
여러분의 프라이빗 클라우드가 마치 마음껏 이용하는 뷔페처럼 느껴지시나요? 프라이빗 클라우드가 가치를 제공하고 있다는 것은 알지만, 청구서가 발행되면 누가 무엇을 소비했는지 파악하기란 거의 불가능합니다.
특히 자체 클라우드 인프라를 운영하는 기업의 경우, 오늘날의 동적인 클라우드 환경에서 내부 사용자에게 비용을 적절히 귀속시키는 역량이 점점 더 중요해지고 있습니다. 부서 간에 비용을 공정하게 배분하거나 각 팀이 워크로드 크기를 적절히 조정하도록 장려하려면 책임 소재를 명확히 해야 하며, 가시성 확보가 그 첫 번째 단계입니다.
Red Hat OpenStack Services on OpenShift 18의 기능 릴리스 5(FR5)에서는 이러한 문제를 해결하는 데 도움이 될 중요한 기능인 테넌트의 측정된 사용량 기반 요금 책정 기능을 제공합니다.
FR5에서 정식 버전(GA)으로 출시되는 OpenStack 네이티브 요금 책정 서비스인 CloudKitty를 소개합니다. 이 서비스는 가공되지 않은 기술 메트릭과 재무 운영 간의 격차를 해소합니다.
CloudKitty가 중요한 이유
CloudKitty는 서버 사용량 데이터를 부서별 예산 수립에 활용할 수 있는 정보로 변환해 주는 변환 계층을 제공합니다. CloudKitty를 계량기 검침원으로 생각해 보세요. 이 서비스는 수집된 메트릭과 FinOps 또는 청구 솔루션 사이에 위치합니다. 이 서비스는 가상 머신(VM)의 가동 시간이나 스토리지 사용량 같은 가공되지 않은 기술 데이터를 가져와, 설정된 특정 요금 책정 규칙을 적용하여 리포트를 생성합니다. 이를 통해 다음 두 가지 주요 목표를 달성할 수 있습니다.
- 투명한 비용 회수: 이제 테넌트별 리소스 사용량에 대한 명확한 항목별 상세 내역을 확인할 수 있습니다. 이를 통해 불투명한 요금 청구로 내부 고객을 당황하게 만들지 않으면서도 운영 비용을 정확하게 회수할 수 있습니다.
- 신뢰와 최적화: 테넌트가 프로젝트, 플레이버, 메트릭별로 분류된 자체 리소스 소비가 비용에 미치는 영향을 확인하면, 오래된 데이터를 아카이빙하거나 VM 사용을 최적화하는 등 정보에 입각한 의사 결정을 내릴 수 있습니다.
CloudKitty는 순전히 가시성 확보와 요금 책정 엔진 역할만 수행한다는 점에 유의하세요. 테넌트가 특정 비용 임계값을 초과하더라도 예산을 강제로 집행하거나 리소스(예: Nova 인스턴스) 생성을 차단하지는 않습니다.
CloudKitty 작동 방식
CloudKitty는 완전한 청구 솔루션은 아니지만, 사용량과 비용 사이의 핵심적인 연결 고리 역할을 합니다. 간단히 요약한 워크플로우는 다음과 같습니다.
요금 책정 규칙 설정 → 메트릭 수집 → 요금 책정 리포트 생성
규칙 설정
가상의 고객 명단에 있는 샘플 테넌트인 '데이터부(Ministry of Data)'를 예로 들어 보겠습니다. 그동안 데이터부에서는 분석 워크로드를 위해 대규모 VM을 가동해 왔으며, 계산이 완료된 후에도 오랫동안 실행 상태로 방치하곤 했습니다.
투명한 비용 회수를 하려면 데이터부의 컴퓨팅 풋프린트를 추적해야 합니다. 이를 위해 ceilometer_cpu 메트릭을 추적합니다. 이 메트릭을 사용하면 플레이버 기반의 가동 시간을 측정할 수 있습니다. 즉, VM 인스턴스가 가동되는 시간 동안 CloudKitty가 VM 크기에 따라 서로 다른 요율을 적용해 요금을 계산할 수 있게 됩니다.
