
Introduction
A couple years ago, a few big companies began to run Spark and Hadoop analytics clusters using shared Ceph object storage to augment and/or replace HDFS.
We set out to find out why they were doing it and how it performs.
Specifically, we in the Red Hat Storage solutions architecture team wanted to know first-hand answers to the following three questions:
- Why would companies do this? (see “Why Spark on Ceph? (Part 1 of 3)”)
- Will mainstream analytics jobs run directly against a Ceph object store? (see “Why Spark on Ceph? (Part 2 of 3)”)
- How much slower will it run than natively on HDFS? (this blog post)
For those wanting more depth, we’ll cross-link to a separate architect-level blog series, providing detailed descriptions, test data, and configuration scenarios, and we recorded this podcast with Intel, in which we talk about our focus on making Spark, Hadoop, and Ceph work better on Intel hardware and helping enterprises scale efficiently.
Findings summary
We did Ceph vs. HDFS testing with a variety of workloads (see blog Part 2 of 3 for general workload descriptions). As expected, the price/performance comparison varied based on a number of factors, summarized below.
Clearly, many factors contribute to overall solution price. As storage capacity is frequently a major component of big data solution price, we chose it as a simple proxy for price in our price/performance comparison.
The primary factor affecting storage capacity price in our comparison was the data durability scheme used. With 3x replication data durability, a customer needs to buy 3PB of raw storage capacity to get 1PB of usable capacity. With erasure coding 4:2 data durability, a customer only needs to buy 1.5PB of raw storage capacity to get 1PB of usable capacity. The primary data durability scheme used by HDFS is 3x replication (support for HDFS erasure coding is emerging, but is still experimental in several distributions). Ceph has supported either erasure coding or 3x replication data durability schemes for years. All Spark-on-Ceph early adopters we worked with are using erasure coding for cost efficiency reasons. As such, most of our tests were run with Ceph erasure coded clusters (we chose EC 4:2). We also ran some tests with Ceph 3x replicated clusters to provide apples-to-apples comparison for those tests.
Using the proxy for relative price noted above, Figure 1 provides an HDFS v. Ceph price/performance summary for the workloads indicated:
 Figure 1: Relative price/performance comparison, based on results from eight different workloads
Figure 1: Relative price/performance comparison, based on results from eight different workloads
Figure 1 depicts price/performance comparisons based on eight different workloads. Each of the eight individual workloads was run with both HDFS and Ceph storage back-ends. The storage capacity price of the Ceph solution relative to the HDFS solution is either the same or 50% less. When the workload was run with Ceph 3x replicated clusters, the storage capacity price is shown as the same as HDFS. When the workload was run with Ceph erasure coded 4:2 clusters, the Ceph storage capacity price is shown as 50% less than HDFS. (See the previous discussion on how data durability schemes affect solution price.)
For example, workload 8 had similar performance with either Ceph or HDFS storage, but the Ceph storage capacity price was 50% of the HDFS storage capacity price, as Ceph was running an erasure coded 4:2 cluster. In other examples, workloads 1 and 2 had similar performance with either Ceph or HDFS storage and also had the same storage capacity price (workloads 1 and 2 were run with a Ceph 3x replicated cluster).
Findings details
A few details are provided here for the workloads tested with both Ceph and HDFS storage, as depicted in Figure 1.
- This workload was a simple test to compare aggregate read throughput via TestDFSIO. As shown in Figure 2, this workload performed comparably between HDFS and Ceph, when Ceph also used 3x replication. When Ceph used erasure coding 4:2, the workload performed better than either HDFS or Ceph 3x for lower numbers of concurrent clients (<300). With more client concurrency, however, the workload performance on Ceph 4:2 dropped due to spindle contention (a single read with erasure coded 4:2 storage requires 4 disk accesses, vs. a single disk access with 3x replicated storage.)
 Figure 2: TestDFSIO read results
Figure 2: TestDFSIO read results
- This workload compared the SparkSQL query performance of a single-user executing a series of queries (the 54 TPC-DS queries, as described blog 2 of 3). As illustrated in Figure 3, the aggregate query time was comparable when running against either HDFS or Ceph 3x replicated storage. The aggregate query time doubled when running against Ceph EC4:2.
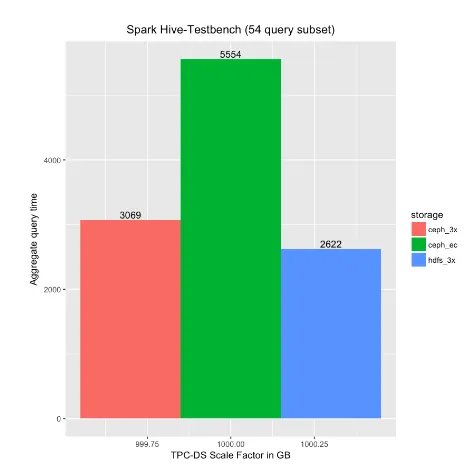 Figure 3: Single-user Spark query set results
Figure 3: Single-user Spark query set results
- This workload compared Impala query performance of 10-users each executing a series of queries concurrently (the 54 TPC-DS queries were executed by each user in a random order). As illustrated in Figure 1, the aggregate execution time of this workload on Ceph EC4:2 was 57% slower compared to HDFS. However, price/performance was nearly comparable, as the HDFS storage capacity costs were 2x those of Ceph EC4:2.
