with Linux and Ansible, he likes to meditate, play the electric guitar, and research neuroscience, altered states of consciousness, biohacking, and spirituality.
유사한 검색 결과
Red Hat Enterprise Linux의 이미지 모드를 지금 바로 사용해야 하는 4가지 이유
Red Hat Enterprise Linux, 양자 컴퓨팅 시대를 대비한 SSH 보안 역량 강화
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래