1단계: 서비스 생성
먼저 지표를 위한 최상위 컨테이너를 생성해야 합니다. 서비스 이름은 지표 이름 또는 metrics.yaml에 정의된 alt_name과 정확히 일치해야 합니다. (이 파일에 대해서는 나중에 더 자세히 다루겠습니다.)
openstack rating hashmap service create ceilometer_cpu
+----------+--------------------------------------+
| Name | Service ID |
+----------+--------------------------------------+
| ceilometer_cpu | <uuid> |
+----------+--------------------------------------+위의 Service ID(UUID)를 저장해 두세요. 다음 명령을 실행할 때 이 ID가 필요합니다!
ceilometer_cpu라는 서비스를 생성하면 수집기에서 들어오는 모든 CPU 데이터 포인트를 이 새로운 평가 규칙으로 직접 라우팅할 수 있습니다.
2단계: 그룹 생성(선택 사항)
데이터부의 컴퓨팅 요금이 스토리지 또는 네트워킹 요금과 섞이지 않도록 해야 합니다. 그룹을 사용하면 관련 매핑을 정리하고 계산을 서로 격리하는 데 도움이 됩니다.
openstack rating hashmap group create cpu_rating이러한 매핑을 그룹화하면 다양한 청구 시나리오를 분리할 수 있습니다. 동일한 그룹 내에서 여러 매핑이 일치하는 경우 CloudKitty는 가장 비용이 높은 매핑만 적용합니다.
3단계: 매핑 생성
매핑은 비용 규칙입니다. 먼저 항목당 고정 비용을 청구하여 데이터부의 기준을 설정해 보겠습니다. 이전 단계에서 반환된 UUID를 <service_id> 및 <group_id> 대신 입력하면 이 새 규칙을 ceilometer_cpu 서비스 및 cpu_rating 그룹에 직접 연결할 수 있습니다.
openstack rating hashmap mapping create 0.02 \
-s <service_id> \
-g <group_id> \
-t flat이 시나리오에서 0.02는 수집 주기(기본값은 매시간)당 0.02 단위를 의미합니다. 각 CPU 인스턴스에는 사용량에 관계없이 0.02 단위의 고정 요금을 부과합니다.
4단계: 필드 기반 평가 (비밀 무기)
데이터부(Ministry of Data)는 리소스를 많이 소모하는 대규모 데이터베이스 노드와 함께 소규모 웹 서버를 운영합니다. 모든 항목에 일괄적으로 고정 요금을 청구하는 것은 공정하지 않습니다. 사용자가 사용하는 각 VM 플레이버에 따라 요금을 다르게 청구하고자 합니다.
먼저 메타데이터 키를 참조하는 필드를 생성합니다.
openstack rating hashmap field create <service_id> flavor_id그런 다음 해당 플레이버 값에 대한 특정 매핑을 생성합니다.
openstack rating hashmap mapping create 0.05 \
--field-id <field_id> \
--value <flavor_uuid> \
-t flat현재 환경에서 사용할 수 있는 모든 플레이버에 대해 이 매핑 생성 작업을 반복합니다. 특정 VM 크기가 실행 중일 때 과금 서비스가 어떤 요율을 적용하여 계산할지 알 수 있도록 각 플레이버에 대한 새 규칙을 생성합니다.
결과는 다음과 같습니다. 연동 방식
월말이 되어 데이터부(Ministry of Data)에서 사용량 조회를 요청하면, CloudKitty는 위에서 생성한 규칙을 다음과 같이 처리합니다.
ceilometer_cpu (metric)
└─> Service: ceilometer_cpu
└─> Field: flavor_id (optional)
└─> Mapping: m1.tiny = 0.01, m1.large = 0.05
└─> Mapping (direct): 0.02 flat측정할 수 있다면 과금할 수 있습니다
데이터부(Ministry of Data)의 CPU 사용량(ceilometer_cpu)을 기본 예시로 활용했지만, 컴퓨팅은 전체 그림의 일부에 불과합니다. Red Hat OpenStack Services on OpenShift에서 CloudKitty의 진정한 장점은 Prometheus와의 통합에 있습니다.
이미 수집된 지표는 무엇이든 요금 책정에 활용할 수 있습니다. 즉, 위에서 설명한 것과 동일한 단계를 진행하여 나머지 테넌트 리소스 영역에 대한 과금 규칙을 쉽게 생성할 수 있습니다. 예를 들어 다음과 같은 항목에 대한 비용 매핑을 생성할 수 있습니다.