- This mixed workload featured concurrent execution of a single-user running SparkSQL queries (54), 10-users each running Impala queries (54 each), and a data set merge/join job enriching TPC-DS web sales data with synthetic clickstream logs. As illustrated in Figure 1, the aggregate execution time of this mixed workload on Ceph EC4:2 was 48% slower compared to HDFS. However, price/performance was nearly comparable, as the HDFS storage capacity costs were 2x those of Ceph EC4:2.
- This workload was a simple test to compare aggregate write throughput via TestDFSIO. As depicted in Figure 1, this workload performed, on average, 50% slower on Ceph EC4:2 compared to HDFS, across a range of concurrent client/writers. However, price/performance was nearly comparable, as the HDFS storage capacity costs were 2x those of Ceph EC4:2.
- This workload compared SparkSQL query performance of a single-user executing a series of queries (the 54 TPC-DS queries, as described blog 2 of 3). As illustrated in Figure 3, the aggregate query time was comparable when running against either HDFS or Ceph 3x replicated storage. The aggregate query time doubled when running against Ceph EC4:2. However, price/performance was nearly comparable when running against Ceph EC4:2, as the HDFS storage capacity costs were 2x those of Ceph EC4:2.
- This workload featured enrichment (merge/join) of TPC-DS web sales data with synthetic clickstream logs, and then writing the updated web sales data. As depicted in Figure 4, this workload was 37% slower on Ceph EC4:2 compared to HDFS. However, price/performance was favorable for Ceph, as the HDFS storage capacity costs were 2x those of Ceph EC4:2.
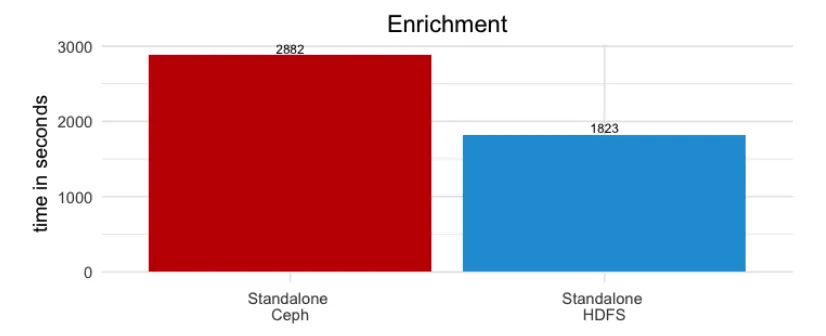 Figure 4: Data set enrichment (merge/join/update) job results
Figure 4: Data set enrichment (merge/join/update) job results
- This workload compared the SparkSQL query performance of 10-users each executing a series of queries concurrently (the 54 TPC-DS queries were executed by each user in a random order). As illustrated in Figure 1, the aggregate execution time of this workload on Ceph EC4:2 was roughly comparable to that of HDFS, despite requiring only 50% the storage capacity costs. Price/performance for this workload thus favors Ceph by 2x. For more insight into this workload performance, see Figure 5. In this box-and-whisker plot, each dot reflects a single SparkSQL query execution time. As each of the 10-users concurrently executes 54 queries, there are 540 dots per series. The three series shown are Ceph EC4:2 (green), Ceph 3x (red), and HDFS 3x (blue). The Ceph EC4:2 box shows comparable median execution times to HDFS 3x, and shows more consistent query times in the middle 2 quartiles.
