Introduction
Some time ago, I published an article about the idea of self-hosting a load balancer within OpenShift to meet the various requirements for ingress traffic (master, routers, load balancer services). Since then, not much has changed with regards to the load balancing requirements for OpenShift. However, in the meantime, the concept of operators, as an approach to capture automated behavior within a cluster, has emerged. The release of OpenShift 4 fully embraces this new operator-first mentality.
Prompted by the needs of a customer, additional research on this topic was performed on the viability of deploying a self-hosted load balancer via an operator.
The requirement is relatively simple: an operator watches for the creation of services of type LoadBalancer and provides load balancing capabilities by allocating a load balancer in the same cluster for which the service is defined.
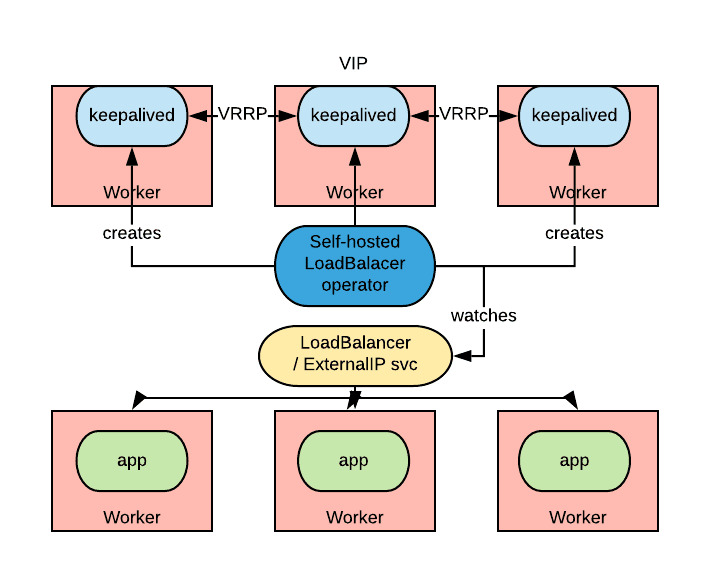
In the diagram above, an application is deployed with a LoadBalancer type of service. The hypothetical self-hosted load balancer operator is watching for those kinds of services and will react by instructing a set of daemons to expose the needed IP in an HA manner (creating effectively a Virtual IP [VIP]). Inbound connections to that VIP will be load balanced to the pods of our applications.
In OpenShift 4, by default, the router instances are fronted by a LoadBalancer type of service, so this approach would also be applicable to the routers.
In Kubernetes, a cloud provider plugin is normally in charge of implementing the load balancing capability of LoadBalancer services, by allocating a cloud-based load balancing solution. Such an operator as described previously would enable the ability to use LoadBalancer services in those deployments where a cloud provider is not available (e.g. bare metal).
Metallb
Metallb is a fantastic bare metal-targeted operator for powering LoadBalancer types of services.
It can work in two modes: Layer 2 and Border Gateway Protocol (BGP) mode.
In layer 2 mode, one of the nodes advertises the load balanced IP (VIP) via either the ARP (IPv4) or NDP (IPv6) protocol. This mode has several limitations: first, given a VIP, all the traffic for that VIP goes through a single node potentially limiting the bandwidth. The second limitation is a potentially very slow failover. In fact, Metallb relies on the Kubernetes control plane to detect the fact that a node is down before taking the action of moving the VIPs that were allocated to that node to other healthy nodes. Detecting unhealthy nodes is a notoriously slow operation in Kubernetes which can take several minutes (5-10 minutes, which can be decreased with the node-problem-detector DaemonSet).
In BGP mode, Metallb advertises the VIP to BGP-compliant network routers providing potentially multiple paths to route packets destined to that VIP. This greatly increases the bandwidth available for each VIP, but requires the ability to integrate Metallb with the router of the network in which it is deployed.
Based on my tests and conversations with the author, I found that the layer 2 mode of Metallb is not a practical solution for production scenarios as it is typically not acceptable to have failover-induced downtimes in the order of minutes. At the same time, I have found that the BGP mode instead would much better suit production scenarios, especially those that require very large throughput.
Back to the customer use case that spurred this research. They were not allowed to integrate with the network routers at the BGP level, and it was not acceptable to have a failover downtime of the order of minutes.
What we needed was a VIP managed with the VRRP protocol, so that it could failover in a matter for milliseconds. This approach can easily be accomplished by configuring the keepalived service on a normal RHEL machine. For OpenShift, Red Hat has provided a supported container called ose-keepalived-ipfailover with keepalived functionality. Given all of these considerations, I decided to write an operator to orchestrate the creation of ipfailover pods.
Keepalived Operator
The keepalived operator works closely with OpenShift to enable self-servicing of two features: LoadBalancer and ExternalIP services.
It is possible to configure OpenShift to serve IPs for LoadBalancer services from a given CIDR in the absence of a cloud provider. As a prerequisite, OpenShift expects a network administrator to manage how traffic destined to those IPs reaches one of the nodes. Once reaching a node, OpenShift will make sure traffic is load balanced to one of the pods selected by that given service.
Similarly for ExternalIPs, additional configurations must be provided to specify the CIDRs range users are allowed to pick ExternalIPs from. Once again, a network administrator must configure the network to send traffic destined to those IPs to one of the OpenShift nodes.
The keepalived operator plays the role of the network administrator by automating the network configuration prerequisites.
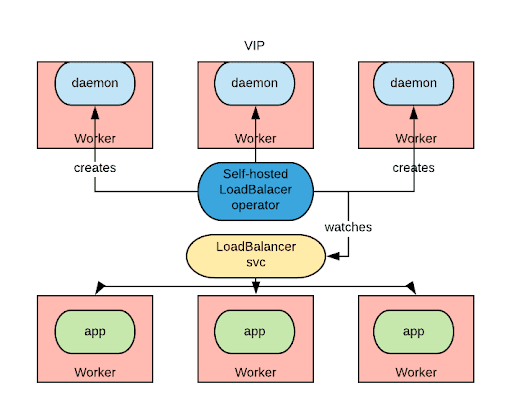
When LoadBalancer services or services with ExternalIPs are created, the Keeplived operator will allocate the needed VIPs on a portion of the nodes by adding additional IPs on the node’s NICs. This will draw the traffic for those VIPs to the selected nodes.
VIPs are managed by a cluster of ipfailover pods via the VRRP protocol, so in case of a node failure, the failover of the VIP is relatively quick (in the order of hundreds of milliseconds).
Installation
To install the Keepalived operator in your own environment, consult the documentation within the GitHub repository.
Conclusions
The objective of this article was to provide an overview of options for self-hosted load balancers that can be implemented within OpenShift. This functionality may be required in those scenarios where a cloud provider is not available and there is a desire to enable self-servicing capability for inbound load balancers.
Neither of the examined approaches allows for the definition of a self-hosted load balancer for the master API endpoint. This remains an open challenge especially with the new OpenShift 4 installer. I would be interested in seeing potential solutions in this space.
저자 소개

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래