- 블록 스토리지:
ceilometer_disk_device_capacity를 사용하여 GB-월 용량 추적 - 네트워킹:
ceilometer_ip_floating을 사용하여 할당된 외부 공개 IP 주소 요금 청구 - 아웃바운드 대역폭:
ceilometer_network_outgoing_bytes를 사용하여 VM의 총 아웃바운드 트래픽 요금 책정
CloudKitty가 Prometheus에서 해당 범위의 데이터를 가져오면, 프로세서는 사용자 정의 요금 책정 규칙을 적용한 뒤 최종 산정된 메트릭을 스토리지 백엔드로 직접 전송합니다. CloudKitty는 가공되지 않은 기술 텔레메트리 데이터와 FinOps 리포팅을 연결하는 최고의 자동화 가교 역할을 합니다.
과금 리포트 생성: 결정적인 순간
Prometheus에서 규칙을 생성하고 메트릭을 수집한 후, 마지막 단계로 요금이 책정된 데이터를 추출합니다.
CloudKitty는 청구서 발행 시스템이 아니라는 점에 유의하시기 바랍니다. 시각적으로 보기 좋은 PDF 청구서를 직접 생성하지는 않습니다. 그 대신, REST API 또는 OpenStack 클라이언트를 통해 파싱하기 쉬운 정제된 JSON 데이터를 제공하는 강력한 데이터 엔진 역할을 하도록 설계되었습니다. 이를 통해 요금이 산정된 데이터를 기업의 기존 FinOps, 쇼백 또는 청구 미들웨어에 더욱 쉽게 직접 연동할 수 있습니다.
테넌트 관점: 데이터부(Ministry)가 사용 내역 확인
CloudKitty에는 테넌트 인식(tenant-aware) 액세스 제어 기능이 내장되어 있습니다. 데이터부가 현재 사용량을 확인하고자 할 때는 자체 프로젝트의 사용 내역에만 액세스할 수 있습니다. 다른 테넌트의 데이터를 조회하려는 모든 시도는 API가 자동으로 차단하거나 무시합니다.
데이터부는 OpenStack 클라이언트를 사용하여 월별 요약을 확인할 수 있습니다.
# Get summary for a specific month
openstack rating summary get --begin 2026-02-01 --end 2026-03-01관리자 관점: 전체적인 관점
데이터부는 자체 사용 내역 조회로 제한되는 반면, 클라우드 관리자는 용량을 관리하고 전체 차지백을 수행하기 위해 전체 환경을 종합적으로 볼 수 있어야 합니다.
운영자는 관리자 토큰을 사용하여 전체 가시성을 확보할 수 있습니다. 운영자는 --tenant-id <project_uuid>를 사용하여 특정 테넌트만 조회하도록 명령어를 확장할 수 있습니다.
openstack rating summary get \
--begin 2026-02-01 \
--end 2026-03-01 \
--tenant-id <project_uuid>또는 FinOps 팀이 청구 시스템으로 내보내기 위해 전체 현황을 파악해야 하는 경우, 관리자는 --all-tenants 플래그를 사용하여 전체 클라우드에 대한 요율 산정 데이터를 한 번에 가져올 수 있습니다.
FinOps 솔루션에 직접 연결
FinOps 미들웨어가 프로그래밍 방식으로 이 데이터를 가져오는 경우, REST API를 사용하여 앞서 구성한 특정 서비스 유형(예: ceilometer_cpu)별로 그룹화된 상세 내역을 요청할 수 있습니다.
curl -X GET \
-H "X-Auth-Token: $TENANT_TOKEN" \
"http://localhost:8888/v1/report/summary?begin=2026-02-01T00:00:00&end=2026-03-01T00:00:00&groupby=res_type"그 결과 반환되는 JSON 출력은 리소스 유형, 기간, 계산된 총 단위를 명확하게 보여줍니다
{
"summary": [
{
"tenant_id": "MoD-project-uuid",
"res_type": "ceilometer_cpu",
"begin": "2026-02-01T00:00:00",
"end": "2026-03-01T00:00:00",
"rate": 125.50
}
]
}이처럼 구조화되고 집계된 JSON 데이터를 기업의 전반적인 재무 소프트웨어에 직접 연동함으로써, 실제 인프라 소비와 비용 책무성 간의 긴밀한 연결고리를 성공적으로 완성할 수 있습니다.
내부 구조 살펴보기
오퍼레이터의 관점에서 CloudKitty가 어떻게 작동하는지 살펴보았으니, 이제 내부를 열어 그 안에 있는 핵심 엔진을 알아보겠습니다. 아키텍처를 이해하면 확장성을 예측하고, 문제를 해결하며, 특정 설계 결정이 내려진 배경을 파악하는 데 도움이 됩니다.
아키텍처 개요
CloudKitty는 서로 다른 역할을 담당하는 2개의 독립적인 프로세스로 실행됩니다.