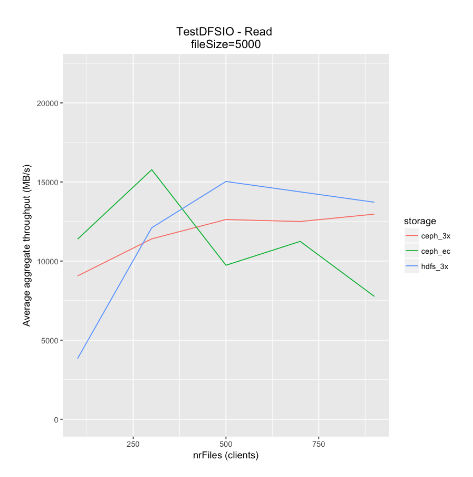
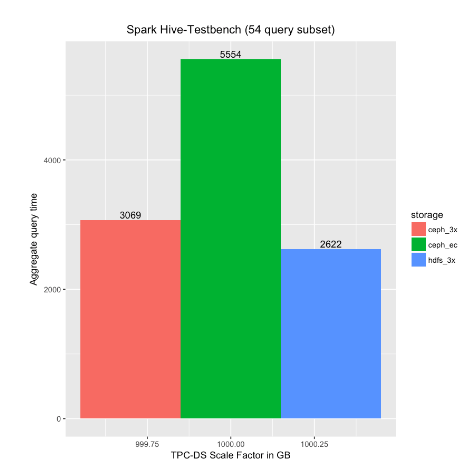
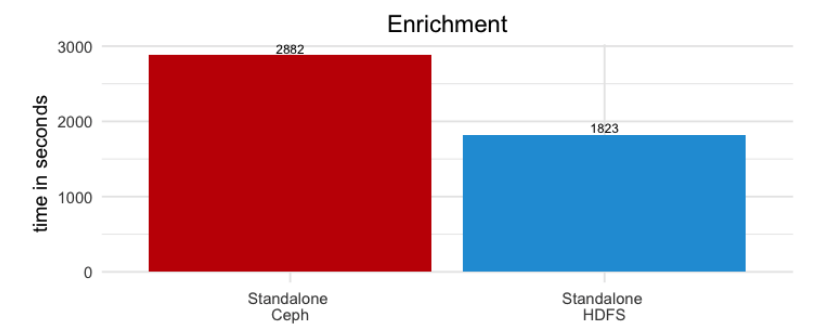
 Figure 5: Multi-user Spark query set results
Figure 5: Multi-user Spark query set results
Bonus results section: 24-hour ingest
One of our prospective Spark-on-Ceph customers recently asked us to illustrate Ceph cluster sustained ingest rate over a 24-hour time period. For these tests, we used variations of the lab as described in blog 2 of 3. As noted in Figure 6, we measured a raw ingest rate of approximately 1.3 PiB per day into a Ceph EC4:2 cluster configured with 700 HDD data drives (Ceph OSDs).
 Figure 6: Daily data ingest rate into Ceph clusters of various sizes
Figure 6: Daily data ingest rate into Ceph clusters of various sizes
Concluding observations
In conclusion, below is our formative cost/benefit analysis of the above results summarizing this blog series.
- Benefits, Spark-on-Ceph vs. Spark on traditional HDFS:
- Reduce CapEx by reducing duplication: Reduce PBs of redundant storage capacity purchased to store duplicate data sets in HDFS silos, when multiple analytics clusters need access to the same data sets.
- Reduce OpEx/risk: Eliminate costs of scripting/scheduling data set copies between HDFS silos, and reduce risk-of-human-error when attempting to maintain consistency between these duplicate data sets on HDFS silos, when multiple analytics clusters need access to the same data sets.
- Accelerate insight from new data science clusters: Reduce time-to-insight when spinning-up new data science clusters by analyzing data in-situ within a shared data repository, as opposed to hydrating (copying data into) a new cluster before beginning analysis.
- Satisfy different tool/version needs of different data teams: While sharing data sets between teams, enable users within each cluster to choose the Spark/Hadoop tool sets and versions appropriate to their jobs, without disrupting users from other teams requiring different tools/versions.
- Right-size CapEx infrastructure costs: Reduce over-provisioning of either compute or storage common with provisioning traditional HDFS clusters, which grow by adding generic nodes (regardless if only more CPU cores or storage capacity is needed), by right-sizing compute needs (vCPU/RAM) independently from storage capacity needs (throughput/TB).
- Reduce CapEx by improving data durability efficiency: Reduce CapEx of storage capacity purchased by up to 50% due to Ceph erasure coding efficiency vs. HDFS default 3x replication.
- Costs, Spark-on-Ceph vs. Spark on traditional HDFS:
- Query performance: Performance of Spark/Impala query jobs ranged from 0%-131% longer execution times (single-user and multi-user concurrency tests).
- Write-job performance: Performance of write-oriented jobs (loading, transformation, enrichment) ranged from 37%-200%+ longer execution times. [Note: Significant improvements in write-job performance are expected when downstream distributions adopt the following upstream enhancements to the Hadoop S3A client HADOOP-13600, HADOOP-13786, HADOOP-12891].
- Mixed-workload Performance: Performance of multiple query and enrichment jobs concurrently executed resulted in 90% longer execution times.
For more details (and a hands-on chance to kick the tires of this solution yourself), stay tuned for the architect-level blog series in this same Red Hat Storage blog location. Thanks for reading.
저자 소개
유사한 검색 결과
자동화 그 이상의 가치: AI 기반 보안 취약점 급증에 따라 기술 전문가의 지원이 필요한 이유
Red Hat Enterprise Linux, 양자 컴퓨팅 시대를 대비한 SSH 보안 역량 강화
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래