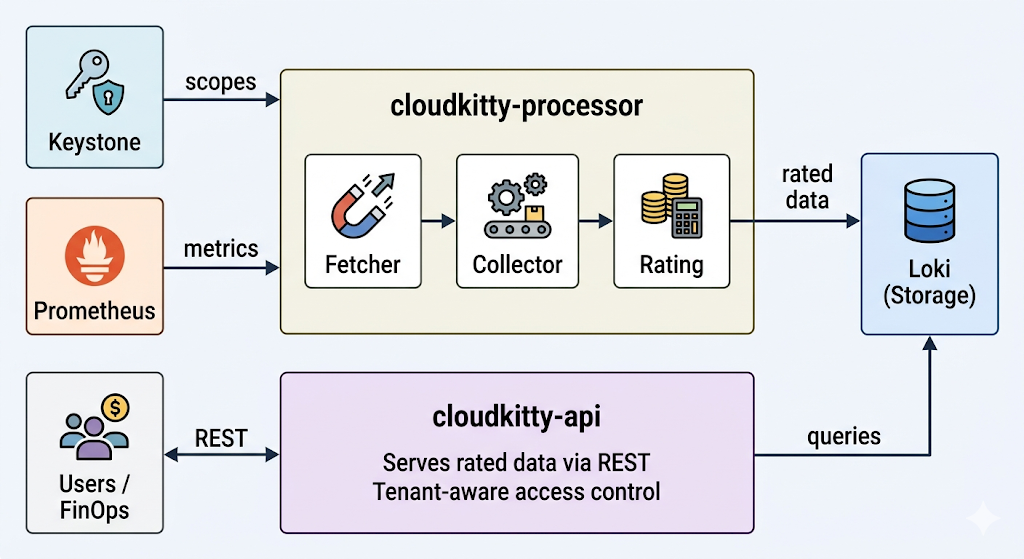
그림 1. CloudKitty 아키텍처. cloudkitty-processor는 Keystone에서 범위를, Prometheus에서 지표를 가져와 데이터를 평가하여 Loki에 저장합니다. cloudkitty-api는 REST를 통해 Loki의 과금 데이터를 사용자와 FinOps 툴에 제공합니다.
cloudkitty-processor는 과금 엔진입니다. 매 수집 주기마다(기본값: 1시간) 4단계 파이프라인을 실행합니다.
- 가져오기(Fetch): 평가할 OpenStack 프로젝트(범위) 목록을 Keystone에 요청합니다.
- 수집(Collect): 각 범위에 대해
metrics.yaml에 정의된 원시 지표 값을 Prometheus에 쿼리합니다. - 과금(Rate): 해시맵 규칙(이전에 구성한 서비스, 필드, 매핑)을 적용하여 원시 사용량을 과금 데이터로 변환합니다.
- 저장(Store): 영구 보존을 위해 생성된 과금 데이터프레임을 Loki로 전송합니다.
cloudkitty-api는 REST 프런트엔드입니다. 이 API는 테넌트, 관리자, 그리고 외부 FinOps 툴로부터 들어오는 모든 쿼리를 처리합니다. 사용자가 과금 요약을 요청하면 Loki를 조회하여 결과를 반환합니다. 이 프로세스는 스테이트리스(Stateless) 방식으로 작동하며, 더 많은 동시 요청을 처리하기 위해 수평으로 확장할 수 있습니다.
두 프로세스는 서로 분리되어 있으므로 독립적으로 확장할 수 있습니다. 즉, API 복제본을 추가하여 쿼리 부하를 처리하거나, 프로세서의 병렬 처리를 조정하여 더 많은 범위를 동시에 평가할 수 있습니다.
Loki를 사용하는 이유
Grafana Loki는 주로 로그 집계 시스템으로 알려져 있어 이를 과금 데이터의 스토리지 백엔드로 사용하는 것이 이례적인 선택으로 보일 수 있지만, 실제로는 매우 적합합니다.
- 시간 기반(Time-series) 네이티브: 과금 데이터는 본질적으로 시간적 특성을 지니며, 수집 주기당 범위별 비용을 나타냅니다. Loki는 구조화된 스트림을 대상으로 효율적인 시간 범위 쿼리를 수행할 수 있도록 설계되었습니다.
- 이미 존재하는 스택: OpenStack Services on OpenShift 배포에는 로그 관리를 위한 LokiStack이 이미 포함되어 있습니다. CloudKitty는 동일한 오퍼레이터 관리형 인프라를 재사용하므로, 추가로 데이터베이스를 배포하거나 유지 관리할 필요가 없습니다.
- 오브젝트 스토리지 기반: Loki는 S3 호환 오브젝트 스토리지에 데이터를 영구 저장하여 운영 풋프린트를 최소한으로 유지하므로, 추가로 관리해야 할 PVC나 데이터베이스 클러스터가 없습니다.
- 구조화된 메타데이터: 향후 CloudKitty는 인덱싱된 메타데이터(테넌트, 지표 유형, 플레이버)를 각 로그 항목에 직접 저장할 예정입니다. 이를 통해 전체 JSON 파싱 없이 필터링된 쿼리를 빠르게 실행할 수 있어, 대규모 환경에서 쿼리 성능이 크게 향상됩니다.
지표 구성
수집 단계의 핵심은 metrics.yaml입니다. 이 파일은 CloudKitty에 수집할 Prometheus 지표와 이를 처리하는 방법을 알려줍니다. 다음은 기본 제공되는 구성에서 발췌한 대표적인 예시입니다.
metrics:
ceilometer_cpu:
unit: instance
alt_name: instance
groupby:
- resource
- user
- project
- flavor_name
- flavor_id
mutate: NUMBOOL
extra_args:
aggregation_method: max
ceilometer_image_size:
unit: MiB
factor: 1/1048576
groupby:
- resource
- project
metadata:
- container_format
- disk_format
extra_args:
aggregation_method: max각 항목은 CloudKitty가 특정 Prometheus 지표를 수집하고 해석하는 방법을 제어합니다:
unit: 과금 리포트에 표시되는 과금 단위(예: instance, GiB, B, ip)입니다.alt_name: 메트릭의 대체 이름입니다. 해시맵 서비스를 생성할 때 Prometheus 지표 이름(ceilometer_cpu) 또는alt_name(instance)를 사용할 수 있습니다.groupby: 메트릭을 분리하는 데 사용되는 Prometheus 레이블입니다. ceilometer_cpu의 경우 flavor_name 및 flavor_id를 기준으로 그룹화하면 이전에 구성한 플레이버 기반 평가 규칙이 활성화됩니다.mutate: 원시 값에 적용된 변환입니다. NUMBOOL은 0이 아닌 모든 값을 1로 변환하므로 "이 리소스가 활성 상태인가요?"라는 의미에 완전히 부합합니다. 즉, 원시 CPU 카운터는 고려하지 않고 인스턴스가 실행 중인지 여부만 확인합니다.factor: 단위 변환을 위한 곱셈 계수입니다. 예를 들어ceilometer_image_size는 1/1048576을 사용하여 원시 바이트를 MiB로 변환합니다.metadata: 정보 제공을 목적으로 과금 데이터에 전달할 추가 Prometheus 레이블입니다(예: 이미지의 경우container_format,disk_format).extra_args: 백엔드별 추가 인자(Back end-specific arguments)입니다.aggregation_method: max는 Prometheus 수집기가 각 수집 주기 내에서 최댓값을 사용하도록 지정합니다.
CloudKitty 수집기는 Prometheus와 직접 통신하므로, 사용 가능한 모든 지표를 쉽게 평가할 수 있습니다. 적절한 레이블과 단위를 포함한 새 항목을 metrics.yaml에 추가하면 CloudKitty가 다음 처리 주기부터 수집 및 과금을 시작합니다.
원시 데이터 검사
openstack rating summary get 명령을 사용하면 집계된 총계를 확인할 수 있지만, 가끔은 더 자세히 살펴봐야 할 수도 있습니다. 과금 규칙이 올바르게 적용되는지 확인하거나, 누락된 지표를 디버깅하거나, CloudKitty에 저장되는 내용을 파악하려는 경우, openstack rating dataframes get 명령을 사용하여 Loki에 저장된 개별 과금 데이터 포인트를 검사할 수 있습니다.
요약을 월별 명세서로, 데이터프레임을 영수증의 개별 항목으로 생각하면 됩니다.
특정 기간의 평가된 원시 데이터프레임을 검색하려면 다음 명령을 실행합니다.
openstack rating dataframes get --begin 2026-03-01T00:00:00Z --end 2026-03-01T01:00:00Z출력의 각 행은 1회의 수집 기간 동안 평가된 단일 데이터 포인트를 나타냅니다.
| 시작 | 종료 | 메트릭 유형 | 단위 | 수량 | 가격 | 그룹화 기준 | 메타데이터 |
|---|---|---|---|---|---|---|---|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.05 |
flavor_id=<uuid>, flavor_name=m1.large, project=<project_uuid>, resource=<vm_uuid> |
|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.01 |
flavor_id=<uuid>, flavor_name=m1.tiny, project=<project_uuid>, resource=<vm_uuid> |
각 열의 내용을 분석해 보겠습니다.
- 시작/종료: 이 데이터 포인트가 다루는 수집 기간입니다. 기본적으로 CloudKitty는 매시간 데이터를 수집하므로 1시간 단위의 기간이 표시됩니다.
- 메트릭 유형:
metrics.yaml의 메트릭 이름입니다(예:ceilometer_cpu,ceilometer_ip_floating). - 단위:
metrics.yaml에 정의된 청구 단위입니다. - 수량: mutate 또는 factor 변환 후의 원시 수량입니다.
ceilometer_cpu와NUMBOOL의 경우, 인스턴스가 실행 중이었다면 이 값은 1이 됩니다. - 가격: 해시맵 규칙을 적용한 후의 과금 값입니다. 이곳에서 올바른 매핑이 적용되었는지 확인할 수 있습니다.
m1.large를 0.05로 설정했다면 여기에 해당 값이 표시되어야 합니다. - 그룹화 기준:
metrics.yaml의groupby필드에 있는 레이블 값입니다. CloudKitty는 이 방식으로 데이터를 세분화하며, 이를 통해 특정 리소스, 플레이버 또는 프로젝트를 자세히 분석할 수 있습니다. - 메타데이터:
metrics.yaml의 메타데이터 필드를 통해 전달되는 추가 레이블입니다.
이를 통해 운영자는 원시 지표에서 최종 가격까지 전체 경로를 추적할 수 있는 구체적인 도구를 사용할 수 있으므로, 모든 단계에서 CloudKitty의 동작을 투명하게 확인하고 디버깅할 수 있습니다.
비용을 계산할 준비가 되셨나요?
내부 부서로부터의 엄격한 비용 회수나 리소스 소비에 대한 투명한 가시성 제공 등 어떤 목적이든, CloudKitty는 이를 실현하는 데 필요한 체계적이고 신뢰할 수 있는 데이터를 제공합니다. CloudKitty는 원시 OpenStack 텔레메트리와 엔터프라이즈 FinOps 미들웨어 간의 격차를 해소합니다.
이제 프라이빗 클라우드를 “누구나 마음껏 쓰는 뷔페”처럼 사용하는 시대는 끝났습니다. 기능 릴리스 5에서 OpenStack Services on OpenShift 에코시스템에 고도로 맞춤 설정이 가능한 이 네이티브 기능을 제공하게 되어 매우 기쁩니다. 이제는 추측이 아니라 과금의 시대입니다.
시작하기
공식 문서를 참고하여 사용자 환경에서 CloudKitty를 구성하고 관리해 보세요.
실제 작동 모습 보기
동영상 데모를 통해 관리자가 플레이버 기반 과금 규칙을 손쉽게 구성하고 첫 월별 분석 데이터를 추출하는 방법을 확인해 보세요.
이 동영상은 서로 다른 2개의 터미널 세션을 엄선하여 편집한 것입니다. 내부적으로 실행되는 실제 명령을 인터랙티브 방식으로 더 자세히 확인하고 싶다면, 여기에서 편집되지 않은 전체 Asciinema 녹화본을 살펴보세요.
- https://asciinema.org/a/ofDLdVKxHfMAsaNM: CloudKitty를 배포하고 플레이버 기반 과금 규칙을 생성합니다.
- https://asciinema.org/a/P11NR7CEqfiewF4R: 차지백 데이터프레임을 확인하고 월별 요약을 추출합니다.
제품 체험판
Red Hat OpenShift Container Platform | 제품 체험판
저자 소개
Juan Larriba is a software engineer specializing in cloud infrastructure and OpenStack observability. He is a contributor to the OpenStack Kubernetes Operators ecosystem, where he works on the Telemetry Operator — a project that brings together metrics collection, alarming, and rating services like CloudKitty into cloud-native Kubernetes deployments. His work focuses on bridging traditional OpenStack telemetry components with modern container-native architectures, helping operators gain visibility and cost insight into their cloud workloads. Juan is passionate about open source collaboration and has contributed to projects spanning Ceilometer, Aodh, and CloudKitty, with a focus on making rating and chargeback capabilities more accessible in production OpenStack environments.
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래